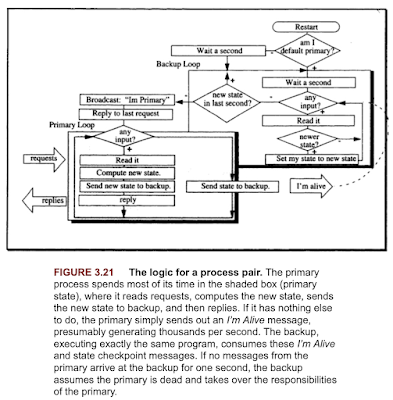
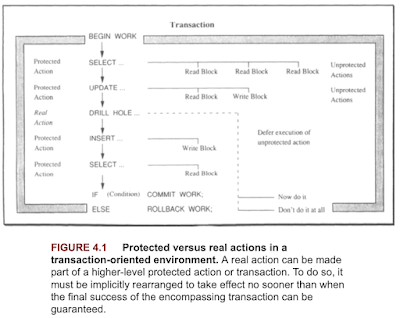
Transaction models (Chapter 4. Transaction processing book)
Atomicity does not mean that something is executed as one instruction at the hardware level with some magic in the circuitry preventing it from being interrupted. Atomicity merely conveys the impression that this is the case, for it has only two outcomes: the specified result or nothing at all, which means in particular that it is free of side effects. Ensuring atomicity becomes trickier as faults and failures are involved. Consider the disk write operation, which comes in four quality levels: Single disk write: when something goes wrong the outcome of the action is neither all nor nothing, but something in between. Read-after write: This implementation of the disk write first issues a single disk write, then rereads the block from disk and compares the result with the original block. If the two are not identical, the sequence of writing and rereading is repeated until the block is successfully written. This has problems due to no abort path, no termination guarantee, and no partial ex...