Speedy Transactions in Multicore In-Memory Databases
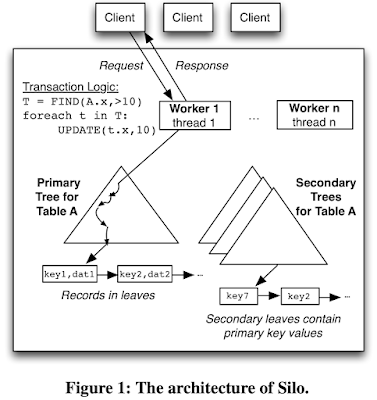
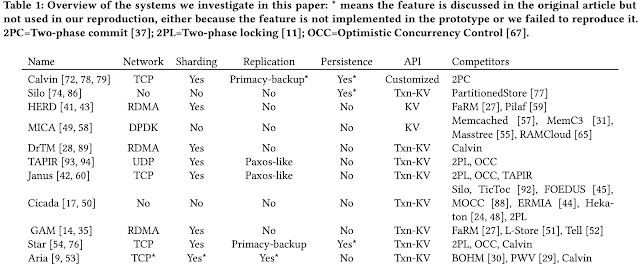
This paper is from SOSP'13. The Polyjuice paper, which we studied last week, built on the Silo codebase and commit protocol, which led me to read the Silo paper. Silo is a single-node multi-core in-memory database. It avoids all centralized contention points, including centralized transaction ID (TID) assignment. Silo's key contribution is a commit protocol based on optimistic concurrency control (OCC) that provides serializability while avoiding all shared-memory writes for records that were only read. Logging and recovery is provided by linking periodically-updated epochs with the commit protocol. Silo achieves almost 700,000 transactions per second on a standard TPC-C workload mix on a 32-core machine, as well as near-linear scalability. That is pretty impressive over 2013 hardware. The Silo paper got 445 citations in 10 years. That is also impressive. So let's dive in. Architecture Silo's organization is typical of databases. Tables are implemented as collections...