Speedy Transactions in Multicore In-Memory Databases
This paper is from SOSP'13. The Polyjuice paper, which we studied last week, built on the Silo codebase and commit protocol, which led me to read the Silo paper.
Silo is a single-node multi-core in-memory database. It avoids all centralized contention points, including centralized transaction ID (TID) assignment. Silo's key contribution is a commit protocol based on optimistic concurrency control (OCC) that provides serializability while avoiding all shared-memory writes for records that were only read. Logging and recovery is provided by linking periodically-updated epochs with the commit protocol. Silo achieves almost 700,000 transactions per second on a standard TPC-C workload mix on a 32-core machine, as well as near-linear scalability. That is pretty impressive over 2013 hardware. The Silo paper got 445 citations in 10 years. That is also impressive.
So let's dive in.
Architecture
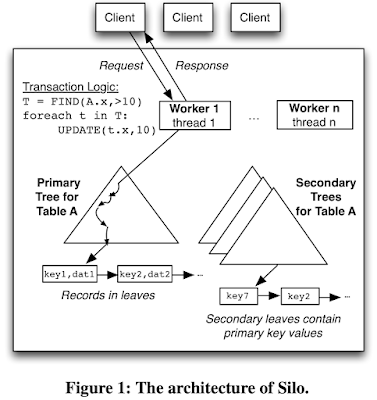
Silo's organization is typical of databases. Tables are implemented as collections of index trees, including one primary tree and zero or more secondary trees per table. Each record in a table is stored in a separately-allocated chunk of memory pointed to by the table's primary tree. In secondary indexes, the index key maps to a secondary record that contains the relevant record's primary key(s). Thus, looking up a record by a secondary index requires two tree accesses.
Each index tree is stored in an ordered key-value structure based on Masstree (a fast concurrent B-tree-like structure optimized for multicore performance). Masstree read operations never write to shared memory; instead, readers coordinate with writers using version numbers and fence-based synchronization (as we will discuss below).
Silo pins one worker thread per physical core of the server machine. Trees are stored in (shared) main memory, in Silo any worker can access the entire database. Silo clients issue one-shot requests. In other words, requests are stored procedures written in C++. All parameters are available when a request begins, and the request does not interact with its caller until it completes. The paper mentions that these requests could've also been written in SQL.
Design
Silo uses a variant of OCC. OCC writes to shared memory only at commit time, after the transaction's compute phase has completed; this short write period reduces contention. And thanks to the validation step, read-set records need not be locked.
Silo's OCC avoids most points of global synchronization, including that of centralized transaction ID (TID) assignment. Silo's OCC avoids any shared-memory writes for records that were only read, yet it achieves serializability, even supporting serializability with recovery. This is achieved by using periodically-updated epochs; epoch boundaries form natural serialization points. Epochs also help make garbage collection efficient and enable snapshot transactions.
Epochs
Silo is based on physical time periods called epochs. A global epoch number E is visible to all threads. A designated thread periodically advances E; other threads access E while committing transactions. E should advance frequently, but epoch change should be rare compared to transaction duration so that the value of E is generally cached. Silo updates E once every 40 ms. No locking is required to handle E.
Each worker w also maintains a local epoch number e_w. This can lag behind E while the worker computes, and is used to determine when it is safe to collect garbage. Silo requires that E and e_w never diverge too far: E −e_w ≤ 1 for all w.
TIDs
TIDs identify transactions and record versions, serve as locks, and detect conflicts. Each record contains the TID of the transaction that most recently modified it. TIDs are 64-bit integers. The high bits of each TID contain an epoch number, which equals the global epoch at the corresponding transaction’s commit time. The middle bits distinguish transactions within the same epoch. The lower three bits are status bits indicating a lock bit, latest-version bit, and absent bit.
Silo assigns TIDs in a decentralized fashion. A worker chooses a transaction’s TID only after verifying that the transaction can commit. At that point, it calculates the smallest number that is (a) larger than the TID of any record read or written by the transaction, (b) larger than the worker’s most recently chosen TID, and (c) in the current global epoch.
The TID order often reflects the serial order, but not always. Consider transactions t1 and t2 where t1 happened first in the serial order. If t1 wrote a tuple that t2 observed (by reading it or overwriting it), then t2’s TID must be greater than t1’s, thanks to (a) above.
But reads don't write TID to the record, so a t1 that reads a record would go undetected for t2 overwrites the value t1 saw. (This is called anti-dependency a write-after-read conflict.) A serializable system must order t1 before t2 even after a potential crash and recovery from persistent logs. To achieve this ordering, most systems require that t1 communicate with t2, such as by posting its read sets to shared memory or via a centrally-assigned, monotonically-increasing transaction ID, and incur a scalability bottleneck.
In Silo, TIDs do not reflect anti-dependencies (write-after-read conflicts) as well. If t1 merely observed a tuple that t2 later overwrote, t1’s TID might be either less than or greater than t2’s! Silo still achieves serializability to the face of recovery thanks to logging transactions in units of epochs, and releasing transaction acks/results to the clients at epoch boundaries. Even though transaction results always agree with a serial order, the system does not explicitly know the serial order except across epoch boundaries: if t1’s epoch is before t2’s, then t1 precedes t2 in the serial order. We will talk about epoch-based commit protocol below.
Commit protocol

The commit protocol is OCC based.
In Phase 1, the worker examines all records in the transaction’s write-set and locks each record by acquiring the record’s lock bit. To avoid deadlocks, workers lock records in a deterministic global order.
After all write locks are acquired, the worker takes a snapshot of the global epoch number E using a single memory access. Fences are required to ensure that this read goes to main memory (rather than an out-of-date cache), happens logically after all previous memory accesses, and happens logically before all following memory accesses. (On x86 and other total store order machines, however, these fences are compiler fences that do not affect compiled instructions; they just prevent the compiler from moving code aggressively.) The snapshot of the global epoch number is the serialization point for transactions that commit.
In Phase 2, the worker examines all the records in the transaction’s read-set (which may contain some records that were both read and written). If some record either has a different TID than that observed during execution, is no longer the latest version for its key, or is locked by a different transaction, the transaction releases its locks and aborts.
If the TIDs of all read records are unchanged, the transaction is allowed to commit, because we know that all its reads are consistent. The worker uses the snapshot of the global epoch number taken in Phase 1 to assign the transaction a TID as described earlier.
Finally, in Phase 3, the worker writes its modified records to the tree and updates their TIDs to the transaction ID computed in the previous phase. Each lock can be released immediately after its record is written. Silo must ensure that the new TID is visible as soon as the lock is released; this is simple since the TID and lock share a word and can be written atomically.
The paper argues Silo's OCC commit protocol's serializability by reducing to strict two-phase locking (S2PL). The main arguments for Silo's correctness are:
- it locks all written records before validating the TIDs of read records,
- it treats locked records as dirty and aborts on encountering them, and
- the fences that close Phase 1 ensure that TID validation sees all concurrent updates.
Silo also ensures that epoch boundaries agree with the serial order. That is, committed transactions in earlier epochs never transitively depend on transactions in later epochs. This holds because the memory fences ensure that all workers load the latest version of E before read validation and after write locking. Placing the load before read validation ensures that committed transactions’ read- and node-sets never contain data from later epochs; placing it after write locking ensures that all transactions in later epochs would observe at least the lock bits acquired in Phase 1. Thus, epochs obey both dependencies and anti-dependencies.
Other database operations
Implementing an entire database is hard. There are many other details the paper discusses, including how to correctly modify record data, how to correctly access record data, how to deal with deleted records, how to deal with insert operations, how to implement secondary index update operations, how to ensure durability to disks, how to perform recovery, how to do garbage collections (thanks epochs!) etc. I skip these and refer to you to the paper. I will just cover range queries support and snapshot queries as they are most interesting.
Range queries are complicated by the phantom problem: if we scanned a particular range but only kept track of the records that were present during the scan, membership in the range could change without being detected by the protocol, violating serializability. The typical solution to this problem in database systems is next-key locking, which requires locking for reads, and conflicts with Silo’s goals. Silo deals with this issue by taking advantage of the underlying B+-tree’s version number on each leaf node. A scan on the interval [a,b), in addition to registering all records in the interval in the read-set, also creates a node-set. It adds the leaf nodes that overlap with the key space [a, b) to the node-set along with the version numbers examined during the scan. Phase 2 checks that the version numbers of all tree nodes in the node-set have not changed, which ensures that no new keys have been added or removed within the ranges examined.
Snapshot transactions. Silo supports running read-only transactions on recent-past snapshots by retaining additional versions for records. These versions form a consistent snapshot that contains all modifications of transactions up to some point in the serial order, and none from transactions after that point. Snapshots are used for running snapshot transactions (and could also be helpful for checkpointing). Silo provides consistent snapshots using snapshot epochs. Snapshot epoch boundaries align with epoch boundaries, and thus are consistent points in the serial order. Snapshot epochs advance more slowly than epochs. Since snapshots are not free, a new snapshot is taken about once a second, i.e, after every 25 epochs.
Evaluation
The experiments were run on a single machine with four 8-core Intel Xeon E7-4830 processors clocked at 2.1GHz, yielding a total of 32 physical cores. Each core has a private 32KB L1 cache and a private 256KB L2 cache. The eight cores on a single processor share a 24MB L3 cache. The machine has 256GB of DRAM with 64GB of DRAM attached to each socket, and runs 64-bit Linux 3.2.0.
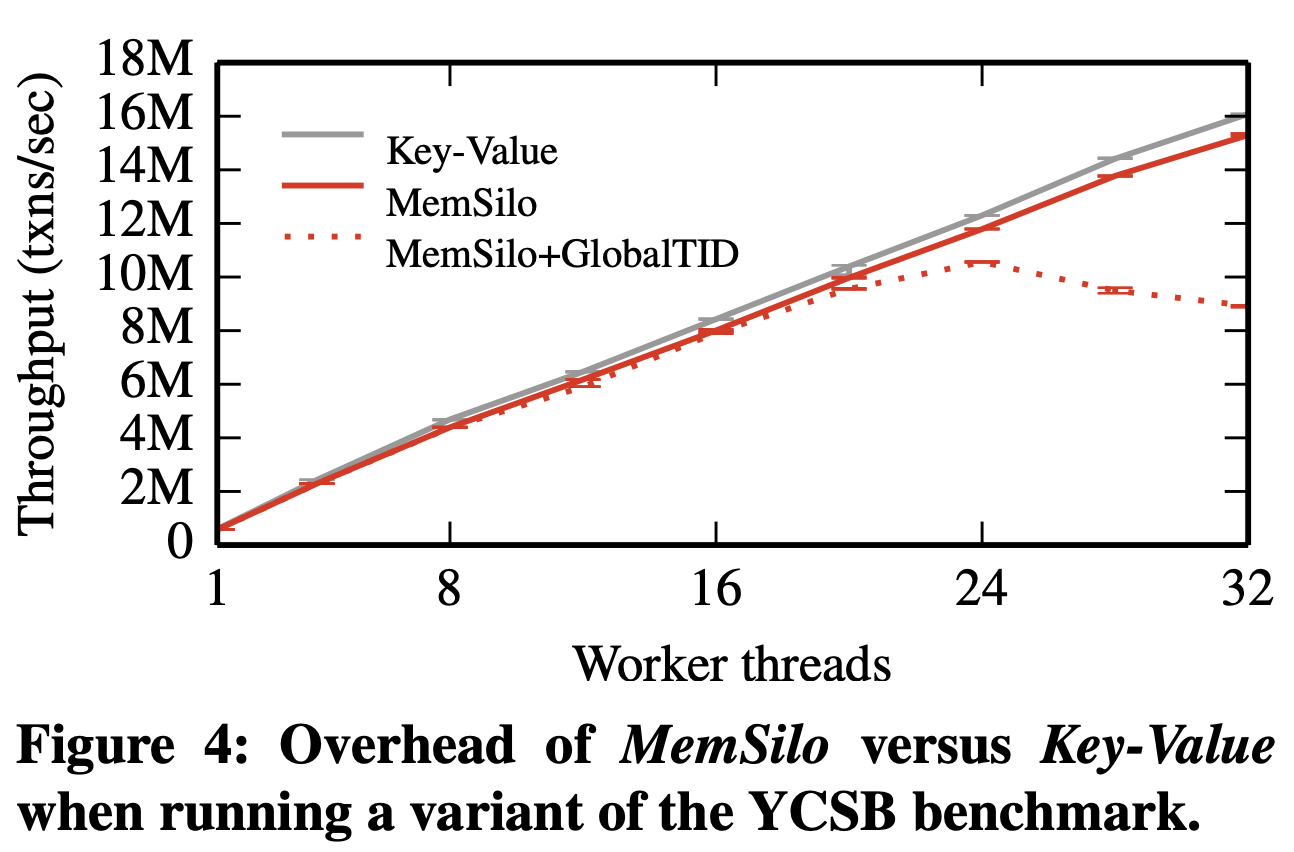
Figure 4 shows the results of running the YCSB benchmark on KeyValue (which is simply the concurrent B+-tree underneath Silo) and MemSilo. The overhead of MemSilo compared to Key-Value is negligible, which shows that the cost of Silo’s read/write set tracking for a simple key-value workload is low.
Figure 4 also shows the benefits of designing Silo to avoid a single globally unique TID assigned at commit time. MemSilo+GlobalTID generates TIDs from a single shared counter and suffers as the number of worker threads increase. This shows the importance of avoiding even a single global atomic instruction during the commit phase.

Conclusions
Silo's OCC is optimized for multicore performance, avoiding global critical sections and non-local memory writes for read operations. Its use of epochs facilitates serializable recovery, garbage collection, and efficient read-only snapshot transactions.
The important contribution of Silo's was to avoid any global critical section and to show an efficient way to deal with antidependencies (r-w conflicts) in a recovery-safe serializable manner. This was most explicitly explained at the end of the TID section above, go revisit it to make sure you understand these points.
The paper lists the following as future work:
- soft partitioning to improve performance on highly partitionable workloads
- fully implementing checkpointing, recovery, and replication
- investigating how to balance load across workers most effectively, perhaps in a way that exploits core-to-data affinity
- integrating into a full-featured SQL engine.
Silo is available as opensource if you like to play or you know rewrite it in Rust.
There is also a nice conference presentation for the paper, which would complement your understanding.
Discussion
Reading the paper
I enjoyed reading this paper, and learned a lot from it. But this is an overwhelming read with so many things to learn and dive deep. This felt like reading a PhD thesis because the paper takes a tour-de-force approach. Explaining the design and implementation of an entire database does not afford the best ergonomics for the reader. This paper is to be enjoyed in smaller portions over a span of several days.
I think it would be better to relegate a full coverage to a journal paper or a PhD thesis. If this paper focused on the commit protocol more, explained it better, talked about the tradeoffs more, anticipated and answered more questions about it, I would have loved it more.
Snapshot Isolation (SI) vs Serializability (SER)
If Silo used SI (a weaker isolation level) instead of SER, would it have to fudge with the commit-protocol to prevent the global synchronization (atomic_fetch_and_add instruction) related to TIDs?
SI only deals with w-w conflicts, so antidependencies would not be a problem an SI implementation would be concerned with. The phantom problem with range scans would also be avoided. What else would be different in a SI implementation? The epochs approach would still work well for durability and recovery, I think.
Related work
We had previously discussed Hekaton. The Silo paper has this to say for comparing to Hekaton.
Larson et al. recently revisited the performance of locking and OCC-based multi-version concurrency control (MVCC) systems versus that of traditional single-copy locking systems in the context of multicore main-memory databases. Their OCC implementation exploits MVCC to avoid installing writes until commit time, and avoids many of the centralized critical sections present in classic OCC. These techniques form the basis for concurrency control in Hekaton, the main- memory component of SQL Server. However, their design lacks many of the multicore-specific optimizations of Silo. For example, it has a global critical section when assigning timestamps, and reads must perform non-local memory writes to update other transactions’ dependency sets. It performs about 50% worse on simple key-value workloads than a single-copy locking system even under low levels of contention, whereas Silo’s OCC-based implementation is within a few percent of a key-value system for small key-value workloads.
Comments