Highly Available Transactions: Virtues and Limitations
This is a VLDB 2014 paper from Peter Bailis, Aaron Davidson, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. This is a great paper, because it asked an important question that helped advanced our understanding of isolation properties with respect to high-availability.
So here is the context. As part of his PhD, Peter Bailis started think about the benefits of relaxed consistency guarantees, and how can we leverage them. Peter's Probabilistic Bounded Staleness work is how things started. He also investigated eventual consistency limitations, and bolt-on causal consistency on that front. This paper brings that relaxed guarantees effort from the per-key consistency to the transaction isolation domain, and investigates Highly Available Transactions (HAT).
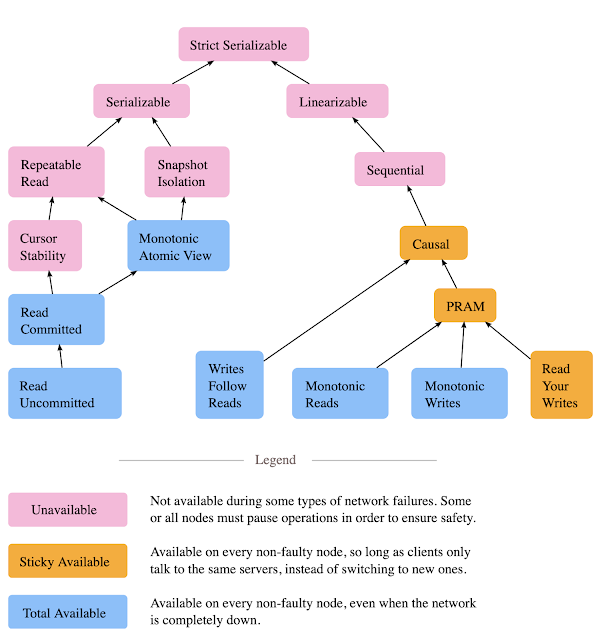

Table 2 is also awesome! It provides an overview of the isolation levels used in databases.

As shown in Table 2, only three out of 18 databases provided serializability by default, and eight did not provide serializability as an option at all. The paper takes the prominence of weaker isolation models as promising for the adoption of HAT transactions. Later Bailis's 2015 paper on feral concurrency control provided more evidence for the adoption of weaker isolation models in practice. (Although, admittedly distributed HAT databases would expose more anomalies than single-site databases that operate under the same isolation because the single-site databases likely provide more consistency and are not prone to multiple asymmetric views of the system that distributed systems suffer.)
The paper then asks the question of whether the limitations of high-availability in weaker isolation model arises from inherent impossibilities or from accidental implementation reasons (such as the use of two-phase locking approaches and dedicated leaders per shards). Following on this question, the papers sets off to investigate which models are HAT-compliant, which forms of the bulk of the internal sections, and culminate at the creation of Figure 2 and Table 3.
The paper also includes an experiments section, where it showcases the performance benefits of HAT transactions. By avoiding cross-replica and cross-datacenter latencies, HAT transactions can get two to three orders of magnitude over wide-area networks. (Somebody should inform Elon to use this to fix "Twitter being slow in many countries".)
The paper got followup from many other influential papers and it keeps getting so. AnnaDB is a direct practical follow up to this paper. RAMP transactions implemented for Facebook TAO is an industrial followup work. DynamoDB GlobalTables is a noteworthy example to point out as a HAT database which provides read-committed isolation with high-availability (HT Marc Brooker). Comment below or write to me about other industrial follow up work you know on HAT.
Now that we understand the main ideas in the paper, we can go through some of the nitty-gritty of the paper.
Systems model and definitions
The paper does not have a dedicated systems model section. This is an important section (often presented as Section 2) to set forth the systems foundations and assumptions. For example the concept of replica availability is very important and forms the foundation of the HATs model, but it comes only as a sentence on the fourth page at the end of Section 4 hidden in a paragraph."We say that a transaction has replica availability if it can contact at least one replica for every item it attempts to access; this may result in “lower availability” than a non-transactional availability requirement (e.g., single-item availability)."
That means, the system assumes that for each object/item, there is at least one replica that the client can connect to at any given time. And the concept of high-availability is built on top of this premise.
"We say that a system provides transactional availability if, given replica availability for every data item in a transaction, the transaction eventually commits (possibly after multiple client retries) or internally aborts. A system provides sticky transactional availability if, given sticky availability, a transaction eventually commits or internally aborts."
That is, if users of a highly available system are able to contact a (set of) server(s) in a system satisfying replica availability, they are guaranteed a response. This means that replicas do not need to synchronously communicate with other replicas maintaining the same object, and in case of a partition, they do not need to stall in order to provide clients a “safe” response to operations. This lack of coordination also means that a highly available system also provides low latency in a wide-area setting.
Stickiness means that a client uses the same server(s) through out a session. "We say that a system provides sticky availability if, whenever a client’s transactions is executed against a copy of database state that reflects all of the client’s prior operations, it eventually receives a response, even in the presence of indefinitely long partitions (where “reflects” is dependent on semantics). A client may choose to become sticky available by acting as a server itself; for example, a client might cache its reads and writes. Any guarantee achievable in a highly available system is achievable in a sticky high availability system but not vice-versa."
Highly available transactions
This section discusses isolation levels that can be achieved with high availability (Read Committed isolation, variants of Repeatable Read, atomic reads, and many ses- sion guarantees) and with sticky availability (read your writes, PRAM and causal consistency). The section also discusses properties that cannot be provided in a HAT system (those preventing Lost Update and Write Skew or guaranteeing recency such as Repeatable Reads, Snapshot Isolation and Serializability).The paper gives a simple recipe for HA Read Committed(RC) transactions. "It is fairly easy for a HAT system to prevent “Dirty Reads”: if each client never writes uncommitted data to shared copies of data, then transactions will never read each others’ dirty data. As a simple solution, clients can buffer their writes until they commit, or, alternatively, can send them to servers, who will not deliver their value to other readers until notified that the writes have been committed. Unlike a lock-based implementation, this implementation does not provide recency or monotonicity guarantees but it satisfies the implementation-agnostic definition."
I thought repeatable reads (RR) would also work. But apparently that is where you draw the line due to cursor stability, and RR (at least not all flavors of RR) is not HA. "Several different properties have been labeled Repeatable Read isolation. [...] some of these are not achievable in a HAT system. However, the ANSI standardized implementation-agnostic definition is achievable and di- rectly captures the spirit of the term: if a transaction reads the same data more than once, it sees the same value each time (preventing “Fuzzy Read”). In this paper, to disambiguate between other definitions of “Repeatable Read,” we will call this property “cut isolation,” since each transaction reads from a non-changing cut, or snapshot, over the data items. If this property holds over reads from discrete data items, we call it Item Cut Isolation, and, if we also expect a cut over predicate-based reads (e.g., SELECT WHERE; preventing Phantoms, or Berenson et al.’s P 3/A3), we have the stronger property of Predicate Cut-Isolation. It is possible to satisfy Item Cut Isolation with high availability by having transactions store a copy of any read data at the client such that the values that they read for each item never changes unless they overwrite it themselves. These stored values can be discarded at the end of each transaction and can alternatively be accomplished on (sticky) replicas via multi-versioning. Predicate Cut Isolation is also achievable in HAT systems via similar caching middleware or multi-versioning that track entire logical ranges of predicates in addition to item based reads."
Finally the paper proposes (and later evaluates) an HA algorithm for Monotonic Atomic View (MAV) isolation. "We begin with our Read Committed algorithm, but replicas wait to reveal new writes to readers until all of thereplicas for the final writes in the transaction have received their respective writes (are pending stable). Clients include additional metadata with each write: a single timestamp for all writes in the transaction (e.g., as in Read Uncommitted) and a list of items written to in the transaction. When a client reads, the return value’s timestamp and list of items form a lower bound on the versions that the client should read for the other items. When a client reads, it attaches a timestamp to its request representing the current lower bound for that item. Replicas use this timestamp to respond with either a write matching the timestamp or a pending stable write with a higher timestamp. Servers keep two sets of writes for each data item: the write with the highest timestamp that is pending stable and a set of writes that are not yet pending stable. This is entirely masterless and operations never block due to replica coordination."
This MAV algorithm trades off maintaining, communication, and tracking (computation) of additional metadata to achieve HA. While this may be acceptable for some cases, there will also be cases/workloads where this is not suitable due to its overheads.

It is good to recall Table 3 and Figure 2 again to summarize the range of isolation levels achievable in HAT systems. The paper highlights two models the authors find particularly compelling. "If we combine all HAT and sticky guarantees, we have transactional, causally consistent snapshot reads (i.e., Causal Transactional Predicate Cut Isolation). If we combine MAV and P-CI, we have transactional snapshot reads. We can achieve RC, MR, and RYW by simply sticking clients to servers. We can also combine unavailable models—for example, an unavailable system might provide PRAM and One-Copy Serializability."
Evaluation
The paper uses TPC-C benchmark to evaluate HAT. TPC-C consists of five transactions, capturing the operation of a wholesale warehouse, including sales, payments, and deliveries. Two transactions (Order-Status and Stock-Level) are read-only and can be executed safely with HATs. Clients may read stale data, but this does not violate TPC-C requirements and clients will read their writes if they are sticky-available. Another transaction type, Payment, updates running balances for warehouses, districts, and customer records and provides an audit trail. The transaction is monotonic—increment- and append-only so all balance increase operations commute, and MAV allows the maintenance of foreign- key integrity constraints (e.g., via UPDATE/DELETE CASCADE). But not all—TPC-C transactions are well served by HATs. The two problematic transactions, New-Order and Payment, rely on non-monotonic state update. The former can be modified to ensure ID uniqueness but not sequential ID ordering, while the latter is inherently non-monotonic, requiring external compensation or stronger consistency protocols.Their prototype database is a partially replicated (hash-based partitioned) key-value backed by LevelDB and implemented in Java using Apache Thrift. It supports eventual consistency (last-writer-wins RU with standard all-to-all anti-entropy between replicas) and the HAT MAV algorithm described earlier. The experiments compare these with a master-based non HA solution.


Discussion
Network partitions do happen as Kingsbury and Bailis surveyed in this article. HAT transactions provide an attractive option for the availability problem under network partitions.
One thing the paper doesn't discuss is the durability in ACID. The paper has two sentences on this topic: "A client requiring that its transactions’ effects survive F server faults requires that the client be able to contact at least F + 1 non- failing replicas before committing. This affects availability and, according to the Gilbert and Lynch definition we have adopted, F > 1 fault tolerance is not achievable with high availability." In the event of a partition, a HAT solution may try writing opportunistically to other nodes in the same region to increase durability. But tracking and integrating these for partition mitigation or recovery is going to be tricky. I think with disaggregated storage solutions, this problem is alleviated these days.
One imperative from the paper is clear though. If you are able to serve your customers by providing an isolation level compatible with HAT transactions, make sure you don't break high availability through unintentional/oblivious implementation decisions and try to reap the benefits of HAT.





Comments