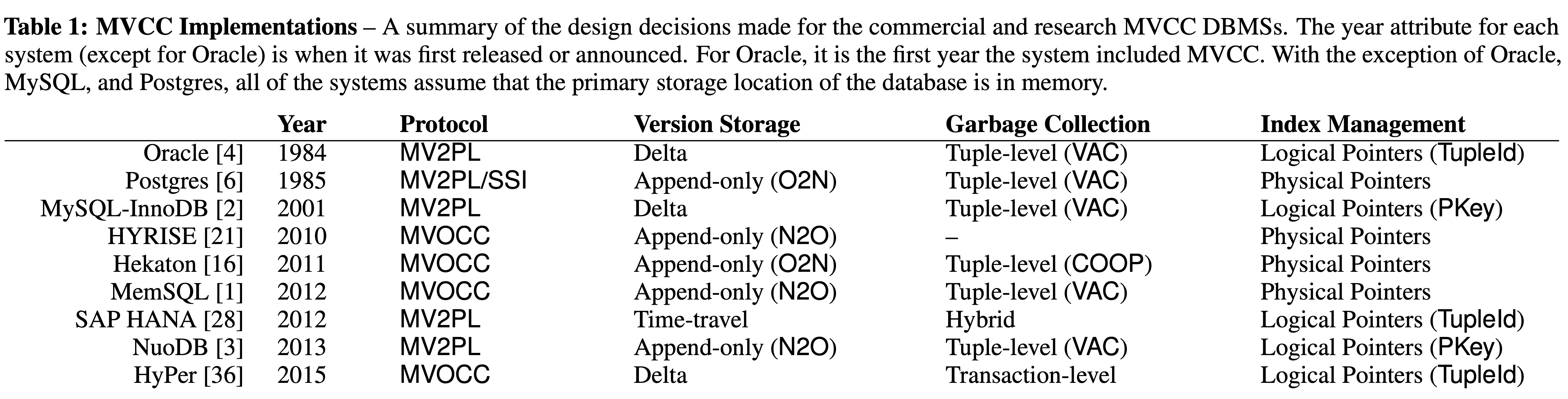
Anna: A Key-Value Store For Any Scale

This paper (ICDE'18) introduces Anna, a CALM / CRDT implementation of a distributed key-value system both at the data structure level as well as system architecture and transaction protocol levels. Anna is a partitioned, multi-mastered key-value system that achieves high performance and elasticity via wait-free execution and coordination-free consistency. Anna employs coordination-free actors that perform state update via merge of lattice-based composite data structures. I love the strongly opinionated introduction of this paper. This is what papers should be about: opinionated, challenging conventions, making bets, and doing hypothesis testing in the small. Conventional wisdom says that software designed for one scale point needs to be rewritten when scaling up by 10x. Anna sets out to disprove this by showing how a key-value storage (KVS) system can be architected to scale across many orders of magnitude. (Spoiler Anna can give you only upto causal consistency, but cannot pro...