Tunable Consistency in MongoDB
This paper appeared in VLDB 2019. It discusses the tunable consistency models in MongoDB and how MongoDB's speculative execution model and data rollback protocol enable this spectrum of consistency levels efficiently.
Motivation
Applications often tolerate short or infrequent periods of inconsistency, so it may not make sense for them to pay the high cost of ensuring strong consistency at all times. These types of trade-offs have been partially codified in the PACELC theorem. The Probabilistically Bounded Staleness work (and many followup work) explored the trade-offs between operation latency and data consistency in distributed database replication and showcased their importance.
To provide users with a set of tunable consistency options, MongoDB exposes writeConcern and readConcern levels as parameters that can be set on each database operation. writeConcern specifies what durability guarantee a write must satisfy before being acknowledged to a client. Similarly, readConcern determines what durability or consistency guarantees data returned to a client must satisfy. For safety it is preferable to use readConcern “majority” and writeConcern “majority”. However, when users find stronger consistency levels to be too slow, they switch to using weaker consistency levels.
In MongoDB when reading from and writing to the primary, users usually read their own writes and the system behaves like a single node. There are fault implications to durability of data this way, but for many applications these are well tolerated. An example of this is a game site that matches active players. This site has a high volume of writes, since its popularity means there are many active players looking to begin games. Durability is not important in this use case, since if a write is lost, the player typically retries immediately and is matched into another game.
As another example, a popular review site uses readConcern “local” and writeConcern “majority” for its reviews. Write loss is painful, since users may spend significant time writing a review, and using “majority” guards against write loss. Reviews are read with readConcern “local”, since users benefit from reading the most recent data, and there is no harm in displaying an unacknowledged write that might be rolled back. Moreover, often a long online form will include multiple save points, where a partial write of the form is sent to the database. The writes at save points are performed using w:1, and the final form submission write is performed using w:“majority”.
Finally as an example from the other end of the spectrum, consider Majority Reads with Causal Consistency and Local Writes. This combination is useful when writes are small, but double writes are painful. Consider a social media site with short posts. Low-latency posts are desirable, and write loss is acceptable, since a user can rewrite their post, so writes use w:1. However, double writes are painful, since it is undesirable user behavior to have the same post twice. For this reason, reads use readConcern level “majority” with causal consistency so that a user can definitively see whether their post was successful.
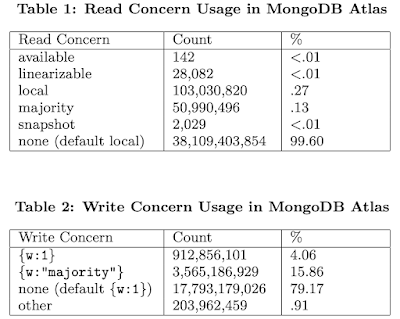
To characterize the consistency levels used by MongoDB application developers, the paper collected operational data from 14,820 instances running 4.0.6 that are managed by MongoDB Atlas. These counts are from 2019, and they are also fairly low because around the data collection time all nodes had been restarted in order to upgrade them to 4.0.6. But they give an idea about the spectrum of read and write concerns used by customer applications.
Background
MongoDB is a NoSQL, document oriented database that stores data in JSON-like objects. All data in MongoDB is stored in a binary form of JSON called BSON. A MongoDB database consists of a set of collections, where a collection is a set of unique documents. MongoDB utilizes the WiredTiger storage engine, which is a transactional multi-version concurrency control (MVCC) key value data store that manages the interface to a local durable storage medium.

To provide high availability, MongoDB provides the ability to run a database as a replica set using a leader based consensus protocol based on Raft. In a replica set there exists a single primary and a set of secondary nodes. The primary node accepts client writes and inserts them into a replication log known as the oplog, where each entry contains information about how to apply a single database operation. Each entry is assigned a timestamp; these timestamps are unique and totally ordered within a node’s log. Oplog entries do not contain enough information to undo operations.

The MongoDB replication system serializes every write that comes into the system into the oplog. When an operation is processed by a replica set primary, the effect of that operation must be written to the database, and the description of that operation must also be written into the oplog. All operations in MongoDB occur inside WiredTiger transactions. When an operation’s transaction commits, we call the operation locally committed. Once it has been written to the database and the oplog, it can be replicated to secondaries, and once it has propagated to enough nodes that meet the necessary conditions, the operation will become majority committed (marked as such in primary and later learned by secondaries) which means it is permanently durable in the replica set.
For horizontal scaling, MongoDB also offers sharding, which allows users to partition their data across multiple replica sets, but we won't discuss it in this paper.
writeConcern
writeConcern can be specified either as a numeric value or as “majority”. Write operations done at w:N will be acknowledged to a client when at least N nodes of the replica set (including the primary) have received and locally committed the write. Clients that issue a w:“majority” write will not receive acknowledgement until it is guaranteed that the write operation is majority committed. This means that the write will be resilient to any temporary or permanent failure of any set of nodes in the replica set, assuming there is no data loss at the underlying OS or hardware layers.
readConcern
For a read operation done at readConcern “local”, the data returned will reflect the local state of a replica set node at the time the query is executed. There are no guarantees that the data returned is majority committed in the replica set, but it will reflect the newest data known to a particular node. Reads with readConcern “majority” are guaranteed to only return data that is majority committed. For majority reads, there is no strict guarantee on the recency of the returned data: The data may be staler than the newest majority committed write operation. (We revisit this in the Consistency Spectrum section, and discuss how majority reads differs from that in Cassandra.)
MongoDB also provides “linearizable” readConcern, which, when combined with w:“majority” write operations provides the strongest consistency guarantees. Reads with readConcern level “linearizable” are guaranteed to return the effect of the most recent majority write that completed before the read operation began.
Additionally, MongoDB provides “available” and “snapshot” read concern levels, and the ability for causally consistent reads. The “snapshot” read concern only applies to multi-document transactions, and guarantees that clients see a consistent snapshot of data i.e. snapshot isolation. Causal consistency provides the ability for clients to get session guarantees, including read-your-writes behavior in a given session.
Speculative execution model
In Raft, log entries are not applied to the state machine until they are known to be committed, which means that they will never be erased from the log. In contrast, in order to support the whole consistency spectrum under one roof, MongoDB replicas apply log entries to the database as soon as they are received. This means that a server may apply an operation in its log even if the operation is uncommitted. This allows MongoDB to provide the “local” read concern level. As soon as a write operation is applied on some server, a “local” read is able to see the effects of that write on that server, even before the write is majority committed in the replica set. Recall that in MongoDB, the database itself is the state machine, and entries in the oplog correspond to operations on this state machine. Without the log being applied to the database, the local read would not be possible.
Data Rollback
MongoDB’s speculative execution model makes it necessary for the replication system to have a procedure for data rollback in case these log entries may need to be erased from the log due to a leader takeover. In a protocol like Raft, this rollback procedure consists of truncating the appropriate entries from a log. In MongoDB, in addition to log truncation, it must undo the effects of the operations it deletes from a log. This requires modifying the state of the database itself, and presents several engineering challenges. The process is initiated by the rollback node when it detects that its log has diverged from the log of the sync source node, i.e. its log is no longer a prefix of that node’s log. The rollback node will then determine the newest log entry that it has in common with the sync source. The timestamp of this log entry is referred to as t_common. The node then needs to truncate all oplog entries with a timestamp after t_common, and modify its database state in such a way that it can become consistent again.
Recover to Timestamp (RTT) Algorithm
Since MongoDB version 4.0, the WiredTiger storage engine has provided the ability to revert all replicated database data to some previous point in time. The replication system periodically informs the storage engine of a stable timestamp (t_stable), which is the latest timestamp in the oplog that is known to be majority committed and also represents a consistent database state. The algorithm works as follows. First, the rollback node asks the storage engine to revert the database state to the newest stable timestamp, t_stable. Note that t_stable may be a timestamp earlier than the rollback common point, t_common. Then, the node applies oplog entries forward from t_stable up to and including t_common. From t_common onwards normal oplog replication commences.
Consistency spectrum
To understand the impact of readConcern on the rest of the system, it is necessary to discuss reads in the underlying WiredTiger storage engine. All reads in WiredTiger are done as transactions with snapshot isolation. While a transaction is open, all later updates must be kept in memory. Once there are no active readers earlier than a point in time t, the state of the data files at time t can be persisted to disk, and individual updates earlier than t can be forgotten. Thus a long-running WiredTiger transaction will cause memory pressure, so MongoDB reads must avoid performing long-running WiredTiger transactions in order to limit their impact on the performance of the system.

Local Reads
Reads with readConcern “local” read the latest data in WiredTiger. However, local reads in MongoDB can be arbitrarily long-running due to the reach of the query. In order to avoid keeping a single WiredTiger transaction open for too long, they perform “query yielding” (Algorithm 1): While a query is running, it will read in a WiredTiger transaction with snapshot isolation and hold database and collection locks, but at regular intervals, the read will “yield”, meaning it aborts its WiredTiger transaction and releases its locks. After yielding, it opens a new WiredTiger transaction from a later point in time and reacquires locks (the read will fail if the collection or index it was reading from was dropped). This process ensures that local reads do not perform long-running WiredTiger transactions, which avoids memory pressure. The consequence is that local reads do not see a consistent cut of data, but this is acceptable for this isolation level.
Majority Reads
Reads with readConcern level “majority” also perform query yielding, but they read from the majority commit point of the replica set. Each time a majority read yields, if the majority commit point has advanced, then the read will be able to resume from a later point in time. Again, majority reads may not read a consistent cut of data. A majority read could return 5 documents, yield and open a WiredTiger transaction at a later point in time, then return 5 more documents. It is possible that a MongoDB transaction that touched all 10 documents would only be reflected in the last 5 documents returned, if it committed while the read was running. (It is worth recalling the fractured read problem in Facebook TAO at this point.) This inconsistent cut is acceptable for this isolation level. Since the read is performed at the majority commit point, we guarantee that all of the data returned is majority committed.
It is instructional to contrast MongoDB's majority readConcern with Cassandra's majority reads here. Cassandra’s QUORUM reads do not guarantee that clients only see majority committed data, differing from MongoDB’s readConcern level “majority”. Instead Cassandra’s QUORUM reads reach out to a majority of nodes with the row and return the most recent update, regardless of whether that write is durable to the set.
Another point to note here is that the combination of write-majority and read-majority does not give us linearizability. This is to be expected in any Raft/Paxos state machine replication. In order to get to linearizability, there is need for an additional client-side protocol as we discussed in our Paxos Quorum Reads paper.
Snapshot Reads
Reads with readConcern level “snapshot” must read a consistent cut of data. This is achieved by performing the read in a single WiredTiger transaction, instead of doing query yielding. In order to avoid long-running WiredTiger transactions, MongoDB kills snapshot read queries that have been running longer than 1 minute.
Experiments
The paper performed three experiments on 3-node replica sets using different geographical distributions of replica set members. Each experiment performed 100 single-document updates, and all operations specified that journaling was required in order to satisfy the given writeConcern.
Local Latency Comparison
In this experiment, all replica set members and the client were in the same AWS Availability Zone (roughly the same datacenter) and Placement Group (roughly the same rack). All replica set members were running MongoDB 4.0.2 with SSL disabled. The cluster was deployed using sys-perf, the internal MongoDB performance testing framework.

Cross-AZ Latency Comparison
In this experiment, all replica set members were in the same AWS Region (the same geographic area), but they were in different Availability Zones. Client 1 was in the same Availability Zone as the primary, and Client 2 was in the same Availability Zone as a secondary.

Cross-Region Latency Comparison
In this experiment, all replica set members were in different AWS Regions. The primary was in US-EAST1, one secondary was in EU-WEST-1, and the other secondary was in US-WEST-2. Client 1 was in US-EAST1, and Client 2 was in EU-WEST-1.

Cross-layer optimization opportunities
The paper also discusses about multidocument transactions. I find it very interesting to think about how MongoDB interplays with the underlying WiredTiger storage system. (I read more about this in the "Verifying Transactional Consistency of MongoDB" paper.) This paper only scratches the surface on this, but having a powerful storage engine like WiredTiger opens the way to powerful cross-layer optimization opportunities.
Speculative majority and snapshot isolation for multi statement transactions
MongoDB uses an innovative strategy for implementing readConcern within transactions that greatly reduced aborts due to write conflicts in back-to-back transactions. When a user specifies readConcern level “majority” or “snapshot”, the returned data is guaranteed to be committed to a majority of replica set members. Outside of transactions, this is accomplished by reading at a timestamp at or earlier than the majority commit point in WiredTiger. However, this is problematic for transactions: It is useful for write operations to read the freshest version of a document, since the write will abort if there is a newer version of the document than the one it read. This motivated the implementation of “speculative” majority and snapshot isolation for transactions. Transactions read the latest data for both read and write operations, and at commit time, if the writeConcern is w:“majority”, they wait for all the data they read to become majority committed. This means that a transaction only satisfies its readConcern guarantees if the transaction commits with writeConcern w:“majority”.
Waiting for the data read to become majority committed at commit time rarely adds latency to the transaction, since if the transaction did any writes, then to satisfy the writeConcern guarantees, we must wait for those writes to be majority committed, which will imply that the data read was also majority committed. Only read-only transactions require an explicit wait at commit time for the data read to become majority committed. Even for read-only transactions, this wait often completes immediately because by the time the transaction commits, the timestamp at which the transaction read is often already majority committed.







Comments