Feral Concurrency Control: An Empirical Investigation of Modern Application Integrity
The rise of data-intensive “Web 2.0” Internet services has led to popular new Object-Relational Mapping (ORM) programming frameworks. Rather than adopting the use of traditional transactional programming primitives, the ORM framework developers use feral (application-level) mechanisms for maintaining database integrity. They specify declarative correctness criteria/invariants (through validations and associations) and have the ORM enforce the criteria on their behalf.
This paper (Sigmod 2015) examines the implications of this impedance mismatch between databases and modern ORM frameworks for application integrity. The paper investigates Rails in depth (and also surveys six additional frameworks) to evaluate the effectiveness of these feral mechanisms in practice and to quantify data integrity violations experimentally. Implications of these for database research are discussed at the end.
Ruby on Rails
Rails divides application code into Model-View-Controller architecture. Building a Rails application consists of instantiating models and writing controllers and presentation logic for each.
Using an ORM (Object Relational Mapper) framework means you don't have to manually call the database yourself, the ORM handles it for you. Ruby on Rails uses ActiveRecord for this. Active Record is "an object that wraps a row in a database or view, encapsulates the database access, and adds domain logic on that data".
In Rails, the database is simply a place to store model state and is otherwise divorced from the application logic. All application code is run within the Ruby virtual machine (VM), and Active Record makes appropriate calls to the database to materialize collections of models in the VM memory and to persist model state. Active Record supports PostgreSQL, MySQL, and SQLite and is agnostic to database choice.
When an end-user makes a HTTP request on a Rails-powered web site, the request is first accepted by a web server and passed to a Rails worker process (or thread within the process). Based on the HTTP headers and destination, Rails subsequently determines the appropriate Controller logic and runs it, including any database calls via Active Record, and renders a response via the View, which is returned to the HTTP server.
Feral concurrency control
"I don’t want my database to be clever! I consider stored procedures and constraints vile and reckless destroyers of coherence. No, Mr. Database, you can not have my business logic. Your procedural ambitions will bear no fruit and you'll have to pry that logic from my dead, cold object-oriented hands... I want a single layer of cleverness: My domain model."
---David Heinemeier Hansson (DHH), Rails creator
By shunning decades of work on native database concurrency control solutions, Rails has developed a set of primitives for handling application integrity in the application tier and built a "feral" concurrency control system. The term "feral" is a provocative word, but the paper does not take a condescending view. The paper attempts to understand why these popular frameworks interact with the databases in this way, and how this works in practice. The larger message of the paper is that DBMSs have lots to learn about these web app programming patterns.
Getting back to Rails' concurrency control, Rails provide four main mechanisms:
- Transactions. Database default isolation model is often read committed or repeatable read. Although this can be configured to be serializable, this is often left unchanged.
- Optimistic and pessimistic record locking. Applications invoke pessimistic locks on an Active Record object by calling its lock method, which invokes a SELECT FOR UPDATE statement in the database. Optimistic locking is invoked by declaring a special lock_version field in an Active Record model.
- Application level validations. The framework runs each declared validation sequentially and, if all succeed, the model state is updated in the database; this happens within a database- backed transaction.
- Application level associations. These act like foreign key constraints but are maintained in the application layer.
Among these, the Rails documentation prefers validations as they “are database agnostic, cannot be bypassed by end users, and are convenient to test and maintain.” It looks like efficiency and performance of avoiding serializable transactions is another factor in adopting this approach. But how common are these practices and what are the safety implications of these?
Survey of 67 Rails applications
The paper selected 67 Rails projects with substantial code-bases (average: 26,809 lines of Ruby) multiple contributors (average: 69.1), and relative popularity on GitHub. As shown in Figure 1, these applications overwhelmingly use Rails' built-in support for declarative invariants (validations and associations) to protect data integrity instead of transactions or locks. On average, applications used 0.13 transactions, 0.01 locks, 1.80 validations, and 3.19 associations per model (with an average of 29.1 models per application). While 46 (68.7%) of applications used transactions, all used some validations or associations. Only six applications used locks.

Validations with weak isolation
So validations and associations are very popular, but what about their safety as they are executed using transactions with less than serializable isolation semantics? What is the risk of data corruption due to races between validation and update activity?
To analyze this, the authors employ their previous work on invariant confluence (I-confluence) which provides a necessary and sufficient condition for whether invariants can be preserved under coordination-free, concurrent execution of transactions. In the event that two concurrent controllers save the same model (backed by the same database record), only one will be persisted (a some-write-wins "merge"). In the event that two concurrent controllers save different models (i.e., backed by different database records), both will be persisted (a set-based "merge"). In both cases, we must ensure that validations hold after merge.

They find that, overall, a large number of built-in validations are safe under concurrent operation. Under insertions, 86.9% of built-in validation occurrences as I-confluent. However, the remainder --which include uniqueness violations under insertion and foreign key constraint violations under deletion-- are not. Under deletions, only 36.6% of occurrences are I-confluent.
Quantifying feral anomalies
Depending on the workload, associations and multi-record uniqueness are not I-confluent and are therefore likely to cause problems. But how likely is that?
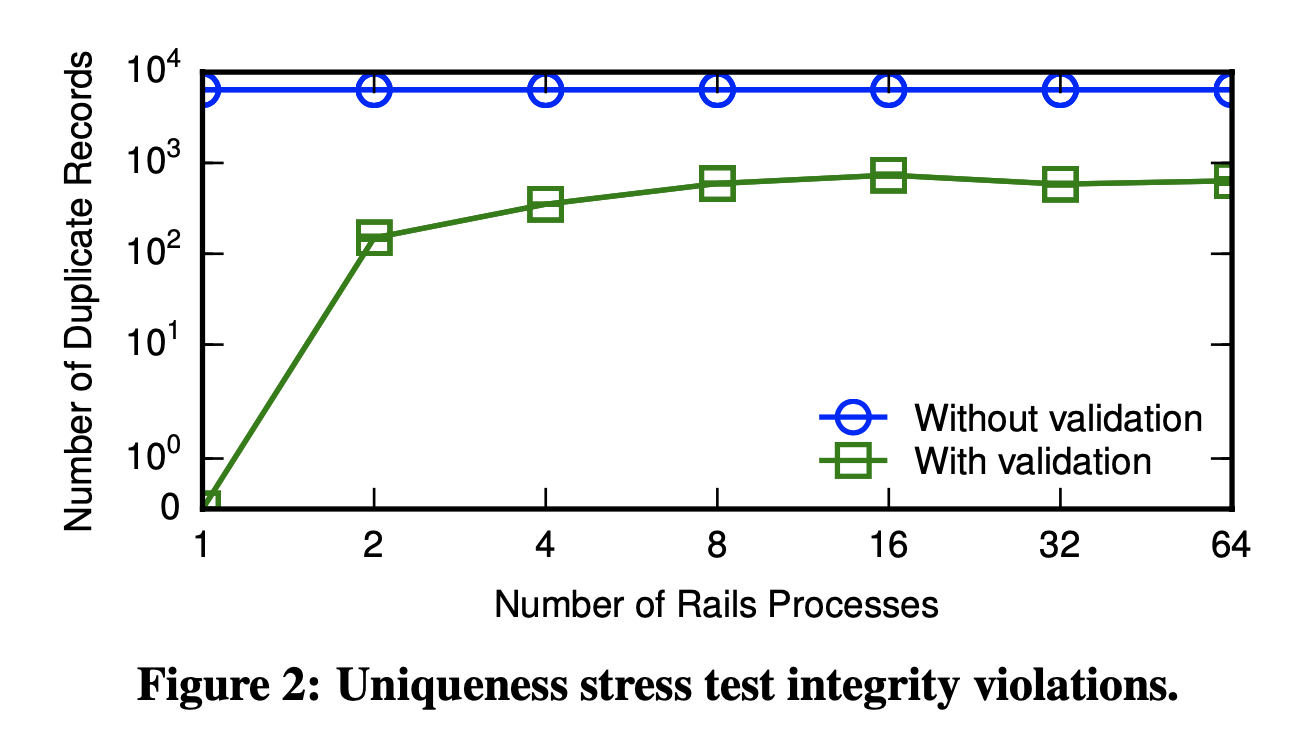

They find that validations reduce the severity of data corruption by orders of magnitude. First, they correctly guard against non-concurrency-related anomalies such as data entry or input errors. For example, if a user attempts to reserve a username that was previously chosen, a validation would succeed. The failures observed are solely due to concurrent execution. Without concurrent execution, validations are correct. Second, validations do reduce the incidence of inconsistency. Empirically, even under worst-case workloads, these validations result in order-of-magnitude reductions in inconsistency. Under less pathological workloads, they may eliminate it. It is possible that, in fact, the degree of concurrency and data contention within Rails-backed applications simply does not lead to these concurrency races, and validations are "good enough" for many applications.
Nevertheless, in both cases, Rails' feral mechanisms are a poor substitute for their respective database counterparts, and still permit serious integrity violations.
Implications for databases research
The paper concludes with a sincere assessment of shortcomings of database capabilities for supporting application developers.
Application developers lack a solution that guarantees correctness while maintaining high performance and programmability. Serializability is too expensive for some applications, is not widely supported, and is not necessary for many application invariants (as evidenced by 86.9% of built-in validation occurrences being I-confluent).
Feral concurrency control is often less expensive and is trivially portable but is not sufficient for many other application invariants. In neither case does the database respect and assist with application programmer desires for a clean, idiomatic means of expressing correctness criteria in domain logic. There is an opportunity and pressing need to build systems that provide all three criteria: performance, correctness, and programmability.
Application users and framework authors need a new database interface that will enable them to:
- Express correctness criteria in the language of their domain model, with minimal friction, while permitting their automatic enforcement.
- Only pay the price of coordination when necessary
- Easily deploy to multiple database backends
This still doesn't solve the workload part of the puzzle, but is an important message in any case.
There is also a nice slide-deck associated with the paper as well.





Comments