Keep CALM and CRDT On
This paper is from VLDB'22. It focuses on the read/querying problem of conflict-free replicated data types (CRDTs). To solve this problem, it proposes extending CRDTs with a SQL API query model, applying the CALM theorem to identify which queries are safe to execute locally on any replica. The answer is of no surprise: monotonic queries can provide consistent observations without coordination.
CRDTs
To ensure replica consistency in distributed systems, a common method is to enforce strong consistency at the storage layer using traditional distributed coordination techniques such as consensus or transactions. However, for some applications this may create concerns about latency and availability (especially when a quorum is not readily available). Alternatively, developers can use weakly consistent storage models that don't require coordination, but they must ensure consistency at the application level. This is where CRDTs enter the picture, as they can provide a straightforward way to guarantee state convergence.
CRDTs are data structures that can be replicated across nodes, where replicas can be updated independently and in parallel, without the need for coordination, and with a guarantee that no conflicts will occur. Some examples of CRDTs are:
- counters, like the number of likes on a post or the number of visitors on a website. Counters can be incremented or decremented by any replica, and they converge to the correct value by using a merge function that takes the maximum or the sum of the local values.
- sets, such as the tags on a blog post or the members of a chat room. Sets can support operations such as adding or removing items by any replica, and they converge to the correct set by using a merge function that takes the union or the difference of the local sets.
Think of CRDTs as shared documents that can be edited by multiple people at the same time, such as Google Docs. Each person has their own copy of the document on their device, and they can make changes to it without waiting for others to finish their edits. The changes are then synced with other copies over the network, and any conflicts are resolved automatically by using some rules that ensure consistency. For example, if two people insert text at the same position, one of them will appear before the other based on some timestamp or identifier. This way, everyone can see the same version of the document eventually, without losing any information or having to manually merge their edits.
Some successful applications of CRDTs in practice are:
- Distributed systems: Akka, Redis, and Basho Riak provide CRDTs as built-in data structures.
- Collaborative editors: CRDTs are used to replicate documents for collaborative editing with latency and fault-tolerance challenges. Examples of such systems are Peritext and Automerge.
- Database systems: CRDTs are used in database systems that support weakly consistent storage models. Examples of such systems are FlightTracker at Facebook and AntidoteDB.
Designing a CRDT centers around providing a function to merge any two replicas, with the requirement that this single function is associative, commutative and idempotent (ACI), and defining atomic operations that clients can use to update a replica.
Early read problem
But there is trouble in paradise. The cause of this conflict is reads.
As Helland and Campbell point out "Reads are annoying!", because they often do not commute with other actions. The below example from the paper highlights that CRDTs offer Schrödinger consistency guarantees: they are only consistent if they are not observed.
Example 1 (The Potato and the Ferrari, a.k.a. Early Read).
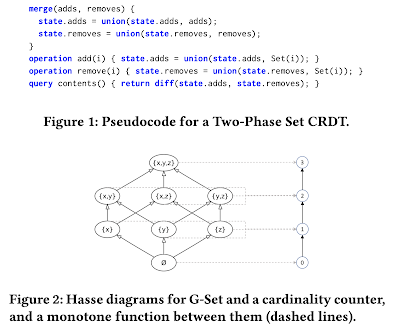
A canonical CRDT is the Two-Phase Set (2P-Set) , which is a pair of sets (A, R) that track items to be added (A) and removed (R). The merge function for two 2P-Sets is defined simply as the pairwise union, (A1 ∪ A2, R1 ∪ R2) and is patently ACI. This scheme was used in the well-known Amazon Dynamo shopping cart example.
Implicit in this design is a query Q = A-R returning the intended contents of the set. Consider a scenario where a shopper adds a potato and a Ferrari to their cart, then removes the Ferrari, and “checks out” by computing the query Q. In one or more replicas of the 2P-Set, the checkout request could arrive before the removal of the sports car. This truly expensive consistency bug arises when the query “reads” the state of the 2P-Set “too early”, before all the removals have eventually arrived. And there is no way to know that all the removals have indeed arrived without the coordination that CRDTs supposedly do not need.
The unconstrained nature of queries in CRDTs raises an intriguing question: can we develop a more formal query model that makes it possible to precisely define when execution on a single replica yields consistent results?
Monotonic queries
The answer is "Yes, with monotonic queries we can do that". If you have been following the CALM work, you would be expecting this answer.
Some examples of monotonic queries are:
- A query that checks if the number of gift card purchases over $100 in a set of transactions has exceeded 50 items. This query is monotonic because the true result cannot be changed by any subsequent updates. The property is a stable property.
- A query that counts the number of actions taken by a shopping cart user. This query is monotonic because the number of actions can only increase over time.
- A query that selects, projects, unions, or intersects data from a grow-only set. These operations are monotone with respect to the set partial order.
Some examples of non-monotonic queries are:
- A query that computes the difference between two sets, such as the contents of a shopping cart. This query is non-monotonic because the result can change depending on the order and arrival of updates. (See the early read problem above.)
- A query that aggregates data, such as computing the average or maximum value. This query is non-monotonic because the result can vary depending on the data distribution and sample size.
Enabling Fast And Safe CRDT Systems
The paper proposes a shift in perspective from an object-oriented view of CRDTs to a “database” view of them: breaking CRDTs up into a query model and a data store that separates their logical and physical representations.
This may sound like a trite point, but it is useful and practical. CRDTs had been too baked into the application logic. This perspective shift advocates managing CRDTs as an external service. By shifting from an object-oriented view of CRDTs to a database view, the paper argues that the following benefits are more attainable.
- We can reduce the burden of reasoning about consistency and replication by delegating it to the CRDT data store. By allowing separation of logical and physical data representations, we can optimize compression, garbage collection, and delta propagation.
- We can achieve richer, more uniform guarantees for queries over CRDTs by applying monotonicity results from the CALM theorem. We can simplify the interaction model for developers by providing a declarative query language that can leverage existing SQL tools and techniques.
Yes, you read it right. $QL is on the money again. It can provide major benefits for performing queries over CRDTs.
Firstly, SQL is a familiar and widely used query language that many developers already know and use. Secondly, SQL has a clear syntax that makes it easy to identify whether a query is monotone or not, which is important for determining the consistency and efficiency of the query execution. Finally SQL can leverage existing query optimization techniques that take advantage of monotonicity, such as streaming joins, barrier stages, and incremental view maintenance. SQL can support rich expressions that can manipulate the semi-lattice structures used inside CRDTs, and provide a declarative way to specify the desired observations on CRDTs.
The paper says that using relational-style languages to query CRDTs also fits well into recent research exploring alternate models of CRDTs. In particular, there has been a recent push to define CRDTs as Datalog queries over sets of operations being gossiped across nodes. In such a model, issuing queries in a relational-style language naturally fits into the execution model, and opens up the opportunity for further end-to-end optimizations such as using incremental view maintenance to identify efficient ways to propagate the effects of operations to queries.
Concluding remarks
Unfortunately, there is no concrete implementation of SQL for CRDTs yet. The paper points to the promised land but does not walk us there. This is part of ongoing work for the authors. Note that, for nonmonotonic queries, we pretty much default to coordination again. But, avoiding the need for coordination as much as possible would be a good win for any distributed system.





Comments