Paper summary: ZooKeeper: Wait-free coordination for Internet-scale systems
Zookeeper is an Apache project for providing coordination services to distributed systems. ZooKeeper aims to provide a simple kernel (a filesystem API!) for empowering the clients to build more complex coordination primitives. In this post I will provide a summary of the ZooKeeper paper, and talk about some future directions I can see this going.
"Client" denotes a user of the ZooKeeper service, "server" denotes a process providing the ZooKeeper service, and "znode" denotes an in-memory data node (similar to the filesystem inode) in the ZooKeeper. znodes are organized in a hierarchical namespace referred to as the data tree.
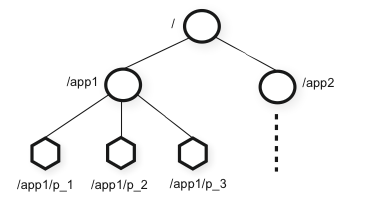 There are 2 types of znodes. "Regular": Clients manipulate regular znodes by creating and deleting them explicitly. "Ephemeral": Clients create ephemeral znodes, and they either delete them explicitly, or let the system delete them automatically when the client's session termination. Additionally, when creating a new znode, a client can set a "Sequential" flag. Nodes created with the sequential flag set have the value of a monotonically increasing counter appended to its name. If n is the new znode and p is the parent znode, then the sequence value of n is never smaller than the value in the name of any other sequential znode ever created under p.
There are 2 types of znodes. "Regular": Clients manipulate regular znodes by creating and deleting them explicitly. "Ephemeral": Clients create ephemeral znodes, and they either delete them explicitly, or let the system delete them automatically when the client's session termination. Additionally, when creating a new znode, a client can set a "Sequential" flag. Nodes created with the sequential flag set have the value of a monotonically increasing counter appended to its name. If n is the new znode and p is the parent znode, then the sequence value of n is never smaller than the value in the name of any other sequential znode ever created under p.
ZooKeeper also implements "watches" on znodes to allow clients to receive timely notifications of changes without requiring polling.
delete(path, version) // operation is conditional on version (if provided)
exists(path, watch)
getData(path, watch)
setData(path, data, version) // operation is conditional on version (if provided)
getChildren(path, watch)
sync(path)
All methods in the API have both a synchronous and an asynchronous version. A client uses the synchronous API when it needs to execute a single ZooKeeper operation and it has no concurrent tasks to execute, so it makes the necessary ZooKeeper call and blocks. The asynchronous API enables a client to have both multiple outstanding ZooKeeper operations and other tasks executed in parallel. ZooKeeper guarantees that the corresponding callbacks for each operation are invoked in order.
Rendezvous: When the master starts it fills in zr with information about addresses and ports it is using. When workers start, they read zr with watch set to true. If zr has not been filled in yet, the worker waits to be notified when zr is updated.
Group Membership: A znode, zg, is created to represent the group. When a process member of the group starts, it creates an ephemeral child znode under zg. If the process fails or ends, the znode that represents it under zg is automatically removed. Processes may put process information in the data of the child znode, e.g., addresses and ports used by the process. Processes may obtain group information by simply listing the children of zg. If a process wants to monitor changes in group membership, the process can set the watch flag to true and refresh the group information (always setting the watch flag to true) when change notifications are received.
Simple locks: To acquire a lock, a client tries to create the designated znode with the EPHEMERAL flag. If the create succeeds, the client holds the lock. Otherwise, the client can read the znode with the watch flag set. A client releases the lock explicitly or it is removed by timeout if it dies. Other clients that are waiting for a lock try again to acquire a lock once they observe the znode being deleted.
Simple Locks without Herd Effect: All the clients requesting the lock are lined up and each client obtains the lock in order of request arrival.
To lock:
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event 6 goto 2
To unlock:
1 delete(n)
Read/Write Locks: The lock procedure is changed slightly to include separate read lock and write lock procedures.
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event 6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
You can build even more powerful coordination primitives using ZooKeeper, and a Python binding is also made available here.
Zookeeper applications at Yahoo!: ZooKeeper is used for the Fetching Service (FS) to achieve recovering from failures of masters, guaranteeing availability despite failures, and decoupling the clients from the servers, and allowing them to direct their request to healthy servers by just reading their status from ZooKeeper. FS uses ZooKeeper mainly to manage configuration metadata. FS is read-heavy, 10:1 to 100:1. As another example, Yahoo! Message Broker (YMB), a distributed publish-subscribe system, uses ZooKeeper to manage the distribution of topics (configuration metadata), deal with failures of machines in the system (failure detection and group membership), and control system operation.
Other practical uses of Zookeeper has been explained nicely here.

The replicated database is an in-memory database containing the entire data tree. Each znode in the tree stores a maximum of 1MB of data by default. For recoverability, ZooKeeper efficiently logs updates to disk, and forces writes to be on the disk media before they are applied to the in-memory database.
Every ZooKeeper server services clients. Clients connect to exactly one server to submit its requests. Read requests are serviced from the local replica of each server database.
Requests that change the state of the service, write requests, are processed by an agreement protocol. As part of the agreement protocol write requests are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals consisting of state changes from the leader and agree upon state changes. This is similar to how Paxos works.
ZooKeeper's atomic broadcast protocol (Zab) uses by default simple majority quorums to decide on a proposal, so Zab and thus ZooKeeper can only work if a majority of servers are correct (i.e., with 2f + 1 server we can tolerate f failures). Zab guarantees that changes broadcast by a leader are delivered in the order they were sent and all changes from previous leaders are delivered to an established leader before it broadcasts its own changes.
More specifically, Zab/ZooKeeper provides both of these two basic ordering guarantees:
Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect precedence.
FIFO client order: all requests from a given client are executed in the order that they were sent by the client.
Proposer P1 executes Phase 1 for sequence numbers 27 and 28. It proposes values A and B for sequence numbers 27 and 28, respectively, in Phase 2 with ballot number 1. Both proposals are accepted only by acceptor A1. Proposer P2 executes Phase 1 against acceptors A2 and A3, and end up proposing C in Phase 2 to sequence number 27 with ballot number 2. Finally, proposer P3, executes Phase 1 and 2, and is able to have a quorum of acceptors choosing C for sequence number 27, B for sequence number 28, and D for 29.
ZooKeeper argues that such a run is not acceptable because the state change represented by B causally depends upon A, and not C. Consequently, B can only be chosen for sequence number i+1 if A has been chosen for sequence number i, and C cannot be chosen before B, since the state change that B represents cannot commute with C and can only be applied after A.
One drawback of using fast reads (local reads at one server) is not guaranteeing precedence order for read operations. That is, a read operation may return a stale value, even though a more recent update to the same znode has been committed. Not all applications require precedence order, but for applications that do require it, the sync primitive is used. To guarantee that a given read operation returns the latest updated value, a client calls sync before the read operation. Sync flushes the pipes so to speak. The FIFO order guarantee of client operations together with the global guarantee of sync enables the result of the read operation to reflect any changes that happened before the sync was issued.
Read requests are handled locally at each server. Each read request is tagged with a zxid that corresponds to the last transaction seen by the server. ZooKeeper servers process requests from clients in FIFO order; responses include the zxid that the response is relative to. Even heartbeat messages during intervals of no activity include the last zxid seen by the server that the client is connected to. This zxid defines the partial order of the read requests with respect to the write requests. If the client connects to a new server, that new server ensures that its view of the ZooKeeper data is at least as recent as the view of the client by checking the last zxid of the client against its last zxid. If the client has a more recent view than the server, the server does not reestablish the session with the client until the server has caught up.
To detect client session failures, ZooKeeper uses time-outs. To prevent the session from timing out, the ZooKeeper client library sends a heartbeat after the session has been idle for s/3 ms and switch to a new server if it has not heard from a server for 2s/3 ms, where s is the session timeout in milliseconds.

As you add ZooKeeper servers, the read throughput improves, bu the write throughput degrades. This is because atomic broadcast needs to be done via Zab. Also the servers need to ensure that transactions are logged to non-volatile store before sending acknowledgments back to the leader.
In most places ZooKeeper is punting the ball to the clients. Yes, this is due to minimalistic design and such, but this burdens the clients to solve the transactional update themselves, and we know that this is error-prone. Maybe this is really the way to go. Or maybe this is the soft-belly of ZooKeeper and a big opportunity to provide a new coordination tool.
ZooKeeper is a great start, but we are just at the beginning.
How can you implement distributed counters without using sequential flag?
How can you implement general purpose transactions on ZooKeeper?
Is ZooKeeper enough to implement general transactions? What is missing?
Why not use ZooKeeper for serializing and reliably storing all data? Why is it a bad idea to use ZooKeeper for maintaining application logs?
Apache Curator project maintains most common ZooKeeper client algorithms
"Client" denotes a user of the ZooKeeper service, "server" denotes a process providing the ZooKeeper service, and "znode" denotes an in-memory data node (similar to the filesystem inode) in the ZooKeeper. znodes are organized in a hierarchical namespace referred to as the data tree.
ZooKeeper also implements "watches" on znodes to allow clients to receive timely notifications of changes without requiring polling.
The API ZooKeeper provides to the clients
create(path, data, flags)delete(path, version) // operation is conditional on version (if provided)
exists(path, watch)
getData(path, watch)
setData(path, data, version) // operation is conditional on version (if provided)
getChildren(path, watch)
sync(path)
All methods in the API have both a synchronous and an asynchronous version. A client uses the synchronous API when it needs to execute a single ZooKeeper operation and it has no concurrent tasks to execute, so it makes the necessary ZooKeeper call and blocks. The asynchronous API enables a client to have both multiple outstanding ZooKeeper operations and other tasks executed in parallel. ZooKeeper guarantees that the corresponding callbacks for each operation are invoked in order.
Using ZooKeeper to implement coordination primitives
Configuration Management: The configuration is stored in a znode, zc. Processes start up with the full pathname of zc. Starting processes obtain their configuration by reading zc with the watch flag set to true. If the configuration in zc is ever updated, the processes are notified and read the new configuration, again setting the watch flag to true.Rendezvous: When the master starts it fills in zr with information about addresses and ports it is using. When workers start, they read zr with watch set to true. If zr has not been filled in yet, the worker waits to be notified when zr is updated.
Group Membership: A znode, zg, is created to represent the group. When a process member of the group starts, it creates an ephemeral child znode under zg. If the process fails or ends, the znode that represents it under zg is automatically removed. Processes may put process information in the data of the child znode, e.g., addresses and ports used by the process. Processes may obtain group information by simply listing the children of zg. If a process wants to monitor changes in group membership, the process can set the watch flag to true and refresh the group information (always setting the watch flag to true) when change notifications are received.
Simple locks: To acquire a lock, a client tries to create the designated znode with the EPHEMERAL flag. If the create succeeds, the client holds the lock. Otherwise, the client can read the znode with the watch flag set. A client releases the lock explicitly or it is removed by timeout if it dies. Other clients that are waiting for a lock try again to acquire a lock once they observe the znode being deleted.
Simple Locks without Herd Effect: All the clients requesting the lock are lined up and each client obtains the lock in order of request arrival.
To lock:
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event 6 goto 2
To unlock:
1 delete(n)
Read/Write Locks: The lock procedure is changed slightly to include separate read lock and write lock procedures.
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event 6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
You can build even more powerful coordination primitives using ZooKeeper, and a Python binding is also made available here.
Zookeeper applications at Yahoo!: ZooKeeper is used for the Fetching Service (FS) to achieve recovering from failures of masters, guaranteeing availability despite failures, and decoupling the clients from the servers, and allowing them to direct their request to healthy servers by just reading their status from ZooKeeper. FS uses ZooKeeper mainly to manage configuration metadata. FS is read-heavy, 10:1 to 100:1. As another example, Yahoo! Message Broker (YMB), a distributed publish-subscribe system, uses ZooKeeper to manage the distribution of topics (configuration metadata), deal with failures of machines in the system (failure detection and group membership), and control system operation.
Other practical uses of Zookeeper has been explained nicely here.
ZooKeeper architecture/internals
The replicated database is an in-memory database containing the entire data tree. Each znode in the tree stores a maximum of 1MB of data by default. For recoverability, ZooKeeper efficiently logs updates to disk, and forces writes to be on the disk media before they are applied to the in-memory database.
Every ZooKeeper server services clients. Clients connect to exactly one server to submit its requests. Read requests are serviced from the local replica of each server database.
Requests that change the state of the service, write requests, are processed by an agreement protocol. As part of the agreement protocol write requests are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals consisting of state changes from the leader and agree upon state changes. This is similar to how Paxos works.
ZooKeeper's atomic broadcast protocol (Zab) uses by default simple majority quorums to decide on a proposal, so Zab and thus ZooKeeper can only work if a majority of servers are correct (i.e., with 2f + 1 server we can tolerate f failures). Zab guarantees that changes broadcast by a leader are delivered in the order they were sent and all changes from previous leaders are delivered to an established leader before it broadcasts its own changes.
More specifically, Zab/ZooKeeper provides both of these two basic ordering guarantees:
Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect precedence.
FIFO client order: all requests from a given client are executed in the order that they were sent by the client.
ZooKeeper vs Paxos
ZooKeeper provides FIFO client order property, but Paxos doesn't. Paxos may violate the FIFO client property as follows.Proposer P1 executes Phase 1 for sequence numbers 27 and 28. It proposes values A and B for sequence numbers 27 and 28, respectively, in Phase 2 with ballot number 1. Both proposals are accepted only by acceptor A1. Proposer P2 executes Phase 1 against acceptors A2 and A3, and end up proposing C in Phase 2 to sequence number 27 with ballot number 2. Finally, proposer P3, executes Phase 1 and 2, and is able to have a quorum of acceptors choosing C for sequence number 27, B for sequence number 28, and D for 29.
ZooKeeper argues that such a run is not acceptable because the state change represented by B causally depends upon A, and not C. Consequently, B can only be chosen for sequence number i+1 if A has been chosen for sequence number i, and C cannot be chosen before B, since the state change that B represents cannot commute with C and can only be applied after A.
Client server interaction
When a server completes a write operation, it also sends out and clears notifications relative to any watch that corresponds to that update. Servers process the writes the leader server sends in order and do not process other writes or reads concurrently in order to ensure strict succession of notifications. Note that servers handle notifications locally. Only the server that a client is connected to tracks and triggers notifications for that client.One drawback of using fast reads (local reads at one server) is not guaranteeing precedence order for read operations. That is, a read operation may return a stale value, even though a more recent update to the same znode has been committed. Not all applications require precedence order, but for applications that do require it, the sync primitive is used. To guarantee that a given read operation returns the latest updated value, a client calls sync before the read operation. Sync flushes the pipes so to speak. The FIFO order guarantee of client operations together with the global guarantee of sync enables the result of the read operation to reflect any changes that happened before the sync was issued.
Read requests are handled locally at each server. Each read request is tagged with a zxid that corresponds to the last transaction seen by the server. ZooKeeper servers process requests from clients in FIFO order; responses include the zxid that the response is relative to. Even heartbeat messages during intervals of no activity include the last zxid seen by the server that the client is connected to. This zxid defines the partial order of the read requests with respect to the write requests. If the client connects to a new server, that new server ensures that its view of the ZooKeeper data is at least as recent as the view of the client by checking the last zxid of the client against its last zxid. If the client has a more recent view than the server, the server does not reestablish the session with the client until the server has caught up.
To detect client session failures, ZooKeeper uses time-outs. To prevent the session from timing out, the ZooKeeper client library sends a heartbeat after the session has been idle for s/3 ms and switch to a new server if it has not heard from a server for 2s/3 ms, where s is the session timeout in milliseconds.
Evaluation
The evaluation is performed on a cluster of 50 servers. For the target workloads, 2:1 to 100:1 read to write ratio, it is shown that ZooKeeper can handle tens to hundreds of thousands of transactions per second. Each client has at least 100 requests outstanding. Each request consists of a read or write of 1K of data.As you add ZooKeeper servers, the read throughput improves, bu the write throughput degrades. This is because atomic broadcast needs to be done via Zab. Also the servers need to ensure that transactions are logged to non-volatile store before sending acknowledgments back to the leader.
Conclusion
ZooKeeper provides a minimalist and flexible coordination system and found a lot of use in production distributed systems. Zookeeper scales well with increase in read operations, but does not with increase in write operations. Zookeeper also does not scale with more Zookeeper replicas added. To alleviate this observer replicas are used, but they are limited in operation, and do not allow/benefit write operations. Finally, due to very large latencies involved ZooKeeper cannot handle across the WAN deployment of ZooKeeper servers.In most places ZooKeeper is punting the ball to the clients. Yes, this is due to minimalistic design and such, but this burdens the clients to solve the transactional update themselves, and we know that this is error-prone. Maybe this is really the way to go. Or maybe this is the soft-belly of ZooKeeper and a big opportunity to provide a new coordination tool.
ZooKeeper is a great start, but we are just at the beginning.
Exercise questions
How does ZooKeeper implement/provide ephemeral nodes?How can you implement distributed counters without using sequential flag?
How can you implement general purpose transactions on ZooKeeper?
Is ZooKeeper enough to implement general transactions? What is missing?
Why not use ZooKeeper for serializing and reliably storing all data? Why is it a bad idea to use ZooKeeper for maintaining application logs?
Related links
High-availability distributed logging with BookKeeperApache Curator project maintains most common ZooKeeper client algorithms





Comments
Simple Locks without Herd Effect:
To lock:
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event 6 goto 2
which was confusing until I realized that the last line is supposed to be
...
5 if exists(p, true) wait for watch event 6 goto 2
Regardless - good article!
...
5 if exists(p, true) wait for watch event
6 goto 2