Consensus in the Cloud: Paxos Systems Demystified
This our most recent paper, still under submission. It is available as a technical report here. We felt we had to write this paper because we have seen misuses/abuses of Paxos-based coordination services. Glad this is off our chests.
Here is the short pitch for the paper. I hope you like it and find it helpful.
Coordination and consensus play an important role in datacenter and cloud computing. Examples are leader election, group membership, cluster management, service discovery, resource/access management, and consistent replication of the master nodes in services.
Paxos protocols and systems provide a fault-tolerant solution to the distributed consensus problem and have attracted significant attention but they also generated substantial confusion. Zab, Multi-Paxos, Raft are examples of Paxos protocols. ZooKeeper, Chubby, etcd are examples of Paxos systems. Paxos systems and Paxos protocols reside in different planes, but even that doesn't prevent these two concepts to be confused. Paxos protocols are useful for low-level components for server replication, whereas Paxos systems have been often shoehorned to that task. The proper use case for Paxos systems is in highly-available/durable metadata management, under the conditions that all metadata fit in main-memory and are not subject to frequent changes.
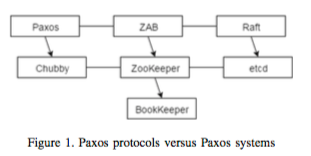
In order to elucidate the correct use of distributed coordination systems, we compare and contrast popular Paxos protocols and Paxos systems and present advantages and disadvantages for each. Zab and Raft protocols differ from Paxos as they divide execution into epochs: Each epoch begins with a new election, goes into the broadcast phase and ends with a leader failure. Similarly, Paxos systems also have nuances. Chubby uses the MultiPaxos algorithm to achieve linearizability, while Zab lies at the heart of ZooKeeper and provides not only linearizability, but also FIFO order for client requests, enabling the developers to build complex coordination primitives with ease. Etcd system uses Raft as the consensus protocol, and adopts a stateless design and implements certain features very differently than ZooKeeper and Chubby.
We also categorize the coordination use-patterns in cloud into nine broad categories: server replication (SR), log replication (LR), synchronization service (SS), barrier orchestration (BO), service discovery (SD), group membership (GM), leader election (LE), metadata management (MM) and distributed queues (Q). Using these categories, we examine Google and Facebook infrastructures, as well as Apache top-level projects to investigate how they use Paxos protocols and systems.

Finally, we analyze tradeoffs in the distributed coordination domain and identify promising future directions for achieving more scalable distributed coordination systems.
See the paper for more information.
Here is the short pitch for the paper. I hope you like it and find it helpful.
Coordination and consensus play an important role in datacenter and cloud computing. Examples are leader election, group membership, cluster management, service discovery, resource/access management, and consistent replication of the master nodes in services.
Paxos protocols and systems provide a fault-tolerant solution to the distributed consensus problem and have attracted significant attention but they also generated substantial confusion. Zab, Multi-Paxos, Raft are examples of Paxos protocols. ZooKeeper, Chubby, etcd are examples of Paxos systems. Paxos systems and Paxos protocols reside in different planes, but even that doesn't prevent these two concepts to be confused. Paxos protocols are useful for low-level components for server replication, whereas Paxos systems have been often shoehorned to that task. The proper use case for Paxos systems is in highly-available/durable metadata management, under the conditions that all metadata fit in main-memory and are not subject to frequent changes.

In order to elucidate the correct use of distributed coordination systems, we compare and contrast popular Paxos protocols and Paxos systems and present advantages and disadvantages for each. Zab and Raft protocols differ from Paxos as they divide execution into epochs: Each epoch begins with a new election, goes into the broadcast phase and ends with a leader failure. Similarly, Paxos systems also have nuances. Chubby uses the MultiPaxos algorithm to achieve linearizability, while Zab lies at the heart of ZooKeeper and provides not only linearizability, but also FIFO order for client requests, enabling the developers to build complex coordination primitives with ease. Etcd system uses Raft as the consensus protocol, and adopts a stateless design and implements certain features very differently than ZooKeeper and Chubby.
We also categorize the coordination use-patterns in cloud into nine broad categories: server replication (SR), log replication (LR), synchronization service (SS), barrier orchestration (BO), service discovery (SD), group membership (GM), leader election (LE), metadata management (MM) and distributed queues (Q). Using these categories, we examine Google and Facebook infrastructures, as well as Apache top-level projects to investigate how they use Paxos protocols and systems.

Finally, we analyze tradeoffs in the distributed coordination domain and identify promising future directions for achieving more scalable distributed coordination systems.
See the paper for more information.





Comments
In this blog post, it is explained why Apache Cassandra no long use ZooKeeper:
http://docs.datastax.com/en/articles/cassandra/cassandrathenandnow.html
"Zookeeper usage was restricted to Facebook’s in-house Cassandra branch; Apache Cassandra has always avoided it. This means that you can’t add nodes to the cluster faster than membership awareness can spread via gossip (up to a minute for a large cluster), but we consider this worth the simplicity of avoiding the extra moving parts."