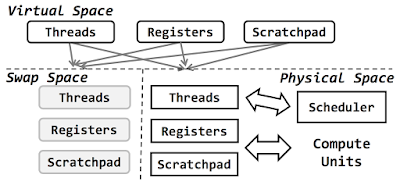
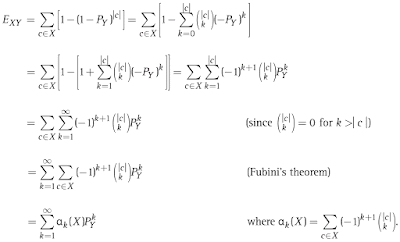A Comparison of Distributed Machine Learning Platforms

This paper surveys the design approaches used in distributed machine learning (ML) platforms and proposes future research directions. This is joint work with my students Kuo Zhang and Salem Alqahtani. We wrote this paper in Fall 2016, and I will be going to ICCCN'17 (Vancouver) to present this paper. ML, and in particular Deep Learning (DL) , has achieved transformative success in speech recognition, image recognition, and natural language processing, and recommendation/search engines recently. These technologies have very promising applications in self-driving cars, digital health systems, CRM, advertising, internet of things, etc. Of course, the money leads/drives the technological progress at an accelerated rate, and we have seen many ML platforms built recently. Due to the huge dataset and model sizes involved in training, the ML platforms are often distributed ML platforms and employ 10s and 100s of workers in parallel to train the models. It is estimated that an overwhel...