Stable and Consistent Membership at Scale with Rapid
This paper is by Lalith Suresh, Dahlia Malkhi, Parikshit Gopalan, Ivan Porto Carreiro, and Zeeshan Lokhandwala, and it appeared in USENIX Annual Technical Conference 2018.
In datacenters complex network conditions may arise, such as one-way reachability problems, firewall misconfigurations, flip-flops in reachability, and high packet loss (where some-but-not-all packets being dropped). Services became even more prone to these gray failures as processes are typically hosted in VM and container abstractions, and networks are governed more and more with software-defined-networking (SDN). Furthermore, everyday several cloud-side service upgrades happen, which create potential failure risks.
Despite being able to cleanly detect crash faults, existing membership solutions struggle with these gray failure scenarios. When you introduce 80% packet-loss failures in 1% of nodes, the correct nodes start to accuse each other and the membership view becomes unstable. The experiments in the paper show that Akka Cluster becomes unstable as conflicting rumors about processes propagate in the cluster concurrently, even resulting in benign processes being removed from the membership. Memberlist and ZooKeeper resist removal of the faulty processes from the membership set but they are unstable for prolonged period of time.
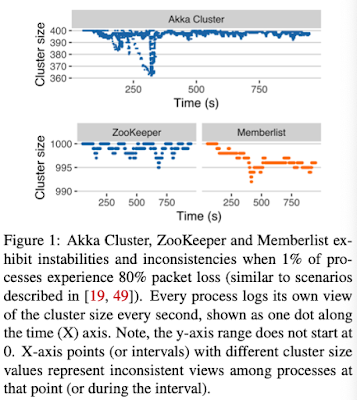
This behavior is problematic because unstable and flapping membership views may cause applications to repeatedly trigger expensive recovery workflows, which may degrade performance and service availability. (Side remark: In practice, though, there is always grace periods before triggering expensive recovery operations. Applications are already designed to be tolerant of inaccurate detections, and expensive operations are delayed until enough evidence amounts.)
1. Expander-based monitoring edge overlay.
Rapid organizes a set of processes (a configuration) into an expander graph topology for failure detection. Each process (i.e. subject) is assigned K observers that monitor and disseminate reports about itself. This is achieved by overlaying K rings on the topology. Each process observes the successor in a ring, and is observed by its predecessor in a ring. This way every process p is monitored by K observer processes and it is responsible for observing K subjects itself. (Who watches the watchers? Well, other watchers! This is a self policing system.)

2. Multi-process cut detection.
If L-of-K correct observers cannot communicate with a subject, then the subject is considered observably unresponsive. For stability, processes in Rapid delay proposing a configuration change until there is at least one process in stable report mode and there is no process in unstable report mode. For this another parameter H is used such that, 1 ≤ L ≤ H ≤ K. A stable report mode indicates that p has received at least H distinct observer alerts about s, hence we consider it “high fidelity”. A process s is in an unstable report mode if tally(s) is in between L and H. It may be that tally did not reach H because the other observers for s have been down by themselves. If those observers are considered unresponsive by some processes, these reports are used to bring the tally above H. If that fails, there is a timeout to take s out of unstable report mode, so that a configuration change can be proposed.

3. Fast consensus.
The paper argues that the above cut detection suffices to drive unanimous detection almost everywhere. Rapid uses a leaderless Fast Paxos consensus protocol to achieve configuration changes quickly for this common case: every process simply validates consensus by counting the number of identical cut detections. If there is a quorum containing three-quarters of the membership set with the same cut (i.e., a supermajority quorum), then without a leader or further communication, this is adopted as a safe consensus decision. If this fails, the protocol falls back to a classical consensus protocol.
The paper reports on experiments on a shared internal cloud service with 200 cores and 800 GB of RAM (100 VMs), where the number of processes (N) in the cluster are varied from 1000 to 2000. (They run multiple processes per VM, because the workloads are not CPU bottlenecked.)



Here is a video of the presentation of the paper in our Zoom DistSys Reading group.
1. Problem definition
The paper says that the membership service needs to have stability (robustness against gray failures, flip-flops) and consistency (providing the same sequence of membership changes to processes). We also need to have quick reaction to the changes. But what is the right tradeoff of these conflicting features? If the speed is high and captures the membership changes quickly, the nodes getting information at different times will see different views/epochs of the group membership as even the supermajority group leaves behind a quarter of the nodes. This would lead to a loss of stability.
It looks like the right tradeoff between speed and stability would be application dependent, and this makes the problem specification fuzzy and fickle.
2. Cassandra membership service problems
The paper mentions this:
3. Using ZooKeeper as a membership service
The paper has this to say about membership management with ZooKeeper:
4. What do large scale cloud systems use as membership services?
Microsoft uses service fabric (available as opensource). The service fabric paper is a good companion to read with this Rapid paper to compare and contrast approaches. Here is an overview summary of Service Fabric paper.
I had recently covered Physalia, which provides a membership service over Amazon Elastic Block Storage (EBS). Physalia had very nice ideas for minimizing blast radius of failures, and for relocating membership service close to the nodes it is monitoring to alleviate effects of network partitions.
Google may be using some membership services based on Chubby. But they must have other solutions for membership services for large scale clusters.
In datacenters complex network conditions may arise, such as one-way reachability problems, firewall misconfigurations, flip-flops in reachability, and high packet loss (where some-but-not-all packets being dropped). Services became even more prone to these gray failures as processes are typically hosted in VM and container abstractions, and networks are governed more and more with software-defined-networking (SDN). Furthermore, everyday several cloud-side service upgrades happen, which create potential failure risks.
Despite being able to cleanly detect crash faults, existing membership solutions struggle with these gray failure scenarios. When you introduce 80% packet-loss failures in 1% of nodes, the correct nodes start to accuse each other and the membership view becomes unstable. The experiments in the paper show that Akka Cluster becomes unstable as conflicting rumors about processes propagate in the cluster concurrently, even resulting in benign processes being removed from the membership. Memberlist and ZooKeeper resist removal of the faulty processes from the membership set but they are unstable for prolonged period of time.

This behavior is problematic because unstable and flapping membership views may cause applications to repeatedly trigger expensive recovery workflows, which may degrade performance and service availability. (Side remark: In practice, though, there is always grace periods before triggering expensive recovery operations. Applications are already designed to be tolerant of inaccurate detections, and expensive operations are delayed until enough evidence amounts.)
Rapid Membership Service Design
To address the stability and consistency problems with existing services, the paper presents the Rapid membership service, which consists of three components.1. Expander-based monitoring edge overlay.
Rapid organizes a set of processes (a configuration) into an expander graph topology for failure detection. Each process (i.e. subject) is assigned K observers that monitor and disseminate reports about itself. This is achieved by overlaying K rings on the topology. Each process observes the successor in a ring, and is observed by its predecessor in a ring. This way every process p is monitored by K observer processes and it is responsible for observing K subjects itself. (Who watches the watchers? Well, other watchers! This is a self policing system.)

2. Multi-process cut detection.
If L-of-K correct observers cannot communicate with a subject, then the subject is considered observably unresponsive. For stability, processes in Rapid delay proposing a configuration change until there is at least one process in stable report mode and there is no process in unstable report mode. For this another parameter H is used such that, 1 ≤ L ≤ H ≤ K. A stable report mode indicates that p has received at least H distinct observer alerts about s, hence we consider it “high fidelity”. A process s is in an unstable report mode if tally(s) is in between L and H. It may be that tally did not reach H because the other observers for s have been down by themselves. If those observers are considered unresponsive by some processes, these reports are used to bring the tally above H. If that fails, there is a timeout to take s out of unstable report mode, so that a configuration change can be proposed.

3. Fast consensus.
The paper argues that the above cut detection suffices to drive unanimous detection almost everywhere. Rapid uses a leaderless Fast Paxos consensus protocol to achieve configuration changes quickly for this common case: every process simply validates consensus by counting the number of identical cut detections. If there is a quorum containing three-quarters of the membership set with the same cut (i.e., a supermajority quorum), then without a leader or further communication, this is adopted as a safe consensus decision. If this fails, the protocol falls back to a classical consensus protocol.
Evaluation
Rapid is implemented in Java with 2362 lines of code (excluding comments and blank lines). The code is opensource at https://github.com/lalithsuresh/rapidThe paper reports on experiments on a shared internal cloud service with 200 cores and 800 GB of RAM (100 VMs), where the number of processes (N) in the cluster are varied from 1000 to 2000. (They run multiple processes per VM, because the workloads are not CPU bottlenecked.)



Here is a video of the presentation of the paper in our Zoom DistSys Reading group.
Discussion
We had a productive discussion about the paper in our Zoom DistSys Reading Group. (You can join our Slack workspace to get involved with paper discussions and the Zoom meetings.) Comments below capture some of that discussion.1. Problem definition
The paper says that the membership service needs to have stability (robustness against gray failures, flip-flops) and consistency (providing the same sequence of membership changes to processes). We also need to have quick reaction to the changes. But what is the right tradeoff of these conflicting features? If the speed is high and captures the membership changes quickly, the nodes getting information at different times will see different views/epochs of the group membership as even the supermajority group leaves behind a quarter of the nodes. This would lead to a loss of stability.
It looks like the right tradeoff between speed and stability would be application dependent, and this makes the problem specification fuzzy and fickle.
2. Cassandra membership service problems
The paper mentions this:
In Cassandra, the lack of consistent membership causes nodes to duplicate data re-balancing efforts when concurrently adding nodes to a cluster [11] and also affects correctness [12]. To work around the lack of consistent membership, Cassandra ensures that only a single node is joining the cluster at any given point in time, and operators are advised to wait at least two minutes between adding each new node to a cluster [11]. As a consequence, bootstrapping a 100 node Cassandra cluster takes three hours and twenty minutes, thereby significantly slowing down provisioning [11].This is true for scaling an existing hash ring by adding new members. There the gossip-based eventual consistency membership service becomes a bottleneck and require a two minute wait time for safety between adding each node to the cluster. On the other hand, if you are bootstrapping 100 nodes from scratch with no hash ring, it is possible to get all those nodes running in parallel, and construct the hash ring after stabilization of the membership.
3. Using ZooKeeper as a membership service
The paper has this to say about membership management with ZooKeeper:
Group membership with ZooKeeper is done using watches. When the ith process joins the system, it triggers i-1 watch notifications, causing i-1 processes to re-read the full membership list and register a new watch each. In the interval between a watch having triggered and it being replaced, the client is not notified of updates, leading to clients observing different sequences of membership change events. This behavior with watches leads to the eventually consistent client behavior in Figure 7. Lastly, we emphasize that this is a 3-node ZooKeeper cluster being used exclusively to manage membership for a single cluster. Adding even one extra watch per client to the group node at N=2000 inflates bootstrap latencies to 400s on average.In practice ZooKeeper is typically used for managing membership for small clusters.
4. What do large scale cloud systems use as membership services?
Microsoft uses service fabric (available as opensource). The service fabric paper is a good companion to read with this Rapid paper to compare and contrast approaches. Here is an overview summary of Service Fabric paper.
I had recently covered Physalia, which provides a membership service over Amazon Elastic Block Storage (EBS). Physalia had very nice ideas for minimizing blast radius of failures, and for relocating membership service close to the nodes it is monitoring to alleviate effects of network partitions.
Google may be using some membership services based on Chubby. But they must have other solutions for membership services for large scale clusters.





Comments