SOSP19 Day 1, machine learning session

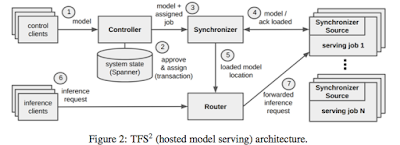
In this post, I cover the papers that appeared in the first session of the conference: machine learning. ( Here is my account of Day 0 and the opening remarks if you are interested.) I haven't read any of these papers yet and I go by my understanding of these papers from their presentations. I might have misunderstood some parts. The good news is all of these papers are available as open access , and I include links to the papers in my notes. Please check the papers when in doubt about my notes. The machine learning session contained four papers. I found all of them very interesting. They applied principled systems design techniques to machine learning and provided results that have broader applicability than a single application. I wanted to enter the machine learning research area three years ago . But I was unsuccessful and concluded that the area is not very amenable for doing principled systems work. It looks like I had admitted defeat prematurely. After seeing these pape...