New directions in cloud programming

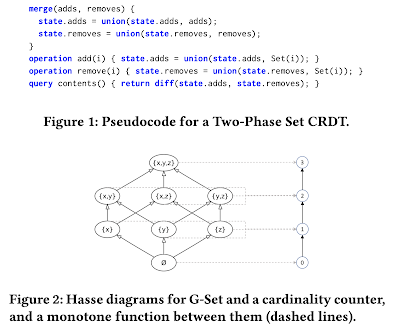
This paper appeared in CIDR'21 . This paper is also on operationalizing CALM theorem, and is a good companion to the CALM-CRDT paper we covered yesterday. The paper starts by pointing out the challenges of cloud programmability. It says that most developers find it hard to harness the enormous potential of the cloud, and that the cloud has yet to provide a programming environment that exposes the inherent power of the platform. The paper then lays out an agenda for providing a new generation of cloud programming environment to programmers in an evolutionary fashion. I would like to start by challenging the claim that the cloud about not yet providing a noteworthy programming environment. I think there are many examples of successful cloud programming paradigms and frameworks that have emerged in the past decade, such as MapReduce, Resilient Distributed Datasets, Hadoop environment, Spark environment, real time data processing and streaming systems, distributed machine learning syst...