A Study of Database Performance Sensitivity to Experiment Settings
This paper appeared in VLDB2022 and is a good followup to our TPC-E vs TPC-C post.
The paper investigates the following question: Many articles compare to prior works under certain settings, but how much of their conclusions hold under other settings?
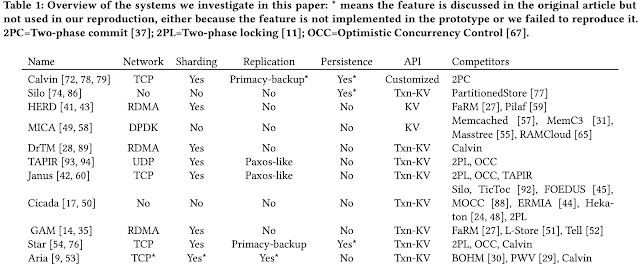
Their methodology is as follows. They used TPC-C and YCSB benchmarks as they are most widely used. They reproduced and evaluated 11 work (see Table 1). They then tuned benchmark parameters and system features to study effects on the performance of these work.
They find that the evaluations of these work (and conclusions drawn from them) are sensitive to experiment settings. They make some recommendations as to how to proceed for evaluation of future systems work.
The paper is well written and is an important contribution to systems work. In my summary below, I use many sentences from the paper verbatim.
Analysis of TPC-C results
TPC-C simulates the database of a wholesale company. It includes a number of warehouses, each maintaining stocks for 100,000 items and covering 10 districts with 3,000 customers in each. It consists of nine tables (WAREHOUSE, DISTRICT, CUSTOMER, HISTORY, ORDER, NEW-ORDER, ORDER-LINE, STOCK, and ITEM) and five types of transactions.
The New-Order transaction simulates the procedure of entering an order. It randomly selects a district from a warehouse, randomly selects 5 to 15 items, and randomly selects a quantity of one to ten for each item. For each item, it has 1% chance to order from another warehouse. This is how a New-Order works:
- It retrieves and increments a D_NEXT_O_ID value (i.e, the next available order number) from the DISTRICT table, uses the value to create an order, and inserts a row in both the NEW-ORDER and ORDER table. (The D_NEXT_O_ID value is a major contention point, since all New-Order transactions of the same district needs to update the same D_NEXT_O_ID.)
- Then for each item in the order, it retrieves the price from the ITEM table and updates the count in the STOCK table.
- Finally it inserts a new row for each item in the ORDER-LINE table. There is a 1% chance that the item is not found or its count is not sufficient, which will cause this transaction to rollback.
The Payment transaction updates the customer's balance and reflects the payment on the district and warehouse sales statistics. This is how it works:
- It randomly selects a district from a warehouse, randomly selects a customer from the district, and updates the balance and payment values in the corresponding tables.
- There is a 15% chance that the customer's resident warehouse is a remote warehouse.
The Order-status transaction queries a customer's last order. The delivery transaction selects the oldest order from the NEW-ORDER table for a given district, deletes this row, retrieves detailed information from the ORDER table, and then updates the ORDER-LINE table. The Stock-level transaction finds the recently sold items that have a stock level below a specified threshold.
Distribution of these five types of transactions should be: New-Order 45%, Payment 43%, Order-Status 4%, Delivery 4%, and Stock-Level 4%. TPC-C adds a wait time, including a keying time and a think time, before each transaction to simulate the user’s behavior of typing keyboard and thinking before making a decision. Each warehouse has ten terminals, one for each district, which means each warehouse can have at most ten concurrent transactions.

Table 2 shows results reported by previous papers (for work under consideration here). We see that the research systems play loose with respect to TPC-C rules. They don't use the wait-time at all. Some of them also run only two types of transactions (i.e. New-Order and Payment). The paper warns that TPC-C numbers with and without wait time are not comparable, since they stress test different components.

Impact of wait time. With 10 concurrent users per warehouse and with the wait time, it is possible to achieve a throughput of only 0.48 transactions/second per warehouse. This very low limitation on the throughput per warehouse means that to get a higher throughput, an experimenter must use many warehouses: that's why OceanBase and Oracle use millions of warehouses. For such a workload, which stores a large amount of data but has low throughput requirement per GB of data, storing data in SSDs can meet the throughput requirement. This shows that vanilla TPC-C is essentially an I/O intensive benchmark with a low contention level.
Impact of contention level. In TPC-C, the contention level can be determined by two factors: (1) the number of concurrent users per warehouse, and (2) New-Order and Payment transactions with probability of accessing remote warehouses. The results in Figure 1 show that the performance of the systems are highly sensitive to these parameters.
Impact of network and disk I/Os. Using fewer warehouses, more cross-warehouse transactions, more workers/users per warehouse, and no wait time will increase the contention level. Performing I/Os while holding a lock is particularly problematic for contended. Systems which can release locks earlier or reduce the number of aborts will have advantages in such a setting. Using interactive transactions or running protocols like 2PC or Paxos will bring significant overhead to both low-contention and high-contention settings.

Summary of tuning TPC-C. The throughput numbers of different systems under different settings can vary drastically: in Table 2, on one extreme, MySQL stores data on hard drives and can only reach 363 transactions per second; on the other extreme, a single-node in-memory engine can reach millions of transactions per second; other systems can lie somewhere in the middle depending on their settings.
We can tune TPC-C to test pretty much every key component: we could use it to test disk throughput if we ensure data does not fit into DRAM; we could use it to test network stack if we run interactive transactions, 2PC, Paxos, etc and choose the number of warehouses so that they can fit into DRAM but do not cause a high contention; we could use it to test CPU speed or DRAM bandwidth if we don’t test with the network stack; finally we could use it to test concurrency control if we incorporate a high contention level as discussed above. While such versatility is helpful to evaluate a variety of systems, it creates challenges to interpret performance numbers and compare different systems.
Analysis of YCSB results
Yahoo! Cloud Serving Benchmark (YCSB) primarily targets systems with key-value like interface. It first populates the target system with key-value pairs and then measures the system with Insert, Update, Read, and Scan operations.
Since YCSB only touches a single KV in each operation except Scan, it is not suitable to measure systems that support transactions. To address this problem, later works build YCSB+T, by encapsulating a number of YCSB operations into a single transaction. Table 3 shows YCSB results reported by previous papers. Workloads that use Zipfian distribution can let a large percentage of requests focus on a small number of keys and it has a parameter to tune such skewness.

Figure 6 shows results from evaluating the reproduced systems under different settings. This work did not test any persistent KV stores, and it is possible that storage I/Os are bottlenecks for persistent KV stores under YCSB.

Impact of Network Stack. For system processing large KVs, the bottleneck is likely to be network bandwidth; for system processing small KVs, the bottleneck is likely to be the CPU to process network packets. However, for the latter case, we can batch multiple small KVs in a single request: in this case, the bottleneck is either the network bandwidth or the in-memory engine.
Impact of Skewness. The impact of skewed access on the throughput varies, depending on system design and implementation on whether to use concurrency control or to tie key ranges to processes/threads has a significant impact. The latter performs better under a highly skewed workload, and its throughput can exceed the speed of even RDMA or DPDK stacks, making these stacks the bottleneck; the former has a significant performance degradation under a highly skewed workload, in which case its throughput may be lower than the RDMA or DPDK stacks. However, it’s unclear whether the latter design can support transactions accessing multiple KVs.
Impact of Read/Write ratio. For a skewed workload, the Read/Write ratio has a significant impact on contention level. Workloads with more reads are more advantageous, since Read operations on the same key can execute concurrently. If either network bandwidth or packet rate is the bottleneck, a higher write ratio will incur more packets if the system needs to replicate writes but has no significant impact if the system does not replicate writes. If contention is the bottleneck, a higher write ratio or a higher skewness will incur a higher contention.
Discussion
The paper has a nice discussion section, where they propose ways to alleviate the problem of evaluations being sensitive to system and benchmark parameter configurations.
They mention two directions: the first is to encourage extensive experiments under a variety of settings; the second is to limit the values of experiment parameters. They are quick to mention neither of these is perfect: the first one is cumbersome on researchers/developers, and in the second one it is unclear what parameters are the most salient and realistic.
I found this suggestion really important: "Instead of just documenting experiment settings (e.g., our experiments use 8 warehouses and 32 threads), an article may provide an explicit explanation about the implication of these settings, e.g., what components they stress." The point of the evaluation section is not to give numbers and compare those with numbers from other papers as part of a pissing contest. The point of the evaluation section is to get/provide insights about the workings of the system and the tradeoffs it makes. It is a pity this needs reminding.
Below I put the discussion about TPC-E versus TPC-C, and the emphasis on specific settings as verbatim, as these also cut to the core of the issue.
Shall we continue using TPC-C to testing concurrency control?
As
discussed previously, vanilla TPC-C, with its wait time, is essentially
an I/O benchmark and thus is not suitable for testing concurrency
control mechanisms. Tuning TPC-C to remove wait time and use a small
number of warehouses can introduce a high contention, but introduces
other problems like data set size is too small or there is no locality.
Therefore, though popular, TPC-C is perhaps not the ideal benchmark to
test concurrency control.
TPC-E has addressed some of
these issues: it introduces a realistic data skew; it introduces a
higher contention assuming all data can be kept in DRAM (otherwise it is
still an I/O intensive benchmark), but its adoption is slow probably
due to its complexity. For example, in TPC-E, 10 out of 12 types of
transactions involve lookups and scans through non-primary indexes,
which will pose challenges to systems that do not support scans or
require the prediction of read/write set.
Again, we
consider this as an open question: ultimately we will need studies from
production systems to answer this question. In the short term, we
propose a temporary solution by combining the ideas of TPC-C and YCSB:
we can use Zipfian distribution to create a few hot warehouses in TPC-C;
we don’t have evidence that it represents any realistic workload, but
at least it should allow us to create a high contention and a hotspot
within a large dataset.
Are we emphasizing too much on a specific setting?
As shown in Table 2, most works we studied focus on a specific parameter space—running transactions as stored procedures with a high degree of contention. While this scenario is certainly interesting, focusing too much on it is concerning especially since we lack any studies to confirm that this is the dominant scenario: actually Pavlo’s survey (What are we doing with our lives? Nobody cares about our concurrency control research) indicates the opposite by showing stored procedures are not frequently used for various reasons. At least we argue we should not overlook other scenarios.





Comments