Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems
This paper from Sigmod 2015 describes the addition of Multi-Version Concurrency Control (MVCC) to the Hyper database, and discusses at length how they implement serializability efficiently with little overhead compared to snapshot isolation. Coming only two years later, this paper seems like a response/one-up-manship to the Hekaton paper. In the paper, you can see at many places statements like "in constrast to/ unlike/ as in/ Hekaton" phrase. In a way, that is the biggest compliment a paper can pay to another paper.
Hyper is also an in-memory database as in Hekaton. The paper says that Hyper is like Hekaton in that, in order to preserve scan performance, new transactions are not allocated a separate place. The most uptodate version of the database is kept all in the same place. But, you can reach older versions of a record (that are still in use by active transactions) by working backwards from the record using the delta versions maintained.
The biggest improvement in Hyper over Hekaton is the more efficient (tidier?) implementation of multiversion concurrency control, especially for providing serializability with little overhead. The paper is very proud about this implementation and says that "at least from a performance perspective, there is little need to prefer snapshot isolation over full serializability any longer." (See the Discussion at the end of this post about this claim.)
I promise this will make sense to you after you are done reading this summary, but here is a brief summary of Hyper's improvements over Hekaton:
- partial updates improvement to the MVCC model (better undo log maintenance scheme)
- precision locking support for better read-set evaluation in validation phase
- fast scanning support (via versioned positions)
- support for OLAP (via fast scanning) in addition to OLTP, making Hyper an HTAP database
Reminder though, Hyper is a single node implementation like Hekaton. It is a multicore and concurrent implementation, but not a distributed implementation as in shared-nothing across different nodes. It would be nice to think about how these ideas can be extended to a disaggregated shared-nothing implementation.
This is a well written paper, but it is also very dense with ideas. It is hard to boil this down to a concise summary. I will reuse many paragraphs from the paper, and include my commentary in blue-ink distributed across the summary.
Motivation
The paper chooses to motivate by pointing at the gap between serializability and snapshot isolation.
Serializability is a great concept, but it is hard to implement efficiently. A classical way to ensure serializability is to rely on a variant of Two-Phase Locking (2PL). Using 2PL, the DBMS maintains read and write locks to ensure that conflicting transactions are executed in a well-defined order, which results in serializable execution sched- ules. Locking, however, has several major disadvantages: Readers and writers block each other.
In Multi-Version Concurrency Control (MVCC), *read-only transactions* never have to wait, and in fact do not have to use locking at all. This is an extremely desirable property and the reason why many DBMSs implement MVCC, e.g., Oracle, Microsoft SQL Server, SAP HANA, and PostgreSQL.
Aha... Distributed DBMS fall into a different gap here. Even many of the MVCC databases (like Spanner and CockroachDB) still use locks to coordinate across nodes as they find this a more practical/feasible option. Read-write transactions in Spanner suffers from the locking problems mentioned because it implements concurrency control via 2PL+2PC. Spanner treats read-only transactions differently and still achieve nonblocking. The reads of read-only transactions do not acquire any lock, so they never block write operations. CockroachDB also has that feature, and even adds over that: In CockroachDB, reads (even in read-write transactions) don't take locks, only writes take locks.
Unfortunately, most systems that use MVCC do not guarantee serializability, but the weaker isolation level Snapshot Isolation (SI). Under SI, every transaction sees the database in a certain state (typically the last committed state at the beginning of the transaction) and the DBMS ensures that two concurrent transactions do not update the same data object. Although SI offers fairly good isolation, some non-serializable schedules are still allowed. This is often reluctantly accepted because making SI serializable tends to be prohibitively expensive. In particular, the known solutions require keeping track of the entire read set of every transaction, which creates a huge overhead for read- heavy (e.g., analytical) workloads. Still, it is desirable to detect serializability conflicts as they can lead to silent data corruption, which in turn can cause hard-to-detect bugs.
This paper introduces a novel way to implement MVCC that is very fast and efficient, both for SI and for full serializability. The SI implementation is admittedly more carefully engineered than totally new, as MVCC is a well understood approach that recently received renewed interest in the context of main-memory DBMSs. Careful engineering, however, matters as the performance of version maintenance greatly affects transaction and query processing. It is also the basis of the cheap serializability check, which exploits the structure of versioning information. Hyper further retains the very high scan performance of single-version systems using synopses of positions of versioned records in order to efficiently support analytical transactions.
MVCC implementation
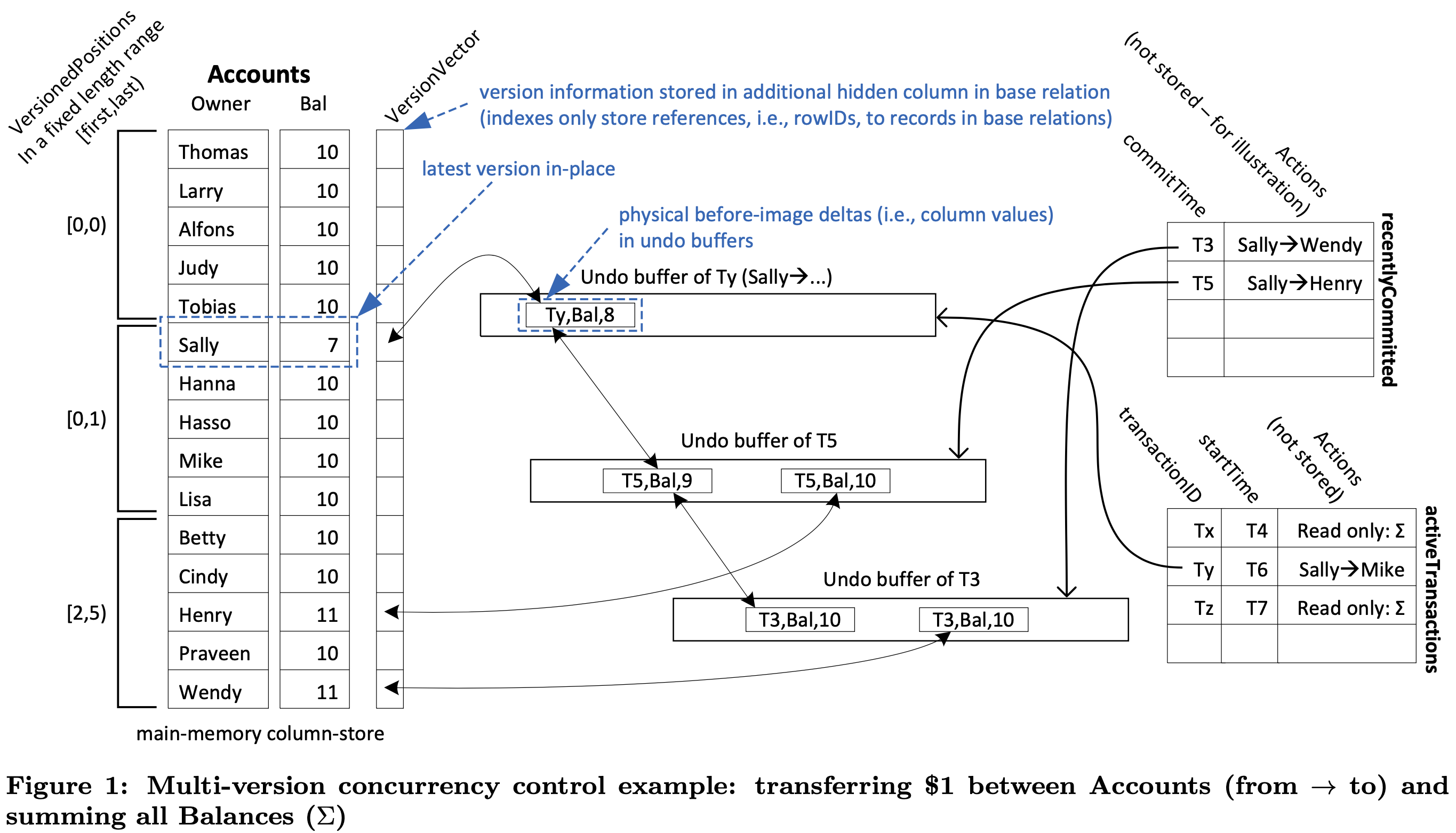
Using the undo buffers for version maintenance, the MVCC model incurs almost no storage overhead as we need to maintain the version deltas (i.e., the before-images of the changes) during transaction processing anyway for transactional rollbacks. The only difference is that the undo buffers are (possibly) maintained for a slightly longer duration, i.e., for as long as an active transaction may still need to access the versions contained in the undo buffer. Thus, the VersionVector shown in Figure 1 anchors a chain of version reconstruction deltas (i.e., column values) in “newest-to-oldest” direction, possibly spanning across undo buffers of different transactions. For garbage collection this chain is maintained bidirectionally, as illustrated for Sally’s Bal-versions.
Figure 1 provides a great (but initially cryptic) overview the system. The figure encompasses the entire Hyper functionality and important data structures used:
- activeTransactions table is used for garbage collection
- recentlyCommitted table is used for precision locking for efficient serializability evaluation
- undo buffer is used for finding and reading from earlier versions, and reverting as needed
- version vectors is used for pointing to the undo buffers
- versioned positions (on the left) is used for achieving fast scanning performance
Version maintenance
Only a tiny fraction of the database will be versioned, as we continuously garbage collect versions that are no longer needed. A version (reconstruction delta) becomes obsolete if all active transactions have started after this delta was timestamped. The VersionVector contains null whenever the corresponding record is unversioned and a pointer to the most recently replaced version in an undo buffer otherwise.
All new transactions entering the system are associated with two timestamps: transactionID and startTime-stamps. Upon commit, update transactions receive a third times- tamp, the commitTime-stamp that determines their serialization order. Initially all transactions are assigned identifiers that are higher than any startTime-stamp of any transaction. We generate startTime-stamps from 0 upwards and transactionIDs from 263 upwards to guarantee that transactionIDs are all higher than the startTimes.
Update transactions modify data in-place. However, they retain the old version of the data in their undo buffer. This old version serves two purposes: (1) it is needed as a before-image in case the transaction is rolled back (undone) and (2) it serves as a committed version that was valid up to now.
At commit time an update transaction receives a commitTime-stamp with which its version deltas (undo logs) are marked as being irrelevant for transactions that start from “now” on. This commitTime-stamp is taken from the same sequence counter that generates the startTime-stamps.
Serializability validation
For update transactions we need a validation phase that (conceptually) verifies that its entire read set did not change during the execution of the transaction. In previous approaches, this task is inherently complex as the read set can be very large, especially for main-memory data- base systems that tend to rely on full-table scans much more frequently than traditional disk-based applications. Fortunately, the authors found a way to limit this validation to the objects that were actually changed and are still available in the undo buffers.
In previous approaches for serializability validation, such as in Microsoft’s Hekaton and PostgreSQL, the entire read set of a transaction needs to be tracked (e.g., by using SIREAD locks as in PostgreSQL) and needs to be re-checked at the end of the transaction --by redoing all the read accesses. This is prohibitively expensive for large read sets that are very typical for scan-heavy main-memory database applications, including analytical transactions. Here, the novel idea of using the undo-buffers for validation comes into play. Thereby, we limit the validation to the number of recently changed and committed data objects, no matter how large the read set of the transaction was. For this purpose, Hyper adapts an old (and largely “forgotten”) technique called Precision Locking that eliminates the inherent satisfiability test problem of predicate locking. This variation of precision locking tests discrete writes (updates, deletions, and insertions of records) of recently committed transactions against predicate-oriented reads of the transaction that is being validated. Thus, a validation fails if such an extensional write intersects with the intensional reads of the transaction under validation.
In order to find the extensional writes of other transactions that committed during the lifetime of a transaction T, we maintain a list of recentlyCommitted transactions, which contains pointers to the corresponding undo buffers (cf., Figure 1). We start our validation with the undo buffers of the oldest transaction that committed after T’s startTime and traverse to the youngest one (at the bottom of the list). Each of the undo buffers is examined as follows: For each newly created version, we check whether it satisfies any of T’s selection predicates. If this is the case, T’s read set is inconsistent because of the detected phantom and it has to be aborted.
After successful validation, a transaction T is committed by first writing its commit into the redo-log (which is required for durability). Thereafter, all of T’s transactionID timestamps are changed to its newly assigned commitTimestamp. Due to our version maintenance in the undo buffers, all these changes are local and therefore very cheap. In case of an abort due to a failed validation, the usual undo-rollback takes place, which also removes the version delta from the version chain. Note that the serializability validation can be performed in parallel by several transactions whose serialization order has been determined by drawing the commitTime-stamps.
Predicate Logging and Predicate/Attribute checking
Instead of the read set, Hyper logs the predicates during the execution of a transaction for serializability validation. Note that, in contrast to Hekaton, HyPer not only allows to access records through an index, but also through a base table scan. Predicates of a base table access are expressed as restrictions on one or more attributes of the table.
Traditional serializable MVCC models detect conflicts at the granularity of records (e.g., by “locking” the record). In this implementation they log the comparison summaries for restricted attributes (predicates), which is sufficient to detect serializability conflicts at the record-level (SR-RL). However, sometimes a record is too coarse. If the sets of read and written attributes of transactions do not overlap, a false positive conflict could be detected. To eliminate these false positives, which would lead to false aborts, they also implemented a way to check for serializability conflicts at the granularity of attributes (SR-AL): in addition to the restricted attributes we further log which attributes are accessed, i.e., read, without a restriction. During validation we then know which attributes were accessed and can thus skip the validation of versions that modified attributes that were not accessed.

Serializability validation works as follows: At the beginning of the validation of a committing transaction, a Predicate Tree (PT) is built on a per-relation basis from the predicate log. PTs are directed trees with a root node P. The PT for the predicate space in Figure 3 is exemplified in Figure 4.

Garbage collection
Garbage collection of undo buffers is continuously performed whenever a transaction commits. After each commit, the MVCC implementation determines the now oldest visible transactionID, i.e., the oldest timestamp of a transaction that has updates that are visible by at least one active transaction. Then, all committed transactions whose transactionID is older than that timestamp are removed from the list of recently committed transactions, the references to their undo buffers are atomically removed from the version lists, and the undo buffers themselves are marked with a tombstone. This is implemented with very little overhead, e.g., by maintaining high water marks.
Efficient scanning
The MVCC implementation in HyPer uses LLVM code generation and just-in-time compilation to generate efficient scan code at runtime. To mitigate the negative performance implications of repeated version branches, the generated code uses synopses of versioned record positions to determine ranges that can be scanned at maximum speed. The generated scan code proceeds under consideration of these synopses, called VersionedPositions, shown on the left- hand side of Figure 1. These synopses maintain the position of the first and the last versioned record for a fixed range of records (e.g., 1024) in a 32 bit integer, where the position of the first versioned record is stored in the high 16 bit and the position of the last versioned record is stored in the low 16 bit, respectively. Note that the versions are continuously garbage collected; therefore, most ranges do not contain any versions at all, which is denoted by an empty interval [x, x).
Synchronization of Data Structures
To guarantee thread-safe synchronization in our implementation, Hyper obtains short-term latches on the MVCC data structures for the duration of one task (a transaction typically consists of multiple such calls). The commit processing of writing transactions is done in a short exclusive critical section by first drawing the commitTime-stamp, validating the transaction, and inserting commit records into the redo log.
Updating the validity timestamps in the undo buffers can be carried out unsynchronized thereafter by using atomic operations. The lock-free garbage collection that continuously reclaims undo log buffers has been detailed. Currently they use conventional latching-based synchronization of index structures, but could adapt to lock-free structures like the Bw-Tree in the future.
In 2018, Andy Pavlo did a follow up study on Bw-trees for the Pelaton database, and wrote this interesting paper: "Building a Bw-Tree takes more than just buzz words."
Serializability theory
An update transaction draws its commitTime-stamp from the same counter that generates the startTime-stamps. The commitTime-stamps determine the commit order and, they also determine the serialization order of the transactions. Read-only transactions do not need to draw a commit order timestamp; they reuse their startTime-stamp. Transactions read all the data in the version that was committed (i.e., created) most recently before their startTime-stamp
Local writing is denoted as w( x ). Such a “dirty” data object is only visible to the transaction that wrote it as it uses the very large transaction identifiers to make the dirty objects invisible to other transactions. As Hyper performs updates in-place, other transactions trying to (over-)write x are aborted and restarted. Note that reading x is always possible, because a transaction’s reads are directed to the version of x that was committed most recently before the transaction’s startTime-stamp
The benefits of MVCC are illustrated in Figure 6(b), where transaction (S5 , T6) managed to “slip in front” of transaction (S4, T7) even though it read x after (S4, T7) wrote x. Obviously, with a single-version scheduler this degree of logical concurrency would not have been possible. The figure also illustrates the benefits of the MVCC scheme that keeps an arbitrary number of versions. The “long” read transaction (S1 , T1 ) needs to access x0 even though in the meantime the two newer versions x3 and x7 were created. Versions are only garbage collected after they are definitely no longer needed by other active transactions.

Evaluation
This section evaluates the MVCC implementation in HyPer main-memory database system that supports SQL-92 queries and ACID-compliant transaction processing (defined in a PL/SQL-like scripting language). For queries and transactions, HyPer generates LLVM code that is then just-in-time compiled to optimized machine code. HyPer supports both, column- and a row-based storage of relations. Unless otherwise noted, we used the column-store backend, enabled continuous garbage collection, and stored the redo log in local memory.
They implemented a benchmark similar to the SIBENCH benchmark and the bank accounts example (cf., Figure 1). The benchmark operates on a single relation that contains integer (key, value) pairs. The workload consists of update transactions which modify a (key, value) pair by incrementing the value and a scan transaction that scans the relation to sum up the values. Figure 7 shows the per-core performance of scan trans- actions on a relation with 100M (key, value) records. To demonstrate the effect of scanning versioned records, we disable the continuous garbage collection and perform updates before scanning the relations. We vary both, the number of dirty records and the number of versions per dirty record. Additionally, we distinguish two cases: (i) the scan transaction is started before the updates (scan oldest) and thus needs to undo the effects of the update transactions and (ii) the scan transaction is started after the updates (scan newest) and thus only needs to verify that the dirty records are visible to the scan transaction. For all cases, the results show that our MVCC implementation sustains the high scan throughput of our single-version concurrency control implementation for realistic numbers of dirty records; and even under high contention with multiple versions per record.
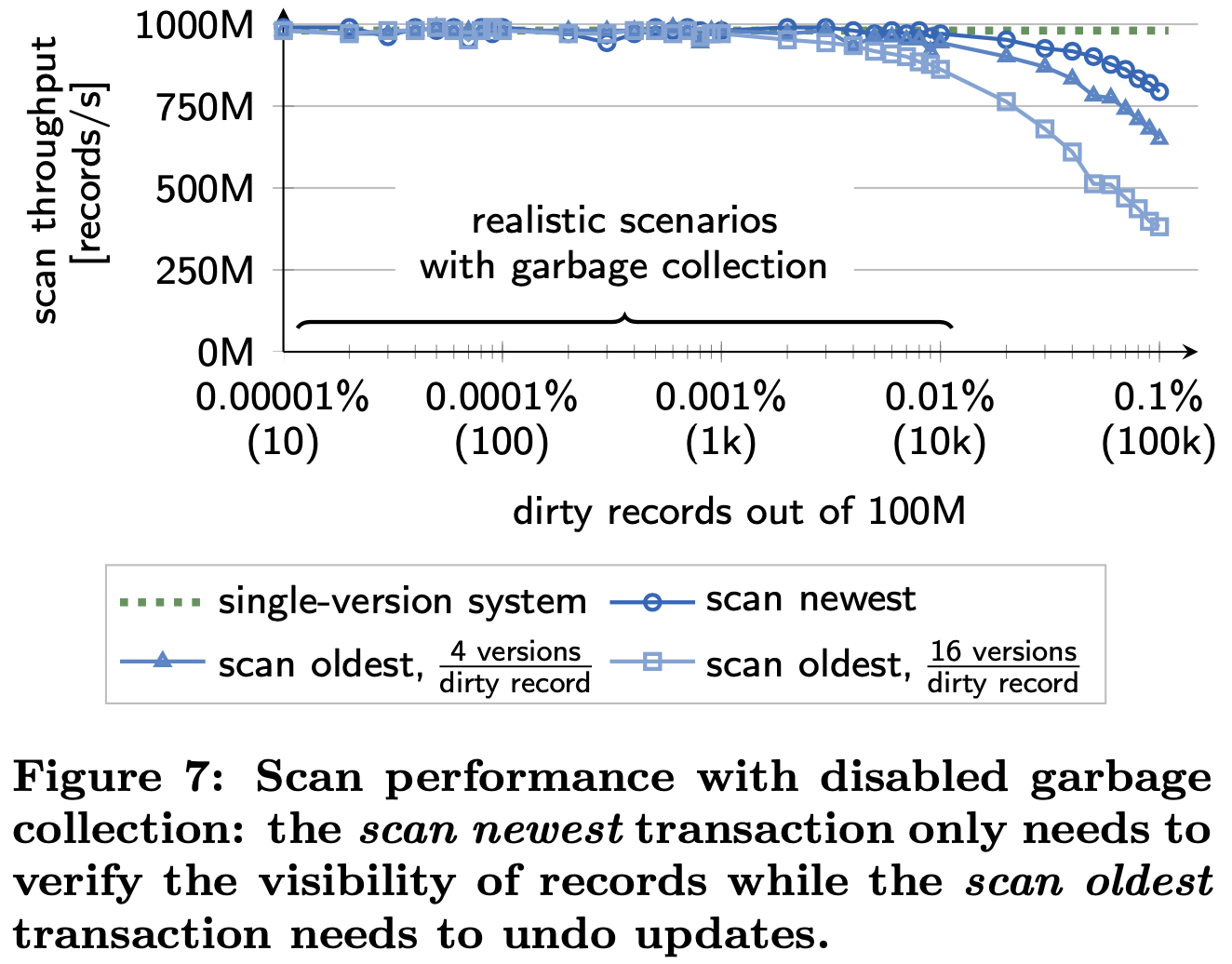
Figure 8 shows the performance effect of having Versioned- Positions synopses on scan performance. Our implementation maintains VersionedPositions per 1024 records. The experiment suggests that increasing or decreasing the number of records per VersionedPositions degrades scan performance. Compared to not using VersionedPositions at all, scan performance is improved by more than 5.5×. 1024 records seems to be a sweetspot where the size of the VersionedPositions vector is still reasonable and the synopses already encode meaningful ranges, i.e., ranges that include mostly modified records.



Summary
The main contributions of this paper were:
- A novel MVCC implementation that is integrated into Hyper's hybrid OLTP and OLAP main memory database system. The MVCC model creates very little overhead for both transactional and analytical workloads and thereby enables very fast and efficient logical transaction isolation for hybrid systems that support these workloads simultaneously.
- Based upon that, a novel approach to guarantee serializability for snapshot isolation (SI) that is both precise and cheap in terms of additional space consumption and validation time. This approach is based on an adaptation of Precision Locking and does not require explicit read locks, but still allows for more concurrency than 2PL.
- A synopses-based approach (VersionedPositions) to retain the high scan performance of single-version systems for read-heavy and analytical transactions, which are common in today’s workloads.
- Extensive experiments that demonstrate the high performance and trade-offs of the MVCC implementation.
Discussion
The Hyper paper has this powerful quote: "at least from a performance perspective, there is little need to prefer snapshot isolation over full serializability any longer."
But performance concern is only one aspect of this choice. I asked this question to database veterans, who have been practicing databases with customer-facing large-scale deployments.
I got an unexpected response. The consensus from them is that many developers would not switch to serializability isolation level *even if it is provided at the same cost and performance with snapshot isolation.* And this would be due to the programmer aspect of dealing with serializability.
Wait?! Isn't serializable isolation (after strict serializability) the best you can provide for correctness and surprise avoidance. Wouldn't serializability be an upgrade from the developer's perspective? It avoids the write-skew problem that snapshot isolation has. What would be the surprise/anomaly to the developers here?
Yes, serializability may be better in the correctness direction, but it turns out it causes a lot of problems with developers because they are surprised to find out their transactions running in serializable mode fail to make forward progress. They get stuck, especially when using serializability with MVCC and OCC. At validation time, they find that the transaction gets canceled because they were trying to update many things at one time. In some high workload scenarios (and especially in the presence of long running read transactions) the false positive rates and abort rates spike. Developers find they are not able to make forward progress with their transactions (despite trying again and again optimistically) when somebody (or some other transaction) changes something. Often they will then resort to taking a pessimistic lock to get things making progress.
So the experts I talked to think many developers wouldn't do the "upgrade" to serializability even if it comes with the same performance/cost. "Database papers are less customer centric in a lot of ways. They are in the technical domain and miss the fact that the business needs are different."
I had asked this question in my Hekaton review and wrote this paragraph then, which is equally applicable here:
Among the single-node multi-core users of SQLServer/Hekaton, what is the percentage of snapshot-isolation use versus serializability use?
Related data point. Andy Pavlo gave a Sigmod 17 talk called "WHAT ARE WE DOING WITH OUR LIVES? Nobody Cares About Our Concurrency Control Research" with some survey results about how people actually use transactions and isolation levels. "We commissioned a survey of DBAs in April 2017 on how applications use databases. 50 responses for 79 DBMS installations. What isolation level do transactions execute at on this DBMS? The result was overwhelmingly Read Committed."





Comments