CockroachDB: The Resilient Geo-Distributed SQL Database
This paper appeared in Sigmod 2020. Here is a link to the 10 minute, but extremely useful, Sigmod presentation. There is also a 1 hour extended presentation.
CockroachDB is open source available via GitHub. The core features of the database are under a Business Source License (BSL), which converts to a fully open-source Apache 2.0 license after three years.
Storage layer
CockroachDB (or CRDB for short) consists of a distributed SQL layer on top of a distributed key-value store. The key value store is laid out in a single monolithic ordered key space. The logical key space is physically realized by dividing it into contiguous ranges of keys which we call ranges. Ranges are about 64 megabytes in size. Ranges start empty, grow, and split when they get too large, and merge with their neighbors when they get too small. The ranges are sorted, and I will talk about why in the SQL discussion later.
As we will discuss soon, CRDB uses multi-version concurrency control. Hybrid logical clocks timestamping is used for versioning. The values are never updated in place. Tombstones are used for deletion. This way the multi-version store provides a snapshot to each transaction.
CRDB uses RocksDB (now Pebble) for storing of these key-value ranges at the storage layer. Ranges are the unit of replication. CRDB uses the Raft consensus protocol for replication and each range is a Raft group. Again, each range is a Raft group: replication is not at the level of nodes but at the level of ranges. This provides fine-grained control over data placement. For example here you can see see a database of dogs, where the orange
range is a Raft group and is replicated over 3 nodes, the group is
currently assigned to.

Raft provides a useful building block which is atomic replication. Commands are proposed by the leaseholder, which you can assume is the same as the Raft leader. The command is accepted when a quorum of replicas acknowledge.
Distributed transactions
Transactions can span arbitrary ranges and they support a conversational protocol that supports SQL where the full set of operations may not be known up front. Transactions in CockroachDB use serializable isolation level.
To guarantee atomicity even for transactions that span multiple ranges, CockroachDB takes advantage of the range level atomicity of Raft. Each transaction is associated with a transaction record, which just like other data updates, go through Raft. Atomic commit for a transaction is achieved by considering all of
its writes provisional until commit time through this transaction record. CRDB calls these provisional
values write intents. An intent is a regular MVCC KV pair, except that
it is preceded by metadata indicating that what follows is an intent.
This metadata points to the transaction record, which stores the current disposition of the
transaction: pending, staging, committed or aborted. The transaction
record serves to atomically change the visibility of all the intents at
once, and is durably stored in the same range as the first write of the
transaction.
Let's look at this simple example from the presentation to understand how transactions work. Consider the older suboptimal version of the algorithm first. This is basically 2PC over Paxos groups. An important point is the use of a transaction record that is atomically flipped to maintain the status of transaction in an atomic manner.

What you see here is a cluster with three ranges spread across four nodes. The leaseholders for each range are highlighted with a black outline. This insert statement is inserting two rows into our dog's table Sunny and Ozzie. To begin the client connects to a gateway node which connects to the leaseholder for the range containing Sunny since Sunny is the first key written as part of the transaction. The transaction record is created on the range containing Sunny. To replicate the transaction record, the lease holder proposes a Raft command which writes the record to itself and the follower replicas. Once the lease holder and at least one of the followers accept the creation of the transaction record the transaction is in progress. Next the same lease holder proposes a Raft command that writes Sunny to itself and the followers. It again waits for a quorum before moving on.

Next we write Ozzie. The lease holder for Ozzie will propose a Raft command to write the record to itself in its followers one of the followers will acknowledge and since we have a quorum the write is complete. As a final step the Gateway node commits the transaction by updating this transaction record from pending to committed via another round of consensus.
Optimized transactions
The above protocol requires multiple round trips. CockroachDB evolved into one that can commit a distributed transaction with a latency of a single round-trip with additional asynchronous round trips to perform cleanup. The idea is to pipeline the writes first and then do the transaction record writing as "staged" status and flipping it when quorums acknowledge the writes.

Concurrency control
To achieve serializable transaction, concurrency control is required to detect conflicts and reorder transactions as needed. Below I use the description from the paper, in order not to make any mistakes in my description.
As mentioned before, CRDB is an MVCC system and each transaction performs its reads and writes at its commit timestamp. This results in a total ordering of all transactions in the system, representing a serializable execution. However, conflicts between transactions may require adjustments of the commit timestamp. We describe the situations in which they arise below, and note that whenever the commit timestamp does change, the transaction typically tries to prove that its prior reads remain valid at the new timestamp, in which case it can simply continue forward at the updated timestamp.
Write-read conflicts. A read running into an uncommitted intent with a lower timestamp will wait for the earlier transaction to finalize. Waiting is implemented using in-memory queue structures. A read running into an uncommitted intent with a higher timestamp ignores the intent and does not need to wait.
Read-write conflicts. A write to a key at timestamp ta cannot be performed if there’s already been a read on the same key at a higher timestamp tb >= ta. CRDB forces the writing transaction to advance its commit timestamp past tb.
Write-write conflicts. A write running into an uncommitted intent with a lower timestamp will wait for the earlier transaction to finalize (similar to write-read conflicts). If it runs into a committed value at a higher timestamp, it advances its timestamp past it (similar to read-write conflicts). Write-write conflicts may also lead to deadlocks in cases where different transactions have written intents in different orders. CRDB employs a distributed deadlock-detection algorithm to abort one transaction from a cycle of waiters.
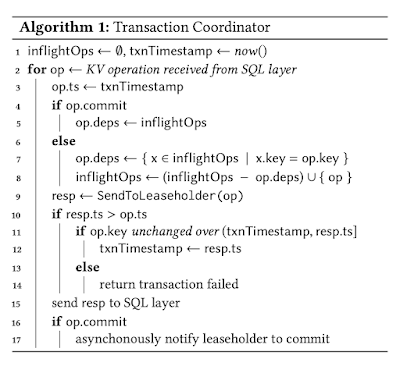
Certain types of conflicts described above require advancing the commit timestamp of a transaction. To maintain serializability, the read timestamp must be advanced to match the commit timestamp. Advancing a transaction’s read timestamp from ta to tb > ta is possible if we can prove that none of the data that the transaction read at ta has been updated in the interval (ta,tb]. If the data has changed, the transaction needs to be restarted. To determine whether the read timestamp can be advanced, CRDB maintains the set of keys in the transaction’s read set (up to a memory budget). A "read refresh" request validates that the keys have not been updated in a given timestamp interval (Algorithm 1, Lines 11 to 14). This involves re-scanning the read set and checking whether any MVCC values fall in the given interval.

Spanner versus CockroachDB
CRDB commit is similar to Spanner commit protocol (2012) in that Spanner also uses 2PL+2PC over Paxos groups. However, in Spanner, the timestamp doesn't move up. Spanner sets it once the locks are taken, and then the transaction commit waits out the clock uncertainty of commit timestamp as needed. They can afford to it by using atomic clocks with very small uncertainty intervals.
CRDB does not rely on specialized hardware for clock synchronization, so it can run on off-the-shelf servers in public and private clouds with software-level clock synchronization services such as NTP. Each node within a CRDB cluster maintains a hybrid logical clock (HLC), which provides timestamps that are a combination of physical and logical time. HLCs provide causality tracking through their logical component upon each inter-node exchange. HLCs provide strict monotonicity within and across restarts on a single node. HLCs provide self-stabilization in the presence of isolated transient clock skew fluctuations. However, when the physical clock synchronization uncertainty is high, CRDB still requires the above techniques about read-refreshes to ensure serializability of transactions.
Another difference is in locking. Spanner acquires read locks in all read-write transactions. CRDB uses pessimistic write locks, but otherwise it is an optimistic protocol with the above described read refresh mechanism that increases the commit timestamp of a transaction if it observes a conflicting write within the clock uncertainty window. This approach provides serializable isolation and has lower latency than Spanner’s protocol for workloads with low contention. It may require more transaction retries for highly contended workloads, however, and for this reason future versions of CRDB will include support for pessimistic read locks.
SQL layer
Ok, let's start by revisiting the question of why CRDB maintains sorted ranges. This is useful for SQL, in order to do efficient range-scans for SQL queries using indexing. The index is also maintained a range. But then how do we find the index? It is treated specially and maintained as the first range in the system. When you split the range, the same transaction that is updating range should also update the index.
To use SQL over CRDB, SQL's tabular data is mapped to Key-Value data, with key being in the format of /<table>/<index>/<key>. For example, /inventory/primary/1. The prefix is stored as index for storage saving.
Let's consider another index, and examples of it mapping to keys.
INDEX name_idx(name)
/inventory/name_idx/"Bat"/1
/inventory/name_idx/"Bat"/4
SQL execution layer turns transaction into series of key value executions. It has the following phases: Scan -> Filter -> Project -> Results. If there is index, the filter gets pushed into the scan.
SQL query optimizer has phases: Parse -> Prep -> Search -> Execute. It can do cost based search.
Lessons learned
The paper has an interesting lessons learned section.
CockroachDB doesn't support any lower isolation levels than Serializability. The paper says the following: Since CRDB was primarily designed for SERIALIZABLE, we initially expected that offering just snapshot isolation by removing the check for write skews would be simple. However, this proved not to be the case. The only safe mechanism to enforce strong consistency under snapshot isolation is pessimistic locking, via the explicit locking modifiers FOR SHARE and FOR UPDATE on queries. To guarantee strong consistency across concurrent mixed isolation levels, CRDB would need to introduce pessimistic locking for any row updates, even for SERIALIZABLE transactions. To avoid this pessimization of the common path, we opted to eschew true support for SNAPSHOT, keeping it as an alias to SERIALIZABLE instead.
The long presentation includes a passing comment: "Raft is not any easier to implement than another Paxos protocol." The paper has a similar comment: "We initially chose Raft as the consensus algorithm for CRDB due to its supposed ease of use and the precise description of its implementation. In practice, we have found there are several challenges in using Raft in a complex system like CRDB." The lessons learned section discusses many Raft improvements. They make Raft less chatty by coalescing the heartbeat messages into one per node to save on the per-RPC overhead, and pausing Raft groups which have seen no recent write activity. They also implemented a change to Raft reconfiguration protocol, which they call Joint Consensus, similar to ZooKeeper's reconfiguration protocol.
The discussion about Postgres compatibility is also interesting: "We chose to adopt PostgreSQL’s SQL dialect and network protocol in CRDB to capitalize on the ecosystem of client drivers. This choice initially boosted adoption and still results today in enhanced focus and decision-making in the engineering team. However, CRDB behaves differently from PostgreSQL in ways that require intervention in client-side code. For example, clients must perform transaction retries after an MVCC conflict and configure result paging. Reusing PostgreSQL drivers as-is requires us to teach developers how to deploy CRDB-specific code at a higher level, anew in every application. This is a recurring source of friction which we had not anticipated. As a result, we are now considering the gradual introduction of CRDB-specific client drivers."





Comments
There are legitimate reasons to use PCC rather than OCC for an MVCC database (e.g., for reducing wasted work due to aborts in highly contended workloads), but it is not remotely a requirement.