TPC-E vs. TPC-C: Characterizing the New TPC-E Benchmark via an I/O Comparison Study
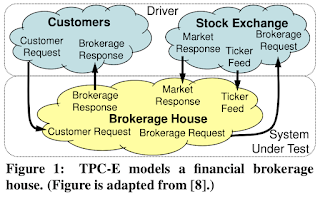
This paper is from Sigmod 2010, and compares the two standard TPC benchmarks for OLTP, TPC-C which came in 1992, and the TPC-E which dropped in 2007. TPC-E is designed to be a more realistic and sophisticated OLTP benchmark than TPC-C by incorporating realistic data skews and referential integrity constraints. However, because of its complexity, TPC-E is more difficult to implement, and hard to provide reproducability of the results by others. As a result adoption had been very slow and little. (I linked TPC-C to its TPC-C wikipedia page above, but poor TPC-E does not even have a Wikipedia page. Instead it has this 1990s style webpage .) A more cynical view on the immense popularity of TPC-C over TPC-E would be that TPC-C can be easily abused to show your database in the best possible light. TPC-C is very easily shardable on the warehouse_id to hide any contention on concurrency control, so your database would be able to display high-scalability. We had recently reviewed the Oce...