Kora: A Cloud-Native Event Streaming Platform For Kafka
This paper from VLDB'23 (awarded the Best Industry Paper) describes how Confluent built Kora, to provide Kafka as a managed cloud event streaming platform.
Kora combines best practices to deliver cloud features such as high availability, durability, scalability, elasticity, cost efficiency, performance, multi-tenancy. For example, the Kora architecture decouples its storage and compute tiers to facilitate elasticity, performance, and cost efficiency. As another example, Kora defines a Logical Kafka Cluster (LKC) abstraction to serve as the user-visible unit of provisioning, so it can help customers distance themselves from the underlying hardware and think in terms of application requirements.
The writing of the paper could be much better. I think the paper fails to symphatize with the reader, who lacks the context about Kafka in the first place, and rushes in to explaining the mechanics how Kora makes Kafka a cloud managed offering. The motivation and use cases of Kafka could have been better explained. I found that I lacked understanding of concepts like Kafka brokers, which was defined as a subclause in the paper. The paper would have benefited a lot from providing a concrete running example/case-study.
On the technical side, I was disappointed to see the paper did not provide much discussion of the algorithms used, or raised the question about if there could be better design/protocol choices made in the problem space. One thing that bothered me is the discussion about In-Sync-Replicas (ISR). The paper said that Kafka is vulnerable because any straggler in ISR can slow down Kafka, and offered as a solution to detect and remover such stragglers. Why are other solutions, such as quorum-based techniques, not considered?
From protocols design perspective, Kora provides incremental improvements over the Kafka protocols. What would have been much more exciting would be a redesign of the sort that Delos did for traditional SMR to provide a cloud-native SMR version.
Architecture
Kafka organizes events into topics, each of which is partitioned for higher throughput (*linearizability is lost with partitions*). A topic partition is structured as a persistent, replicated log of events: each copy of the log is known as a replica. Producers write to the end of the log while consumers can read from any offset. Kafka is optimized for consumers reading at the end of the log, which is the most common access pattern. Deployments have often huge fan-out; it is common to have multiple consumer applications consuming the same event stream.
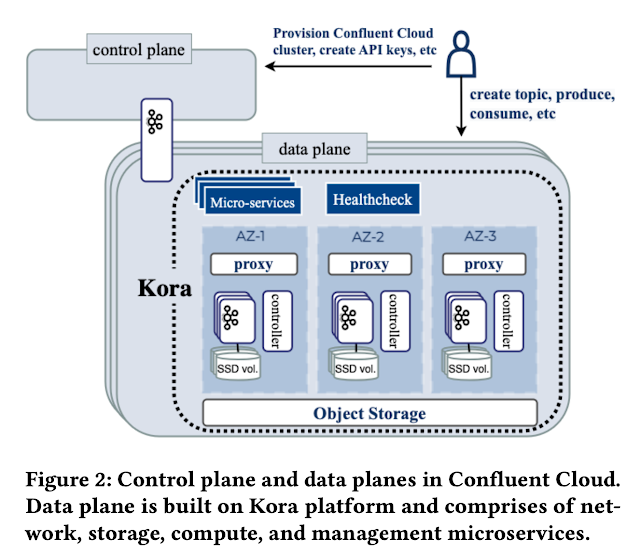
Kora has a centralized control plane and a decentralized data plane. The control plane is responsible for provisioning resources for the data plane, which consists of independent physical Kafka clusters (PKCs). Each Kora instance hosts a single PKC comprising of network, storage, compute, and management microservices. A PKC may host many logical Kafka cluster (LKCs), which serves as the user-visible unit of provisioning and isolation.
Controllers manage cluster metadata, such as replica assignments. Brokers are responsible for hosting topic partition data. The proxy layer routes to brokers using Server Name Identification (SNI).
Kora deploys two significant departures from Kafka architecture: 1. Metadata has been pulled out of Zookeeper and into an internal topic, and 2. the storage layer now has two tiers: local volumes on brokers & an object store (e.g., S3). Let's talk about these two below.
Traditionally, the controller was co-located with brokers. Any broker was capable of becoming the controller through a ZooKeeper election. But on larger clusters, the co-location could be problematic since the controller's work can be substantial, and loading a new controller from Zookeeper was not cheap. So Kora replaced ZooKeeper with Kafka-Raft (Kraft) architecture. Rather than using Zookeeper, metadata in KRaft is stored in an internal topic partition using Raft. The centralized controller is elected as the leader of this partition. The replicas follow the log and build the metadata state so that they can be ready to take over leadership.
Ok, fine, but couldn't most of these be achieved while staying with ZooKeeper and using ZooKeeper follower/learners? I was expecting the reason to move out of ZooKeeper to be about ZooKeeper management overheads, and the unnecessary total-order/bottleneck imposed by ZooKeeper even across partitions. But there was no discussion about these, and the paper pretty much used the above paragraph to explain the change.
On the storage disaggregation front, here is the story. Traditionally, in Kafka each replica maintained its own complete copy of the entire log of events in local volumes. In Kora, although new event data is first written to local disks as before, as the data ages, it is moved to a second tier, a much cheaper object store, such as AWS S3. This means local volumes can be much smaller since they only need to retain the active log data, so we SSDs with better performance can be employed here. This also solves the rebalancing problem. There is no need to move archived data, we only need to move the smaller active set on the local volume. Data on the object storage is accessible by any replica.
The paper includes a long section called cloud-native building blocks, where it discusses how to measure broker load/utilization, how the controllers perform load balancing of the replicas, how observability works, and how straggling brokers in ISR is decommissioned.
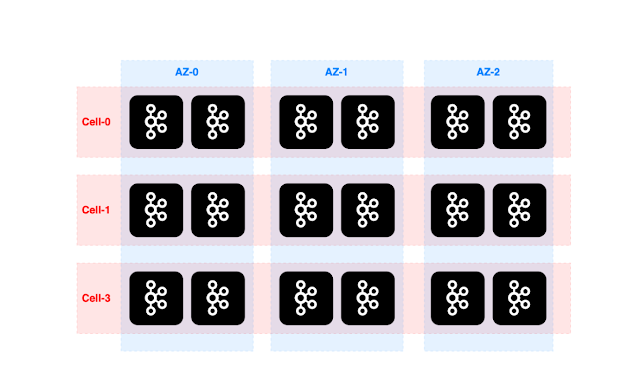
There is another section on multitenancy, where the paper discusses applying backpressure and auto-tuning tenant quotas on the broker, and how Kora adopts the cell architecture idea (which is an AWS best practice recommendation to limit blast radius) to limit blast radius.
The DynamoDB ATC'22 paper we covered recently, "Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service (USENIX ATC 2022)", provided a great coverage of challenges of running cloud-native multi-tenant database service while providing operational excellence. It talked about techniques to deal with fairness, traffic imbalance across partitions, monitoring, and automated system operations without impacting availability, performance, and predictability.





Comments