HotNets'18: Networking in Space
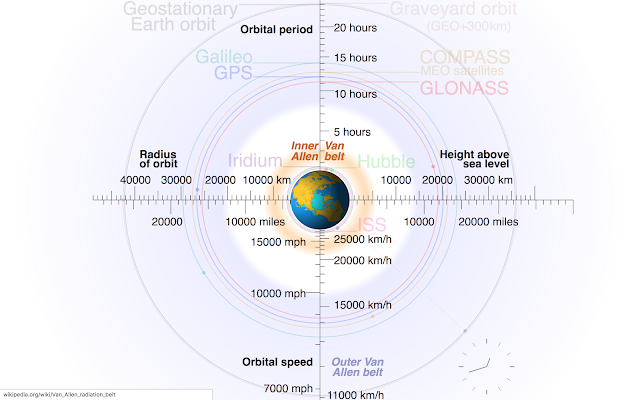
HotNets'18 was held at Microsoft Research, Building 99. This is walking distance to my office at Cosmos DB, where I am working at my sabbatical. So I got tempted and crushed this workshop for a couple sessions. And oh my God, am I happy I did it. The space session was particularly very interesting, and definitely worth writing about. My God, it is full of satellites! According to a 2018 estimate, there are 4,900 satellites in orbit , of which about 1,900 operational, while the rest have lived out their useful lives and become space debris. Approximately 500 operational satellites are in l ow-Earth orbit , 50 are in medium-Earth orbit (at 20,000 km), and the rest are in geostationary orbit (at 36,000 km) . The low earth orbit LEO satellites are not stationary and fast moving around the earth at 1.5 hour per rotation. We are talking about the lowest ring in this picture , where International Space Station (ISS) resides. Since LEO satellites are close to Earth, this make...