Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service (USENIX ATC 2022)
This paper, which appeared in USENIX ATC'22 last week, describes the evolution of the design and implementation of DynamoDB in response to experiences operating it since its launch in 2012.
DynamoDB has massive scale. In 2021, during the 66-hour Amazon Prime Day shopping event, Amazon
systems made trillions of API calls to DynamoDB, peaking at 89.2 million
requests per second. DynamoDB powers Alexa, Amazon.com sites, and all Amazon fulfillment centers. Many AWS services such as AWS Lambda, AWS Lake Formation, and Amazon SageMaker are built on DynamoDB. Moreover, hundreds of thousands of customer applications also use DynamoDB.
First some clarification is in order. DynamoDB != Dynamo. DynamoDB's architecture does not share much with that of the Dynamo system (2007). DynamoDB uses MultiPaxos for replication, for God's sake. Dynamo was a single-tenant system and teams were responsible for managing their own Dynamo installations. The resulting operational complexity became a barrier to adoption. To address the problem, the engineers at AWS decided combine the best parts of the original Dynamo design (incremental scalability and predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store). This led to launching Amazon DynamoDB in 2012.
This paper is not that much about the DynamoDB architecture (it omits discussion of multikey transactions and secondary indices); it is more about achieving operational excellence while operating arguably the largest scale cloud database ever. DynamoDB needs to deal with operational issues related to fairness, traffic imbalance across partitions, monitoring, and automated system operations without impacting availability or performance. Reliability is essential, as even the slightest disruption can significantly impact customers. Consistent performance (i.e., predictability) at any scale is very important to DynamoDB customers, because unexpectedly high latency requests can amplify through higher layers of applications that depend on DynamoDB and lead to a bad customer experience.

Architecture
A DynamoDB table is a collection of items, and each item is a collection of attributes. Each item is uniquely identified by a primary key, which contains a partition key or a partition and sort key (a composite primary key).

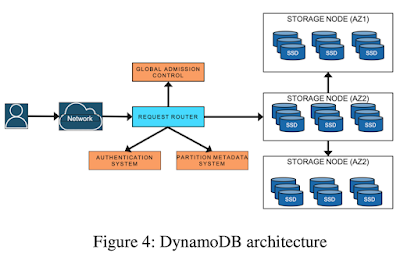
A DynamoDB table is divided into multiple partitions to handle the throughput and storage requirements of the table. Each partition of the table hosts a disjoint and contiguous part of the table's key-range. Each partition has multiple replicas distributed across different Availability Zones (AZs) for high availability and durability.
The replicas for a partition form a replication group. The replication group uses MultiPaxos for leader election and consensus. A write is acknowledged to the application once the leader hears that a quorum persists the log record to their local write-ahead logs. Only the leader replica can serve write and strongly consistent read requests. Reading from a replica gives an eventually consistent read.
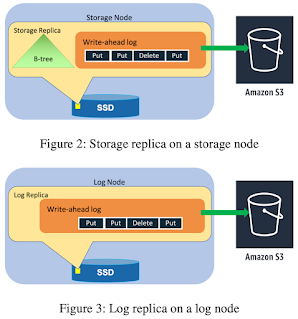
Journey from provisioned to on-demand
In the original DynamoDB release, customers explicitly specified the throughput that a table required in terms of read capacity units (RCUs) and write capacity units (WCUs). For items up to 4 KB in size, one RCU can perform one strongly consistent read request per second. For items up to 1 KB in size, one WCU can perform one standard write request per second. RCUs and WCUs collectively are called provisioned throughput. This early version tightly coupled the assignment of both capacity and performance to individual partitions, which led to challenges.
The paper describes how friction points in the provisioning model is smoothed over a decade by adding bursting, adaptive capacity allocation, and global admission control. The team did not stop addressing all cornercases and eventually released on-demand tables to remove the burden from customers of figuring out the right provisioning for tables. The ability to balance based on consumed capacity effectively means DynamoDB can place partitions of on-demand tables intelligently to avoid any node level limits and provide frictionless and limitless on-demand scalability, all this while respecting performance isolation in a multitenant deployment.
Durability and correctness
DynamoDB makes extensive use of checksums to detect silent errors. By maintaining checksums within every log entry, message, and log file, DynamoDB validates data integrity for every data transfer between two nodes. Every log file and manifest file are uploaded to S3 with a content checksum. DynamoDB also continuously verifies data at rest (e.g., by using the scrub process) to detect any silent data errors or bit rot in the system.
DynamoDB also supports backup and restore to protect against any logical corruption due to a bug in a customer's application. Using point-in-time restore, customers can restore the contents of a table that existed at any time in the previous 35 days to a different DynamoDB table in the same region.
The core replication protocol of DynamoDB was specified using TLA+. When new features that affect the replication protocol are added, they are incorporated into the specification and model checked. Model checking has allowed the team to catch subtle bugs that could have led to durability and correctness issues before the code went into production.
Availability
DynamoDB is designed for 99.999 percent availability for global tables and 99.99 percent availability for Regional tables. Availability is calculated for each 5-minute interval as the percentage of requests processed by DynamoDB that succeed. DynamoDB also measures and alarms on availability observed on the client-side by using internal Amazon services and canary applications as clients.
DynamoDB handles distributed deployment challenges with "read-write deployments". Read-write deployment is completed as a multi-step process. The first step is to deploy the software to read the new message format or protocol. Once all the nodes can handle the new message, the software is updated to send new messages. New messages are enabled with software deployment as well. Read-write deployments ensure that both types of messages can coexist in the system. Even in the case of rollbacks, the system can understand both old and new messages.
All the deployments are done on a small set of nodes before pushing them to the entire fleet of nodes. The strategy reduces the potential impact of faulty deployments. DynamoDB sets alarm thresholds on availability metrics; if error rates or latency exceed the threshold values during deployments, the system triggers automatic rollbacks.
To improve system stability, DynamoDB prioritizes predictability over absolute efficiency. While components such as caches can improve performance, DynamoDB does not allow them to hide the work that would be performed in their absence, ensuring that the system is always provisioned to handle the unexpected. Marc Brooker mentions this in his recent post on this DynamoDB, and gives a more detailed explains in his earlier post on metastability and caches.
Evaluations
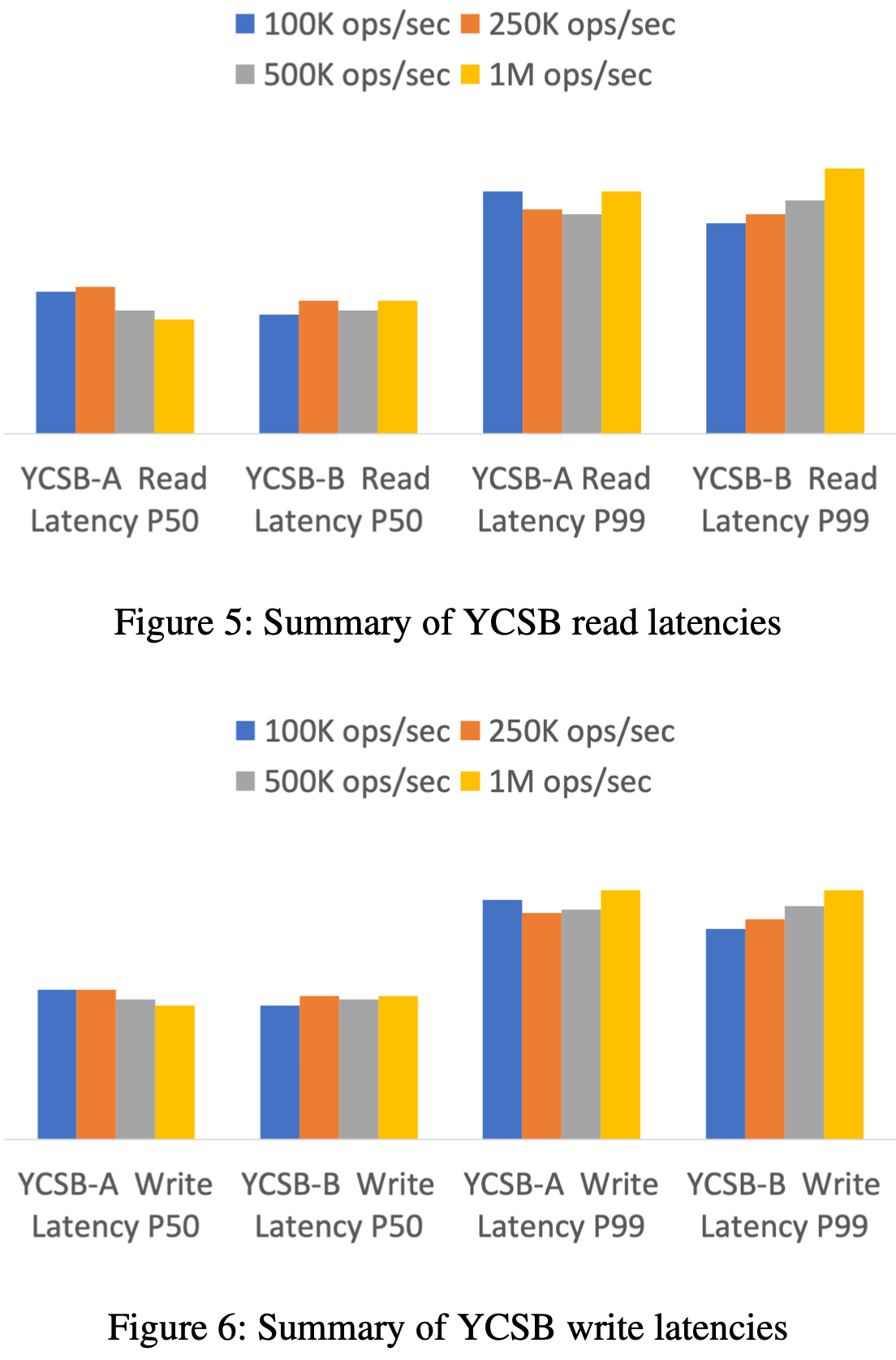
Recap
DynamoDB uniquely integrates the following six fundamental system properties:
- DynamoDB is a fully managed cloud-native NoSQL database. DynamoDB handles resource provisioning, automatically recovers from failures, encrypts data, manages software upgrades, performs backups.
- DynamoDB employs a multi-tenant architecture. Resource reservations, tight provisioning, and monitored usage provide isolation between the workloads of co-resident tables.
- DynamoDB achieves boundless scale for tables. DynamoDB spreads an application's data across more servers as the amount of data storage and the demand for throughput requirements grow.
- DynamoDB provides predictable performance. DynamoDB handles any level of traffic through horizontal scaling and automatically partitions and re-partitions data to meet an application's I/O performance requirements, providing latencies in the low single-digit millisecond range for put/get of a 1 KB item in the same AWS region.
- DynamoDB is highly available. DynamoDB offers an availability SLA of 99.99 for regular tables and 99.999 for global tables (where DynamoDB replicates across tables across multiple AWS Regions).
- DynamoDB supports flexible use cases. Developers can request strong or eventual consistency when reading items from a table.





Comments