Reconfiguring Replicated Atomic Storage
Reconfiguration is a rich source of faults in distributed systems. If you don't reconfigure, you lose availability when you lose additional nodes. But the reconfiguration algorithms are subtle, and it is easy to get them wrong, and lose consistency during reconfiguration. This is because a reconfiguration operation is run concurrently with the read/write operations and with potentially other reconfiguration operations, and they run when the system is already in some turmoil due to faults. Even the consensus papers/protocols do a bad job of addressing the reconfiguration problem; reconfiguration is always addressed as secondarily, incompletely, and many times incorrectly.
This paper, which appeared in the Bulletin of the EATCS: The Distributed Computing 2010, is about reconfiguration protocols for atomic storage. The atomic storage problem is a simpler problem than consensus or state machine replication (SMR). The difference is atomic storage is hedonistic (lives in the moment), it doesn't need to remember long term. SMR and consensus hold grudges and remember forever.
To give more context, let's recall the prominent work on reconfiguration of SMR we reviewed recently: Vertical Paxos. Vertical Paxos assumes an external Paxos cluster for reconfiguration, but in return achieves significant simplicity and flexibility benefits for reconfiguration and operation of the system. I think Vertical Paxos is still relevant to this reconfiguration survey, but the survey omits it because the survey is focused on atomic storage reconfiguration.
The biggest practical/operational difference between the atomic storage and SMR systems is that in atomic storage, there is no leader. Any of the clients can make proposals. Most SMR systems is based on leader-based Paxos protocols, which makes all the proposals. (Yes, there are leaderless SMR protocols, but they have many limitations especially pertaining to recovery from conflicts and failures. Moreover, even in the leaderless Paxos protocols use well-defined quorums, and the nodes/proposals have to be part of that inner-circle.) In contrast, in atomic storage the proposers are clients. Clients are not part of the system, often storage system compose of relatively dumb storage nodes. The clients will come and go freely. They don't have to register with a quorum and don't need to be part of the system boundary. Clients don't coordinate (at least directly) with each other but communicate with the storage nodes. (As a practical example of an atomic storage solution, you can think of AWS S3 service. S3 gives you atomic storage and linearizability. It doesn't give you SMR, but you can build one on this atomic storage solution if you like.)
Before we start reviewing this paper, if you are not familiar with the ABD algorithm, it would be good to review it now. ABD is a simple and elegant algorithm that solves atomic storage and provides linearizability to the face of minority number of node crashes even in an asynchronous system. The FLP impossibility showed that consensus (both safety and liveness specifications together) is not solvable even with a single node crash in an asynchronous system by a deterministic protocol, but FLP does not apply to the atomic storage problem. Being a simpler problem, atomic storage is solvable in the same set up as ABD shows.
Outline
The survey classifies atomic storage reconfiguration protocols in to two categories: those that use consensus to reconfigure, and those that don't.
Wait, did you catch that?? Is it possible to solve reconfiguration without consensus at all? The answer turns out to be yes for the atomic storage reconfiguration.
After covering consensus based atomic storage reconfiguration, we will learn of a solution that achieves atomic storage reconfiguration without consensus in a fully asynchronous system despite node crashes. Exciting!
But first, we must define the system model.
This is a long paper, at 25 pages. I borrow text from the paper liberally and provide a brief summary.
System model
The system is assumed to be asynchronous or partially asynchronous. So no information about the relative speed of nodes or on message delivery delays is available. Message losses are possible, but permanent network failures are not considered (you can consider a node that is permanently unreachable as crashed).
The safety requirement is to provide atomicity aka linearizability: each operation must appear to take place instantaneously between the time when it is invoked and the time when it produces a response.
The liveness requirement is that a correct client should terminate its operation despite the failures of a number of client nodes and/or storage nodes. ABD allows the failure of any number of client nodes and of any minority of the storage nodes. When the set of storage nodes can be reconfigured, the number of allowed failures depends on the occurrence of reconfiguration operations.
For the remaining discussion, consider 4 time varying sets: at a given time t in the execution, Current(t) is the configuration that reflects all reconfigurations that completed by time t. Nodes added (resp., removed) in reconfigurations that were invoked but did not complete by time t belong to AddPending(t) (resp., RemovePending(t)). Finally, nodes that crash by time t are in Failed(t). These sets are not known to the nodes; we use them for exposition.
Static liveness. If at any time t in the execution, fewer than minority of Current(t) nodes are in Failed(t), then all the operations of correct clients eventually complete.
Dynamic liveness. Suppose there is a finite number of reconfigurations. If at any time t in the execution, fewer than |Current(t)|/2 processes out of Current(t) union AddPending(t) are in Failed(t) union RemovePending(t), then all the operations of correct clients eventually complete.
The dangers of naive reconfiguration
Reconfiguration entails three steps:
- populate at least a majority of storage nodes in the new configuration with the current version of the data,
- stop the storage nodes that are to be removed,
- inform clients about the new configuration so that they subsequently access the new set of storage nodes.
We like to perform reconfiguration without blocking access to the storage system since we like to preserve availability during reconfiguration. But this is tricky. The paper gives 3 scenarios to illustrate how things can go wrong. The first two scenarios arise when read and write operations occur while the system is reconfiguring. The third deals with multiple reconfigure operations that execute concurrently. The scenarios are important to understand before we can discuss how the reconfiguration protocols presented next avoid these pitfalls.
In the first two scenarios, the system initially has three storage nodes s1, s2, s3 (the old configuration) and there is a reconfiguration operation to replace s2 with s'2 (i.e., to remove s2 and add s′2), so the system ends up with storage nodes s1, s′2, s3 (the new configuration). Since the system is not synchronous s, at a given time, different clients may be executing with different configurations.
Suppose one client writes new data using the new configuration, and another reads the old one. The first client stores a new value in two (a majority of) storage nodes, say s1, s′2. Subsequently, the second client, which reads using the old configuration, may query two storage nodes, say s2, s3. The second client misses the new value, causing the client to read stale data -- a violation of atomicity.
Similarly, consider the client that is performing the reconfiguration, and suppose it is populating the new configuration with value v, which it obtained from s1, s2 in the old configuration. Suppose the client stores v in s′2, s3, a majority of the new configuration. Then, another client starts to write v′ and it is still using the old configuration, so it stores v′ in s2, s3, a majority of the old configuration. Now all clients switch to the new configuration, but because s′2 is populated with v and s1 still has v, a subsequent read may query storage nodes s1, s′2 and miss the new value v′-- a violation of atomicity.
In the third scenario, the system initially has four storage nodes s1, . . . , s4 and two clients wish to reconfigure concurrently. The following problem can occur: One client starts a reconfiguration operation to remove s4, while a second client starts a reconfiguration operation to add s5. The first client succeeds and its new configuration is s1, s2, s3, while the second client also succeeds and its new configuration is s1, s2, s3, s4, s5. The clients will learn of each other’s reconfiguration later, but they have not yet done so. Now, the first client writes a value v′ to s1, s2, which is a majority of its new configuration; subsequently, if the second client reads using s3, s4, s5 then it misses v′--a violation of atomicity.
Approach 1: Reconfiguration using consensus
To avoid the “split brain” problem in the third scenario, one solution is to order the reconfiguration operations in a way that all nodes agree. Consensus can be used to establish a total order on the sequence of configurations that all nodes agree upon. In other words, consensus is used to ensure that each configuration is followed by a single configuration. For example, in the third scenario, when there are two outstanding reconfiguration operations, consensus ensures that only one of them is chosen to be the next configuration after s1,...,s4.
Consensus solves the “split brain” problem, but we must still avoid the other two bad scenarios. The problem here is not that clients disagree on the ordering of configurations, but that some clients may not yet be aware of the last configuration in the ordering (e.g., because when they checked, the latest configuration had not been established yet).
This problem is solved as follows.
As a first step, the reconfiguration operation stores a forward pointer at a majority of nodes in the old configuration, which points to the new configuration. This pointer ensures that, if a client were to perform an operation on the old configuration, it will find the forward pointer and will execute its operation on the new configuration as well.
As a second step, the reconfiguration operation populates the new configuration, so that it stores data as recent as the old configuration.
As the third and final step, clients can be told to execute their reads and writes only on the new configuration. Even if some clients were told before others, this will not violate atomicity: clients that were told will use the new configuration, while the others will use both the old and the new configuration, due to the forward pointer.
So in scenarios 1 and 2, the reconfiguration causes a majority of nodes among s1, s2, s3 to store a forward pointer to s1, s′2, s3. With this pointer, clients will execute reads and writes using both the old and new configurations (they may start with the old configuration only, but will see the forward pointer). The reconfiguration operation then populates the new configuration; then, it tells clients to disregard the old configuration and use only the new configuration.
The paper explains Rambo II in detail as an example of this consensus-based approach to atomic storage reconfiguration.
We will skip that discussion here but briefly discuss about cleaning after ourselves. For a reconfiguration operation to complete, the old configuration must eventually be retired or garbage collected, so that clients can disregard the old configuration and execute operations using only the newer configurations (and therefore servers in the old configuration that are not in the newer configurations can be turned off). If c is a configuration and c′ is the next configuration in the sequence, then c can be garbage collected after two actions have been performed:
- The next configuration c′ has been stored in the local cmap variables of a majority of storage nodes of c. Intuitively, this provides the forward pointer from c to c′, so that any operations that execute using configuration c will discover the existence of c′ (and therefore will execute using c′ as well).
- (State transfer). The Get and Set phases were performed after Action 1. This action guarantees that any value previously stored only in c will be copied to c′.
Before the garbage collection is completed, a majority of nodes in c and a majority of nodes in c′ must be alive. After c is garbage collected, we only need a majority of c′ to be alive.
Approach 2: Reconfiguration without consensus
FLP impossibility states that consensus which cannot be solved (meaning both safety and liveness satisfied) in a fully asynchronous environment with a deterministic protocol. But that doesn't apply to atomic storage problem as ABD algorithm showed. But what about solving reconfiguration of atomic storage in an asynchronous model? Can we reconfigure ABD without requiring consensus and without being subject to the FLP impossibility? The DynaStore paper showed that the answer is yes!
DynaStore works in asynchronous systems, without the need for consensus to prevent split-brain scenarios and other problems. If different reconfiguration proposals are made concurrently, DynaStore does not attempt to agree on a single next configuration to follow each configuration. Instead, for each configuration c, each client has a family of next configurations that it believes could follow c, and the coordination mechanism guarantees that such families at different clients always intersect. Thus, there is at least one common configuration that all clients consider as a possible next configuration after c. Clients will execute read and write operations on all configurations that they believe could follow c, to ensure that all clients overlap in the common configuration.
To ensure the existence of this common configuration, DynaStore uses the abstraction of a "weak snapshot". Each configuration c is associated with a weak snapshot, which is implemented using the storage nodes in c; the weak snapshot holds information about the family of possible configurations that follow c. A weak snapshot abstraction supports two operations: update(d) and scan(). update(d) is called to propose a configuration change d to configuration c, where d consists of sets of nodes to be added and removed; and scan() is called to retrieve a subset of the changes to configuration c previously proposed by storage nodes. Weak snapshots ensure that (1) once an update completes, every subsequent scan returns a non-empty set of configuration changes; and (2) once some configuration change is returned by a scan, it is returned by all subsequent scans.
Moreover, there exists some common configuration change dcommon that is returned in all non-empty scans. This is called the non-empty intersection property. Intuitively, dcommon can be thought of as the first configuration change applied to c. The implementation of weak snapshots ensures liveness provided that at most a minority of the storage nodes in c are removed or fail.
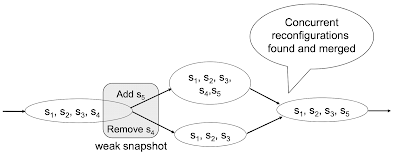
As an example consider Figure 1, which illustrates a DAG that may be created by an execution of DynaStore for the third scenario we discussed above. Two conflicting reconfigurations execute concurrently and update the weak snapshot of the initial configuration s1, s2, s3, s4. After the updates, both reconfigurations scan the weak snapshot to find the outgoing edges. The non-empty intersection property ensures that both operations observe at least one common configuration change. For instance, it is possible that the reconfiguration removing s4 does not see the one adding s5 and completes after transferring the state to configuration s1, s2, s3; however, in this case, if the reconfiguration adding s5 completes, it will notice and merge the branch in the DAG by creating a new vertex for s1, s2, s3, s5, connecting it to the DAG by updating the weak snapshots of the preceding branched configurations, and transferring the state to s1, s2, s3, s5.
DynaStore guarantees atomicity by reading from the configurations in all possible paths in the DAG, using the Get phase of ABD to read at each configuration. When a vertex without outgoing edges is reached, data is stored at this configuration using the Set phase, then a scan is performed on the weak snapshot of this configuration to check for new edges that may have been created by concurrent reconfigurations. If there are new edges, the traversal continues. Otherwise, the configuration is guaranteed to appear on all paths seen by other operations, and the client can complete its operation. This will happen provided that (a) there is a finite number of reconfigurations, and (b) the other liveness conditions specified earlier are met so that a majority of storage nodes are responsive in each traversed configuration. Note that the client ensures that all configuration changes encountered during the DAG traversal are reflected in the last traversed configuration (this is ensured by creating new vertices and edges as described above).
This is an elegant algorithm and a nice theoretical contribution that fills a gap by presenting atomic storage reconfiguration using atomic storage primitives and avoiding consensus and FLP impossibility. However, I think in practice using consensus for reconfiguration does not provide any disadvantages, and is a much better option to pursue. Paxos is safe under even a fully asynchronous model, and random backoff is easy to implement (because we are still practically in a partially synchronous model with unknown bounds, even when timing assumptions are violated) and eliminates the dueling leader scenario with probability 1. Liveness concerns of consensus due to dueling leader scenario is nothing to be exaggerated.





Comments