Beyond the Code: TLA+ and the Art of Abstraction
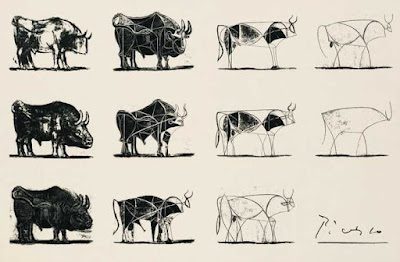
I have been teaching a TLA+ miniseries inside AWS. I just finished the 10th week, with a one hour seminar each week. I wanted to pen down my learnings from this experience. The art of abstraction Let's start with abstraction. Abstraction is a powerful tool for avoiding distraction. The etimology of the word abstract comes from Latin for cut and draw away. With abstraction, you slice out the protocol from a complex system, omit unnecessary details, and simplify a complex system into a useful model. For example, if you are interested in the consistency model of your distributed system, you can abstract away the mechanics of communication in the system when that is an unnecessary distraction. In his 2019 talk, Leslie Lamport said : Abstraction, abstraction, abstraction! That's how you win a Turing Award. Inside Amazon abstraction is also very valuable. We see skilled engineers look at large systems, slice out a protocol/subsystem, cut to the essence of it, and dive deep to make th...







