Paper Summary: High-availability distributed logging with BookKeeper
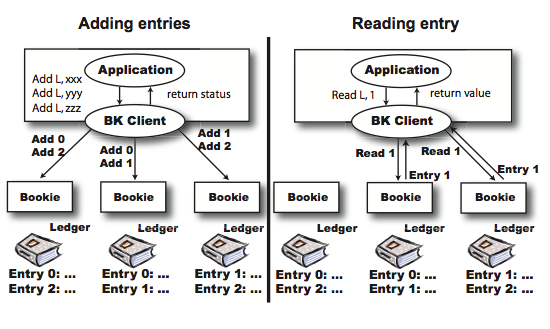
This paper is brought to you by the Yahoo Research group that developed the ZooKeeper, and it appeared in LADIS'12 . BookKeeper targets the logging problem. More specifically, the distributed logging problem where high-availability is important and where many distributed clients are interested in reading the logs. Most current applications log to the local disk, but this constitutes a single point of failure (SPOF) and betrays high-availability. A hasty remedy is to write to an NFS partition to store log files remotely. But now the NFS server becomes the SPOF. (We can of course replicate the NSF server, but the performance would suffer.) Another solution is to use NetApp filers that implement RAID. This costs money, and still does not completely solve SPOF. BookKeeper provides a no-SPOF efficient data store for serving a large number of concurrent single-writer, multiple-reader logs. It stripes log entries across servers, leading to higher throughput. BookKeeper is opensour...