TPC-E vs. TPC-C: Characterizing the New TPC-E Benchmark via an I/O Comparison Study
This paper is from Sigmod 2010, and compares the two standard TPC benchmarks for OLTP, TPC-C which came in 1992, and the TPC-E which dropped in 2007.
TPC-E is designed to be a more realistic and sophisticated OLTP benchmark than TPC-C by incorporating realistic data skews and referential integrity constraints. However, because of its complexity, TPC-E is more difficult to implement, and hard to provide reproducability of the results by others. As a result adoption had been very slow and little. (I linked TPC-C to its TPC-C wikipedia page above, but poor TPC-E does not even have a Wikipedia page. Instead it has this 1990s style webpage.)
A more cynical view on the immense popularity of TPC-C over TPC-E would be that TPC-C can be easily abused to show your database in the best possible light. TPC-C is very easily shardable on the warehouse_id to hide any contention on concurrency control, so your database would be able to display high-scalability. We had recently reviewed the OceanStore paper from VLDB 2022 which announced a world record of 707 Million tpmC in the title. To reach that number, they heavily optimized for the TPC-C benchmark. That is a lot of warehouses. "A total of 2,360 Alibaba Cloud ECS servers have been employed in this benchmark test. There are 400 remote terminal emulator (RTE) servers to emulate the total 559,440,000 users, and 55,944,000 warehouses."
Getting back to the paper, this paper studies the I/O behaviors of the TPC-C and TPC-E benchmarks and by using disk traces obtained on a commercial DBMS running on medium-sized computer systems with hundreds of disks. They compare various I/O characteristics of the two traces, including request types, sizes, spatial and temporal locality. They find that TPC-E (with 9.7:1 read/write ratio) is more read intensive than TPC-C (with 1.9:1 read/write ration). They also find that TPC-E I/O access pattern is as random as TPC-C, although TPC-E is designed to have more realistic data skews. This doesn't make sense of course. Their analysis of the reasons behind that makes a good systems detective story, and takes us to the culprit: the memory pool buffer. The explanation is that the memory size (8% of the TPC-E database size) is large enough to capture the skewed accesses when the data are cached in the main memory buffer pool. As a result of this filtering effect, the I/O access pattern of TPC-E seen at storage devices becomes as random as TPC-C.
What I would like to see is a reproduction of this TPC-E versus TPC-C comparison for distributed databases, because the buffer pool effect would not be as applicable, since the database nodes don't share memory. The VLDB 2022 paper titled "A Study of Database Performance Sensitivity to Experiment Settings" investigates some distributed databases with TPC-C benchmark to test the sensitivity of performance results to different settings. It doesn't have results with TPC-E, but comes to the conclusion that TPC-E could be a better benchmark in terms of realistic performance evaluation. I will add their views on this at the end of this post, and I hope to summarize that paper soon.
Without further ado, let's delve in to the paper we consider for today.
TPC-E overview
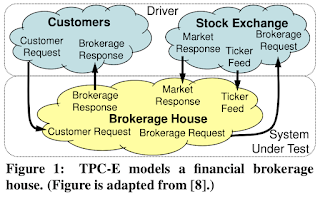
There are two main types of transactions in TPC-E: customer-initiated transactions and market-triggered transactions.
- In customer-initiated transactions, customers send requests to the brokerage house, which then queries or updates its database, submits brokerage requests to the stock exchange, and/or returns response to the customers.
- In market-triggered transactions, the stock exchange markets send trade results or real-time market ticker feeds to the brokerage house. The brokerage house updates its database, checks the recorded limit trading orders, and submits such orders if the limit prices are met.
TPC-E vs TPC-C features

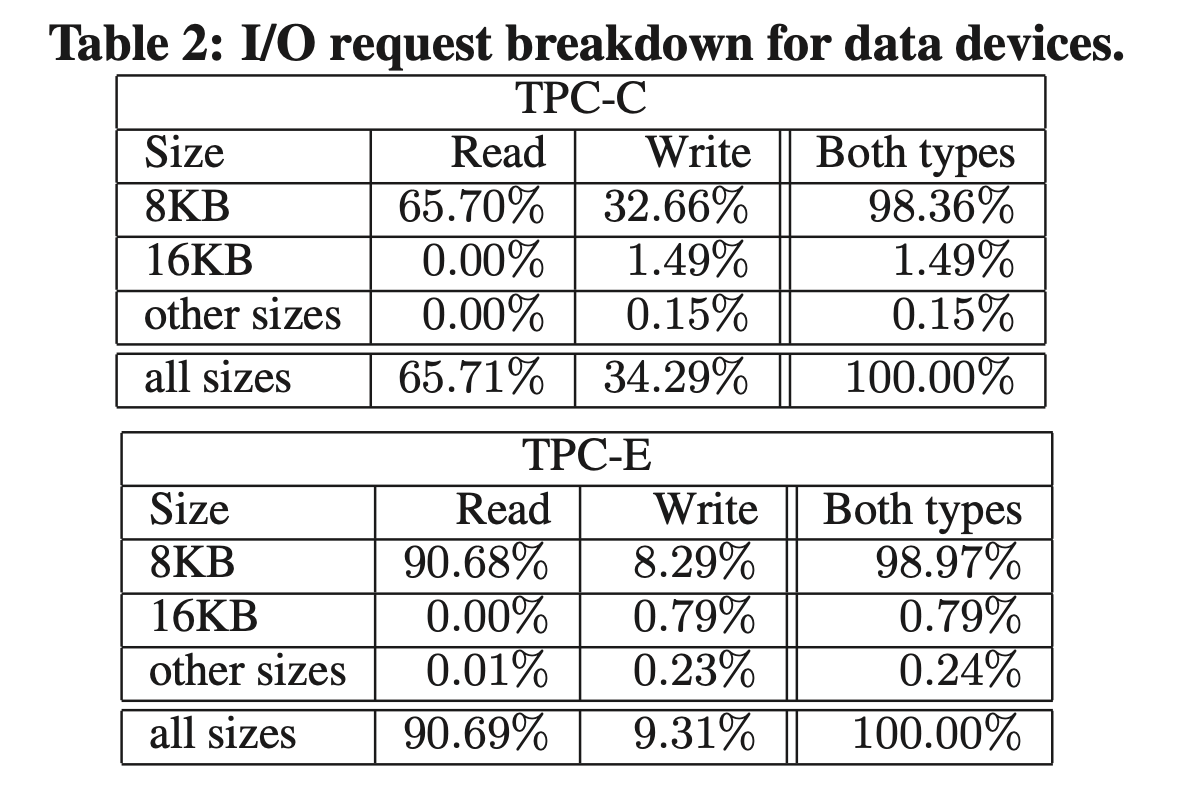
I/Os of sizes other than 8KB are almost entirely writes. An explanation is that the DBMS's default I/O size is 8KB, while in some rare cases writes to contiguous disk blocks are merged together into a single request. This implies that the I/Os are quite random, which is reasonable in TPC-C. However, this seems counter-intuitive that TPC-E also has such behavior since it is expected to have more data skews. So they investigate further by checking out temporal locality of accesses.

Buffer pool behavior
DBMSs perform updates by reading the destination database page into the main memory buffer pool (if it is not already in the buffer pool), and then making modifications to the page. Dirty page write backs are often done asynchronously by a background I/O cleaner thread/process. (Transaction durability is guaranteed by the synchronous redo log). The purpose of this strategy is to reuse pages in main memory for saving I/O operations. The read to write distance shows the duration that a page is kept in the memory buffer pool. Investigating the traces for read-to-write distance also show a flat line until 60 sec. This means that the buffer pool keeps a page for about 60 seconds before writing it back.
This explains the counter-intuitive random I/O behavior in TPC-E. TPC-E has poor temporal locality because the data skews in TPC-E may already be captured by the DBMS within the 60 second time when data pages are cached in the main memory buffer pool. Since the DBMS already effectively optimized away the data skews, the I/O devices do not see any reuses less than 60 seconds, hence, there is little temporal locality seen in the I/O accesses.
I would like to note again that, for distributed databases, this single node database buffer pool effect would not be as applicable, since the distributed database nodes don't share memory.
Conclusions from the paper
The paper has more graphs and investigation. But after all being said, what does all this mean about TPC-E versus TPC-C in practice? The paper says:
- First, the higher read to write ratio in TPC-E means that I/O optimizations targeting writes may be less effective for TPC-E.
- Second, the random I/O access patterns in TPC-E (due to buffer pool behavior) imply that the conclusions of many previous I/O studies for TPC-C can be still valid. For example, we verified through an SSD replay study that like TPC-C, replacing the HDDs with SSDs can dramatically im- prove the I/O performance of TPC-E.
Related work from VLDB 2022
I mentioned the VLDB 2022 study in the beginning of the post, and that they investigated the performance sensitivity of databases under different settings using TPC-C benchmant. Here is what that paper has to say on TPC-C versus TPC-E.
Shall we continue using TPC-C to testing concurrency control? As discussed previously, vanilla TPC-C, with its wait time, is essentially an I/O benchmark and thus is not suitable for testing concurrency control mechanisms. Tuning TPC-C to remove wait time and use a small number of warehouses can introduce a high contention, but introduces other problems like data set size is too small or there is no locality. Therefore, though popular, TPC-C is perhaps not the ideal benchmark to test concurrency control.
TPC-E has addressed some of these issues: it introduces a realistic data skew; it introduces a higher contention assuming all data can be kept in DRAM (otherwise it is still an I/O intensive benchmark), but its adoption is slow probably due to its complexity. For example, in TPC-E, 10 out of 12 types of transactions involve lookups and scans through non-primary indexes, which will pose challenges to systems that do not support scans or require the prediction of read/write set.
Again, we consider this as an open question: ultimately we will need studies from production systems to answer this question. In the short term, we propose a temporary solution by combining the ideas of TPC-C and YCSB: we can use Zipfian distribution to create a few hot warehouses in TPC-C; we don’t have evidence that it represents any realistic workload, but at least it should allow us to create a high contention and a hotspot within a large dataset.
MAD Questions
What are the minimum isolation and consistency requirements for running TPC-C and TPC-E benchmarks?
The distributed highly available transactions (HAT) paper, which we reviewed earlier, suggests that monotonic atomic view (MAV) is almost sufficient for running TPC-C. (It is an excellent paper, go read it if you haven't.)
The paper uses TPC-C benchmark to evaluate HAT. TPC-C consists of five transactions, capturing the operation of a wholesale warehouse, including sales, payments, and deliveries. Two transactions (Order-Status and Stock-Level) are read-only and can be executed safely with HATs. Clients may read stale data, but this does not violate TPC-C requirements and clients will read their writes if they are sticky-available. Another transaction type, Payment, updates running balances for warehouses, districts, and customer records and provides an audit trail. The transaction is monotonic—increment- and append-only so all balance increase operations commute, and MAV allows the maintenance of foreign- key integrity constraints (e.g., via UPDATE/DELETE CASCADE). But not all—TPC-C transactions are well served by HATs. The two problematic transactions, New-Order and Payment, rely on non-monotonic state update. The former can be modified to ensure ID uniqueness but not sequential ID ordering, while the latter is inherently non-monotonic, requiring external compensation or stronger consistency protocols.
A recent OOPSLA 2021 paper "MonkeyDB: Effectively Testing Correctness under Weak Isolation Levels" does some tests with TPC-C under read-committed and what they call causal isolation (I don't get this because causal is a consistency level not isolation level) and shows violations of assertions. The paper seems worth checking.
Update: James Corey (AWS) had looked into this question, and reports this.
The TPC-C spec provides some quick tests, which are informative and worth perusing for anyone writing (and testing) database code. It says they are "necessary but not sufficient" for meeting its ACID requirements--it notes that the appropriate protections must be enabled during the test, with the exception that non-repeatable reads are allowed for the Stock-Level transactions. Of course, since TPC-C was written in 1992, it just addresses the errant phenomena discussed in ANSI SQL-92, innocent of the issues raised by Berenson, Bernstein, Gray, Melton, and O'Neil (1995), and further explored by Adya, Liskov, and O'Neil (2000), and so on.
On the other hand, what they don't have quick checks for (and even some of the checks they describe but consider inconvenient, such as discovering phenomena due to write conflicts) are basically on the honor system, perhaps affording TPC the right to balk later. So in a way just passing the basic tests IS actually sufficient for purposes of getting your benchmark results approved. Qualitatively, the testing methodology looks pretty loose, like if I understand correctly, you can run under load for a while, and then stop and execute some validation queries, practically in a quiescent state, and if they pass (once?) then all's well? Anyway it feels like there is ample room for shortcuts, which would encourage testing with the loosest possible serializable isolation level that can satisfy the tests. Still, there are some non-trivial constraints.
The "Isolation" tests below are of course most directly relevant to the original question.
Atomicity: issue a *rollback* at the end of the payment transaction and show that there was *no effect*.
Consistency: run a bunch of checks such as that 1: sum of warehouse YTD amounts equals sum of district YTD amounts, 2: next order ID is one more than max order ID found in the ORDER as well as NEWORDER tables, etc... 12 different tests, generally that some *stats* like min, max, or sum of quantities *match when computed across different dimensions*. "Of the twelve conditions, explicit demonstration ... is required for the *first four only*." Some of these tests seem to make up for the lack of foreign key constraints. I feel like the concept at least was commonplace in 1992 and is pretty basic to SQL and certainly was included in SQL-89, and indeed TPC-C references foreign keys in the table descriptions, so it's not clear to me why they didn't say anything about explicitly validating them. TPC-E on the other hand does say to verify all referential integrity constraints, which is... an improvement? but also vague enough that it seems to leave a lot to the interpretation of the auditor.
Isolation: the textual description of their expectations is basically, no phantoms between NewOrder, Payment, Delivery, and Order-Status transactions specifically, but otherwise OK in the general case with Repeatable Read isolation, and again, Stock-Level transactions can be run with Read Committed isolation. As for testing... *Test 1*: start T1 (new order), pause before commit, start T2 (order status, same customer), verify T2 hangs, let T1 complete, veryify T2 completes (with updated data). *Test 2*: like test 1, but T1 is rolled back. *Test 3*: start T1 (new order), pause before commit, start T2 (new order same customer), verify T2 hangs, let T1 commit, verify T2 finished in proper way (includes effects of T1, has next higher order ID). *Test 4*: like test 3, but T1 is rolled back. *Test 5*: Like test 3 but with Payment and Delivery transactions. *Test 6*: like test 5 but T1 is rolled back. *Test 7*: run a new order txn, query some prices, pause, update the prices in a separate txn, query again in new order, verify original prices were used. *Test 8*: empty out a district/warehouse of inventory, start T1 (delivery), pause, start T2 (new order), continue, verify T1 saw emptiness bereft of T2 artifacts. *Test 9*: start T1 (order status), pause, start T2 (new order), continue, verify T1 doesn't see T2.
Durability: check for data loss or inconsistency after system crash or restart.
At 132 pages, with official audit requirements, it is now clearer to me why TPC-C testing is not in the critical path for any agile development initiatives. TPC-E, on the other hand, is only 287 pages. The ACID tests are similar in flavor.





Comments