Hekaton: SQL Server’s Memory-Optimized OLTP Engine
This paper (Sigmod 2013) gives an overview of the design of the Hekaton engine which is optimized for memory resident data and OLTP workloads and is fully integrated into Microsoft SQL Server.
The paper starts with a strongly opinionated paragraph:
SQL Server and other major database management systems were designed assuming that main memory is expensive and data resides on disk. This assumption is no longer valid; over the last 30 years memory prices have dropped by a factor of 10 every 5 years. Today, one can buy a server with 32 cores and 1TB of memory for about $50K and both core counts and memory sizes are still increasing. The majority of OLTP databases fit entirely in 1TB and even the largest OLTP databases can keep the active working set in memory.I really like this paper. The paper is self-contained and is easy to follow. It is very well written. It has the old-school touch: it is succinct and opinionated, it explains principles/tenets behind design, and it does not oversell. (My commentary is in blue-ink distributed across the summary.)
Overview
Hekaton is a database engine optimized for memory resident data. A Hekaton table is stored entirely in main memory and can have several indexes of either hash or range index types.
Hekaton is designed for high levels of concurrency but does not rely on partitioning to achieve this. Any thread can access any row in a table without acquiring latches/locks. Hekaton uses latch/lock-free data structures to avoid physical interference among threads. It also uses a new optimistic, multiversion concurrency control (MVCC) technique to avoid interference among transactions.
Hekaton tables are accessed using T-SQL. Further performance improvements are achieved by compiling T-SQL stored procedures that reference only in-memory/Hekaton tables into machine code.
It would be nice, if the paper could have provided some information/background on the Microsoft SQL server. It becomes apparent later that Hekaton and SQLServer target single-node multiple-core deployments. But it would help to state this earlier in the introduction.
I also wish that they gave the isolation level discussion earlier on. That could have saved me some headscratching. They provide snapshot isolation by default, and can go to serializable isolation by building on the snapshot isolation protocol.
Design considerations
Based on their analysis/calculation (relegated to the appendix), the authors conclude that, *in a single node* the only real hope for improving throughput is to reduce the number of instructions executed. But this reduction needs to be dramatic. To go 10X faster, the engine must execute 90% fewer instructions. This level of improvement requires a much more efficient way to store and process data. Yes, we are talking about main memory storage/execution!
Optimize indexes for main memory
Database systems that use disk-oriented storage structures need to bring data from disk-pages into memory as needed. This requires a complex buffer pool where a page must be protected by latching/locking before it can be accessed. A simple key lookup in a B-tree index may require thousands of instructions even when all pages are in memory. To cut this out, Hekaton indexes are designed and optimized for memory-resident data.
Eliminate latches and locks
In multi-core systems, scalability (hence throughput) suffers when there are shared memory locations that are updated at high rate: e.g., latches and spinlocks and highly contended resources such as the lock manager, the tail of the transaction log, or the last page of a B-tree index. All Hekaton's internal data structures (memory allocators, hash and range indexes, and transaction map) are entirely latch-free. Moreover, Hekaton uses an optimistic multiversion concurrency control protocol to provide transaction isolation semantics, which avoids locks and lock tables.
No partitioning
Partitioning improves scalability but only if the workload is also partitionable. If transactions touch several partitions, performance deteriorates quickly. The overhead of coordinating request/responses is much higher than just performing a lookup in a hash table for all items. In a non-partitioned system, a thread would simply do the lookup itself in a single shared hash table. This is certainly faster and more efficient than coordinating on partition# of requests/lookups.
Compile requests to native code
Hekaton maximizes run time performance by converting statements and stored procedures written in T-SQL into customized, highly efficient machine code.
High level architecture
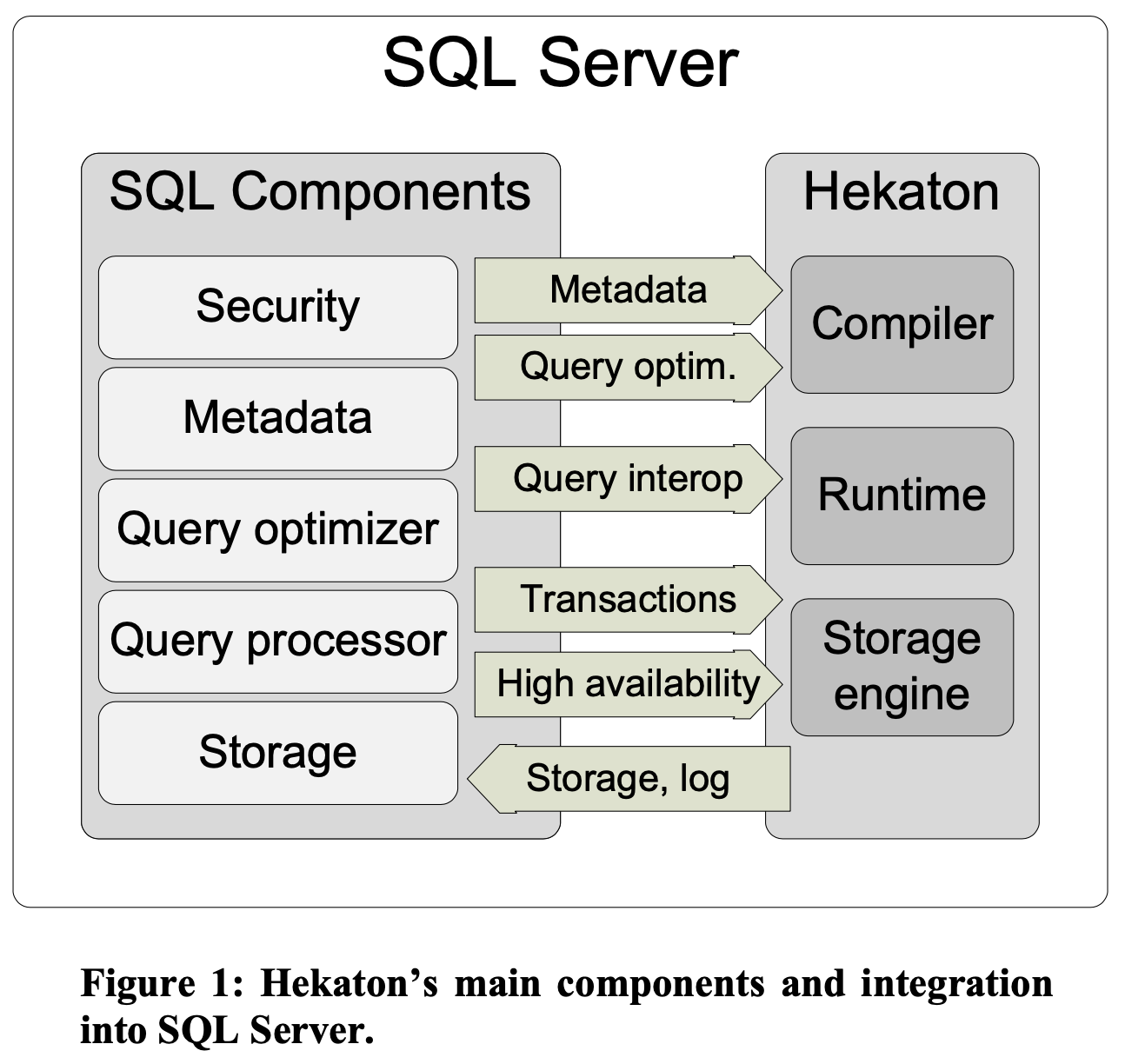
The Hekaton storage engine manages user data and indexes. It provides transactional operations on tables of records, hash and range indexes on the tables, and base mechanisms for storage, checkpointing, recovery and high-availability.
The Hekaton compiler takes an abstract tree representation of a T-SQL stored procedure, including the queries within it, plus table and index metadata and compiles the procedure into native code designed to execute against tables and indexes managed by the Hekaton storage engine.
The Hekaton runtime system is a relatively small component that provides integration with SQL Server resources and serves as a common library of additional functionality needed by compiled stored procedures.
In this review, I will focus on storage engine and transactions built on top. I will not cover programmability/query processing and garbage collection.
Storage and indexing
Hekaton supports two types of indexes: hash indexes which are implemented using lock-free hash tables and range indexes which are implemented using Bw-trees, a novel lock-free version of B-trees.
In 2018, Andy Pavlo did a follow up study on Bw-trees for the Pelaton database, and wrote this interesting paper: "Building a Bw-Tree takes more than just buzz words."

A table can have multiple indexes. Records are always accessed via an index lookup. Hekaton uses multiversioning; an update always creates a new version.
Figure 2 shows a simple bank account table containing six version records. The example table has three columns: Name, City and Amount. It has two indexes; a hash index on Name and a range index on City. A version record includes a header and a number of link (pointer) fields. The first link field is reserved for the Name index and the second link field for the City index.
A version's valid time is defined by timestamps stored in the Begin and End fields in the header. Hash bucket J contains four records: three versions for John and one version for Jane. Jane’s single version (Jane, Paris, 150) has a valid time from 15 to infinity meaning that it was created by a transaction that committed at time 15 and it is still valid. John’s oldest version (John, London, 100) was valid from time 10 to time 20 when it was updated. The update created a new version (John, London, 110).
A transaction Id stored in the End field prevents other transactions from updating the same version and it also identifies which transaction is updating the version. This doesn't forbid a transaction B to read from that record even for serializable isolation: maybe the pending transaction gets aborted, and txnB gets OK on validation time.
A transaction Id stored in the Begin field informs readers that the version may not yet be committed and identifies which transaction created the version. Again, this doesn't forbid a transaction C to read from this pending transaction record. In this case C takes a dependency on this pending transaction, and cannot commit before that pending transaction commits. C will get aborted if that transaction aborts, so cascading aborts are possible.
Here is how transaction 75 transfers $20 from Larry’s account to John's account. Suppose transaction 75 commits with end timestamp 100. After committing, transaction 75 returns to the old and new versions and sets the Begin and End fields, respectively, to 100. The final values are shown in red below the old and new versions. The old version (John, London, 110) now has the valid time 20 to 100 and the new version (John, London, 130) has a valid time from 100 to infinity. Larry’s record is updated in the same way.
This example also illustrates how deletes and inserts are handled because an update is equivalent to a deleting an old version and inserting a new version. The system must discard obsolete versions that are no longer needed to avoid filling up memory. A version can be discarded when it is no longer visible to any active transaction. Garbage collection is nonblocking and is handled cooperatively by all worker threads.
Transaction Management
Hekaton utilizes optimistic multiversion concurrency control (MVCC) to provide snapshot, repeatable read, and serializable transaction isolation without locking.
This paper had the best explanation/framing I have heard of Snapshot Isolation versus Serializability. Seeing these two related this way, and seeing how serializability can be built leveraging snapshot isolation, was a great Aha! moment for me.
A transaction is serializable if its reads and writes logically occur as of the same time. The simplest and most widely used MVCC method is snapshot isolation (SI). SI does not guarantee serializability because reads and writes logically occur at different times: reads at the beginning of the transaction and writes at the end. However, a transaction is serializable if we can guarantee that it would see exactly the same data if all its reads were repeated at the end of the transaction.
To ensure that a transaction T is serializable we must ensure:
- Read stability. If T reads some version V1 during its processing, we must ensure that V1 is still the version visible to T as of the end of the transaction. This is implemented by validating that V1 has not been updated before T commits. This ensures that nothing has disappeared from the view.
- Phantom avoidance. We must also ensure that the transaction’s scans would not return additional new versions. This is implemented by rescanning to check for new versions before commit. This ensures that nothing has been added to the view.
Lower isolation levels are easier to support. For repeatable read, we only need to guarantee read stability. The discussion that follows covers only serializable transactions.
The validation phase begins with the transaction obtaining an end timestamp. This end timestamp determines the position of the transaction within the transaction serialization history. To validate its reads, the transaction checks that the versions it read are visible as of the transaction’s end time. To check for phantoms, it repeats all its index scans looking for versions that have become visible since the transaction began. To enable validation each transaction maintains a read set, a list of pointers to the versions it has read, and a scan set containing information needed to repeat scans. While validation may sound expensive, keep in mind that most likely the versions visited during validation remain in the L1 or L2 cache.
Any transaction T1 that begins while a transaction T2 is in the validation phase becomes dependent on T2 if it attempts to read a version created by T2 or ignores a version deleted by T2. In that case T1 has two choices: block until T2 either commits or aborts, or proceed and take a commit dependency on T2. To preserve the nonblocking nature of Hekaton, T1 takes a commit dependency on T2. This means that T1 is allowed to commit only if T2 commits. If T2 aborts, T1 must also abort so cascading aborts are possible. Commit dependencies introduce two problems though: 1) a transaction cannot commit until every transaction upon which it is dependent has committed and 2) since commit dependencies imply working with uncommitted data, such data should be protected and should not be exposed to users.
Transaction durability
Durability is ensured by logging and checkpointing records to external storage; index operations are not logged. During recovery Hekaton tables and their indexes are rebuilt entirely from the latest checkpoint and logs.
Log streams are stored in the regular SQL Server transaction log. Checkpoint streams are stored in SQL Server file streams (which in essence are sequential files fully managed by SQL Server). The log contains the logical effects of committed transactions sufficient to redo the transaction. Checkpoints are in effect a compressed representation of the log. Checkpoints allow the log to be truncated and improve crash recovery performance.
Generating a log record only at transaction commit time is possible because Hekaton does not use write-ahead logging (WAL) to force log changes to durable storage before dirty data. Dirty data is never written to durable storage.
Experimental results
CPU efficiency
The experiments in this section were run on a workstation with a 2.67GHz Intel Xeon W3520 processor, 6 GB of memory and an 8 MB L2 cache. (Hardware came a long way since 2013!) The experiments use two identical tables, T1 and T2, with schema (c1 int, c2 int, c3 varchar(32)), each containing 1M rows. Column c1 is the primary key. T1 is a Hekaton table with a hash index on c1 and T2 is a regular table with a B-tree index on c1. Both tables reside entirely in memory.


Scaling Under Contention
Scalability of database systems is often limited by contention on locks and latches. The system is simply not able to take advantage of additional processor cores so throughput levels off or even decreases. When SQL Server customers experience scalability limitations, the root cause is frequently contention.
This experiment was run on a machine with 2 sockets, 12 cores (Xeon X5650, 2.67GHz), 144GB of memory, and Gigabit Ethernet network cards. External storage consisted of four 64GB Intel SSDs for data and three 80GB Fusion-IO SSDs for logs.

Figure 7 shows the throughput as the number of cores used varies. The regular SQL Server engine shows limited scalability as we increase the number of cores used. Going from 2 core to 12 cores throughput increases from 984 to 2,312 transactions per second, only 2.3X. Latch contention limits the CPU utilization to just 40% for more than 6 cores.
Converting the table to a Hekaton table and accessing it through interop already improves throughput to 7,709 transactions per second for 12 cores, a 3.3X increase over plain SQL Server. Accessing the table through compiled stored procedures improves throughput further to 36,375 transactions per second at 12 cores, a total increase of 15.7X.
The Hekaton engine shows excellent scaling. Going from 2 to 12 cores, throughput improves by 5.1X for the interop case (1,518 to 7,709 transactions per second). If the stored procedures are compiled, throughput also improves by 5.1X (7,078 to 36,375 transactions per second).
In order to test what the performance of the regular SQL Server engine would be if there were no contention, they partitioned the database and rewrote the stored procedure so that different transactions did not interfere with each other. The results are shown in the row labeled “SQL with no contention”. Removing contention increased maximum throughput to 5,834 transaction/sec which is still lower than the throughput achieved through interop. Removing contention improved scaling significantly from 2.3X to 5.1X going from 2 cores to 12 cores.
MAD questions
Is Hekaton the first database to observe the main-memory trick for SQL databases? Was the use of main-memory techniques in NoSQL databases an inspiration?
What was Hekaton's impact on later databases?
Among the single-node multi-core users of SQLServer/Hekaton, what is the percentage of snapshot-isolation use versus serializability use?
Related data point. Andy Pavlo gave a Sigmod 17 talk called "WHAT ARE WE DOING WITH OUR LIVES? Nobody Cares About Our Concurrency Control Research" with some survey results about how people actually use transactions and isolation levels. "We commissioned a survey of DBAs in April 2017 on how applications use databases. 50 responses for 79 DBMS installations. What isolation level do transactions execute at on this DBMS? The result was overwhelmingly Read Committed."
Ok, so, SQL is Turing-complete. "Turing completeness in declarative SQL is implemented through recursive common table expressions. Unsurprisingly, procedural extensions to SQL (PLSQL, etc.) are also Turing-complete. This illustrates one reason why relatively powerful non-Turing-complete languages are rare: the more powerful the language is initially, the more complex are the tasks to which it is applied and the sooner its lack of completeness becomes perceived as a drawback, encouraging its extension until it is Turing-complete."
Does this make read-stability and phantom-avoidance very hard?
Main memory sizes grows fast, yes, but data sizes also grow fast. But again, you can add more nodes and keep all the data in main-memory. Except for cost (which is a big factor to handwave away), is there a good technical argument for not using main-memory databases? For cool/cold data for which when requests arrive they have good access locality, disk-based systems still make sense, no?
When is it feasible to go multi-node? Do coordination costs in multi-node systems eat gains for non-local workloads? But can't you relocate to improve locality?
Can't you change the coordination mechanism to reduce contention? Coordination does not need to be synonymous with contention. My favorite example is chain replication. By changing the communication patterns, it is possible to isolate contention/consensus out of the data-path.
We have found that the idea of overlaying slightly different communication pattern over Paxos (which is safe in any case being oblivious to the communication pattern used) is an idea that keeps on giving. In previous work, we had also used this successfully several times, including the PigPaxos paper and Compartmentalized Paxos paper. It seems like there is always a way to isolate contention, when you identify where it is.
Snapshot isolation and blind-writes
In one place the paper says: "For snapshot isolation or read committed, no validation at all is required." In another place it says: "Repeatable read requires only read validation and snapshot isolation and read committed require not validation at all."
But what about blind-writes? For snapshot isolation, shouldn't a read-write transaction check that a new version has not been written by a blind write on its writeset? This is required for the no-conflict condition for snapshot isolation.
It is possible that this paper may be talking about a weaker definition/flavor of snapshot isolation where the no-conflict condition is not checked.
Strict-serializability question
The paper defines commit/end time for a transaction as follows. "Every transaction that modifies data commits at a distinct point in time called the commit or end timestamp of the transaction. The commit time determines a transaction’s position in the serialization history."
This gives commit time as a single point and not as an interval. If this is exposed to the user, can this mean serializability would imply strict-serializability for Hekaton? Hekaton being a single node database that uses monotonic timestamp for commit time, does it forbid the causal reverse problem?





Comments
Public cloud vendors probably have much better insight on this since they host so many workloads.