Memory-Optimized Multi-Version Concurrency Control for Disk-Based Database Systems
This paper is from VLDB 2022. It takes the MVCC system developed in Hyper and adopts it to a memory-optimized disk-based (not the spinning type, SSDs really) database system so that the system can handle a very large database that won't fit in RAM while achieving very high performance.
Motivation and introduction
As in-memory databases were conceived, it was assumed that main memory sizes would rise in accord with the amount of data in need of processing. But the increase in RAM sizes leveled off, reaching a plateau of at most a few TB. (This is likely due to the attractive price/performance benefits of SSDs.) Pure in-memory database systems offer outstanding performance but degrade heavily if the working set does not fit into DRAM.
On the other hand, traditional disk-based database systems, being designed for a different era, fail to take advantage of modern hardware with plenty enough (but still lacking full coverage) RAM and almost limitless SSDs (which are awesome for random IO and high throughput). For example, systems like PostgreSQL still rely on MVCC implementations that were devised decades ago and assume that almost no database pages and version data at all can be maintained in-memory.
Recently proposed memory-optimized disk-based systems such as Umbra (from the same Technische Universitat Munchen group) leverage large in-memory buffers for query processing but rely on fast SSDs for persistent storage. The work presented in this paper, extends that work, and adds a novel multi-version concurrency control (MVCC) approach to offer excellent performance on transactional workloads as well.
The approach leverages the fact that the vast majority of versioning information can be maintained entirely in-memory without ever being persisted to stable storage, and this minimizes the overhead of concurrency control. So they extend the buffer manager to transparently maintain a minimal decentralized mapping layer which associates logical data objects on the database pages with in-memory versioning information. Since none of this data needs to be written to persistent storage, the impact of concurrency control on the overall system performance is minimized. (In case this assumption fails, an arbitrarily large write transactions whose versioning footprint exceeds the available main memory size arrives, this is handles specially as a single-exclusive bulk operation.)
In a nutshell, this paper mounts the MVCC system presented in Hyper over Umbra's memory-optimized disk-based system. The approach is fully integrated and implemented within the general-purpose Umbra DBMS, and evaluated through experiments. The experiments show that this achieves transaction throughput up to an order of magnitude higher than competing disk-based systems (including Postgres and a widely used commercial DBMS system).
Refresher on Hyper's Multi-Version Concurrency Control
Under MVCC, writers can proceed even if there are concurrent readers, and read-only transactions will never have to wait at all. Because of this, MVCC has emerged as the concurrency control algorithm of choice both in disk-based systems such as MySQL, SQL Server, Oracle, PostgreSQL, and in in main memory databases such as HyPer, Hekaton, SAP HANA, Oracle TimesTen.
The decentralized MVCC implementation in this paper is first proposed for the HyPer in-memory database system. Read this summary to learn how that works, but here is a brief refresher.
The key idea of this approach is to perform updates in-place, and copy the previous values of the updated attributes to the private version buffer of the updating transaction. These before-images form a chain for each tuple which possibly spans the version buffers of multiple transactions. The entries in a given chain are ordered in the direction from newest to oldest change, and can be traversed in order to reconstruct a previous version of a tuple. Outdated versions that are no longer relevant to any transaction are garbage collected continually.
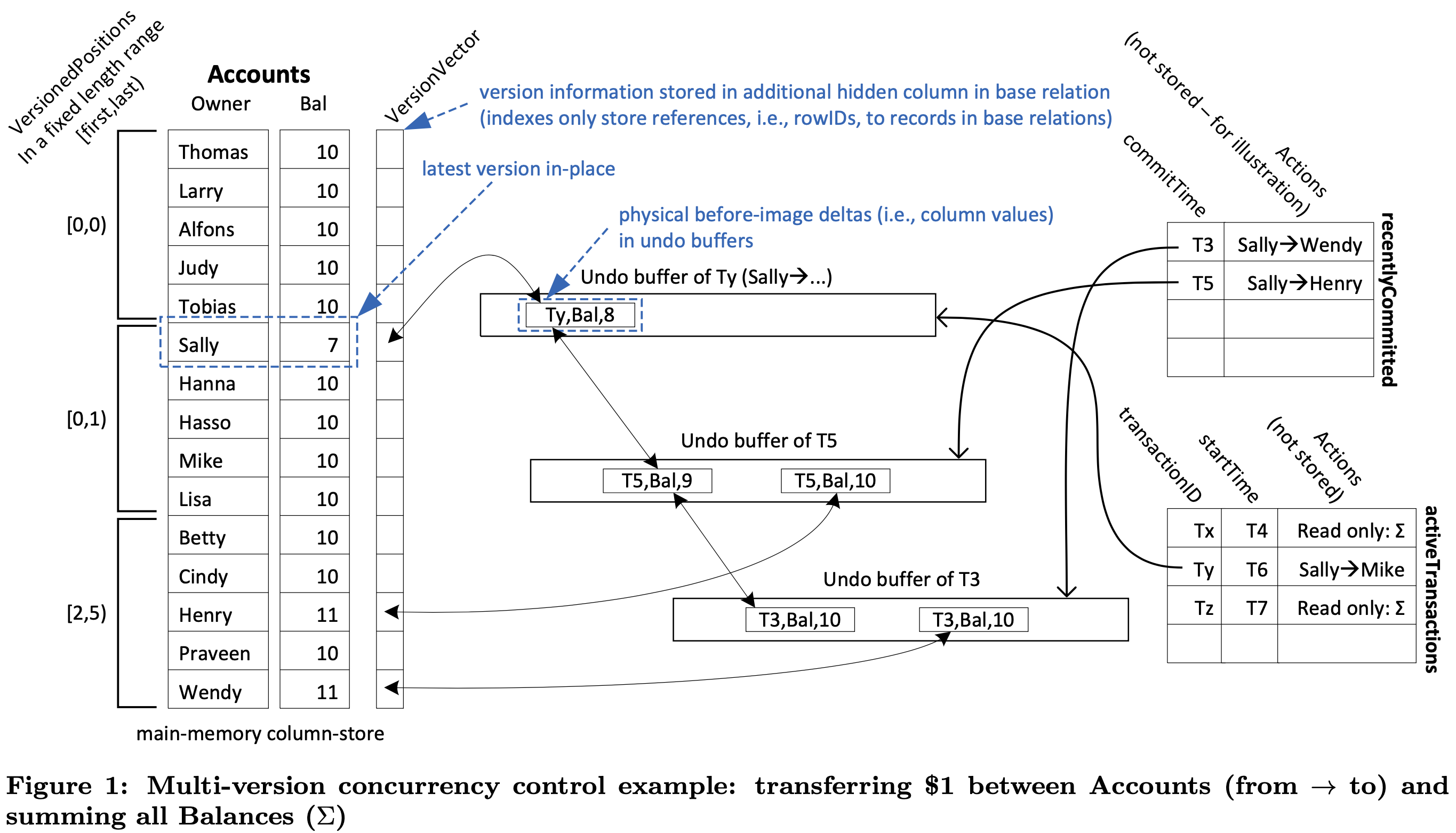
Memory-Optimized MVCC
The proposed method observes that the vast majority of write transactions encountered during regular transaction processing are extremely small: they generate few versions which consume many orders of magnitude less main memory than what is available on modern hardware.
So the assumption is that a memory-optimized disk-based system can easily maintain all versioning information required by MVCC entirely in-memory. By carefully relying on the logging subsystem for recovery, it is possible to ensure that this versioning information is truly ephemeral and will never be written to persistent storage.
Not only does this lead to excellent performance in the common case that the working set fits into main memory, but it also dramatically reduces the amount of redundant data that has to be written to disk, since generally only the most recent version of a data object will be present on the actual database pages.
In-Memory Version Maintenance
Disk-based system designs rely on a buffer manager to provide an intelligent global replacement strategy, and hide the complexities of IO buffering. A buffer-managed database system typically employs a steal policy, i.e. database pages containing uncommitted changes may be evicted to persistent storage. This is essential in order to allow the system to scale gracefully beyond main memory, but poses a key challenge: The logical data objects that may be evicted from main memory at any time still have to be associated with their respective version chain.
In order to avoid write amplification to disk, it makes sense to store any additional versions separately from the most recent version of a data object and only include the latter in the persistent database state. Variations of this basic scheme are widespread in existing systems such as SQL Server, Oracle DB, MySQL, SAP HANA, or HyPer. Disk-based systems typically employ a global version storage data structure which maps stable logical identifiers to actual versions. Each version of a data object, including the master version that is persisted to disk, contains such a logical identifier as an additional attribute to form a link to the next version in the corresponding chain. However, a global data structure can easily become a major scalability bottleneck. Moreover, versions can only be accessed through a non-trivial lookup into this data structure, which makes even uncontended version chain traversals rather expensive.
Recently proposed storage managers such as LeanStore (from the same TUM group) overcome these problems by using pointer swizzling. Pointer swizzling allows the translation from logical page identifiers to physical buffer frame addresses to be implemented in a decentralized way. Here, any reference to a database page is represented as a fixed-size integer called a swip. A swip can either store a logical page identifier in case the referenced page is currently residing on persistent storage, or a physical pointer to a buffer frame in case it is currently cached in the buffer manager. In contrast to traditional designs, pointer swizzling allows cached pages to be accessed with minimal overhead and without any global synchronization since no lookup into any centralized translation data structure is required.
This is where Hyper's MVCC fit in naturally. HyPer stores versions in a decentralized way, and use raw pointers to directly link individual versions within a chain instead of relying on logical identifiers.
Only a minimal logical mapping layer is needed since we cannot store raw pointer on database pages.
(Aside: Who knew?? At the multiple nodes level across LAN/WAN, for better performance, logical centralization makes more sense in order to avoid wasted rounds of communication. On the other hand, at the single node level more decentralization makes more sense in order to avoid contention/hotspots from threads/multicore. At the single node level, the system does not pay the cost of decentralization and is able to reap all its benefits.)

Garbage collection is based on the highly scalable Steam algorithm devised for in-memory systems, with some extensions to account for the local mapping tables. As part of the commit processing, the database reclaims all recently committed transactions with a commit timestamp that is less than the minimum start timestamp of any active transaction.
Recovery exclusively relies on the information captured in the write-ahead log generated during forward processing, and does not require any concurrency control. After recovery, the database is in a globally consistent state without any active transactions, and consequently no version chains at all are present within the system.
Version maintenance
Local mapping tables establish a link between data objects on a page and their associated version chains, if any. A pointer to the mapping table is stored in the corresponding buffer frame while a page resides in the buffer pool, and can be accessed through the same latching protocol that is already in place to access the page itself.
The buffer manager can still evict arbitrary pages as usual, but only the page data is actually written to disk. Any orphaned mapping tables are retained in-memory by the buffer manager within a hash table that maps the identifier of the corresponding page to the mapping table. Once a page is loaded back into memory at a later point in time, the buffer manager probes this hash table to check whether a mapping table exists for the page and reattaches it to the respective buffer frame if necessary. A mapping table entry only stores a pointer to the corresponding version chain that is maintained separately within the transaction-local version buffers. This is extremely useful, since it allows transactions to efficiently update the timestamps of their versions during commit processing. Specifically, we do not have to update any mapping tables which would require latching database pages.
Consider, for example, the situation illustrated in Figure 2 which mirrors the in-memory scenario shown previously in Figure 1. Pages 1 and 4 have no associated local mapping table and thus contain no versioned data objects. In contrast, pages 2 and 3 do contain versioned data objects which is indicated by the presence of a local mapping table for these pages. Page 3 is currently loaded into the buffer pool, so the respective buffer frame contains a pointer to this mapping table. Page 2 is currently evicted, for which reason the buffer manager remembers the pointer to the associated mapping table within the separate orphan table. It will be reattached to the corresponding buffer frame once page 2 is loaded back into memory.
Out-of-Memory Version Maintenance
Obviously, the above in-memory versioning approach fails for transactions which generate more version data than the amount of available working memory. To account for a very large write transaction, they treat it differently as a bulk operation. They give bulk operations exclusive write access to the entire database, and only allow read transactions to execute concurrently. This greatly simplifies concurrency control, and additionally ensures that bulk operations will never abort due to write-write conflicts.
Conceptually, this approach allows bulk operations to create virtual versions which encode creation or deletion of a data object. For the purpose of visibility checks, these virtual versions are treated just like regular versions in our MVCC protocol. That is, a data object can be associated both with virtual versions created by a bulk operation, and regular versions created by the in-memory versioning approach. Such virtual versions require no physical memory allocation, allowing the approach to process arbitrarily large write transactions.

Evaluation results
They provide a thorough evaluation of the system having implemented it within the disk-based relational database management system Umbra. The buffer manager is derived from LeanStore, and durability is provided by a low-overhead decentralized logging scheme.
They compare the implementation to PostgreSQL version 14 and another widely used commercial database management system referred to as DBMS A in the following. They consider both the disk-based (DBMS AD) and the in-memory (DBMS AM) storage engines provided by DBMS A in our evaluation. All systems are configured to employ snapshot isolation.
Experiments are run on a server system equipped with 192 GB of RAM and an Intel Xeon Gold 6212U CPU providing 24 physical cores and 48 hyper-threads at a base frequency of 2.4 GHz. The write-ahead log resides on a 768 GB Intel Optane DC Persistent Memory device, while all remaining database files are placed on a PCIe-attached Samsung 970 Pro 1 TB NVMe SSD, both of which are formatted as ext4.
They select the well-known TATP and TPCC transaction processing benchmarks. For TATP we populate the database with 10 000 000 subscribers and run the default transaction mix consisting of 80 % read transactions and 20 % write transactions with uniformly distributed keys. For TPCC, they use 100 warehouses and run the full transaction mix consisting of about 8 % read transactions and 92 % write transactions. Depending on the system, the initial database population including indexes requires between 7 GB to 8 GB for TATP, and between 11 GB to 12 GB for TPCC.
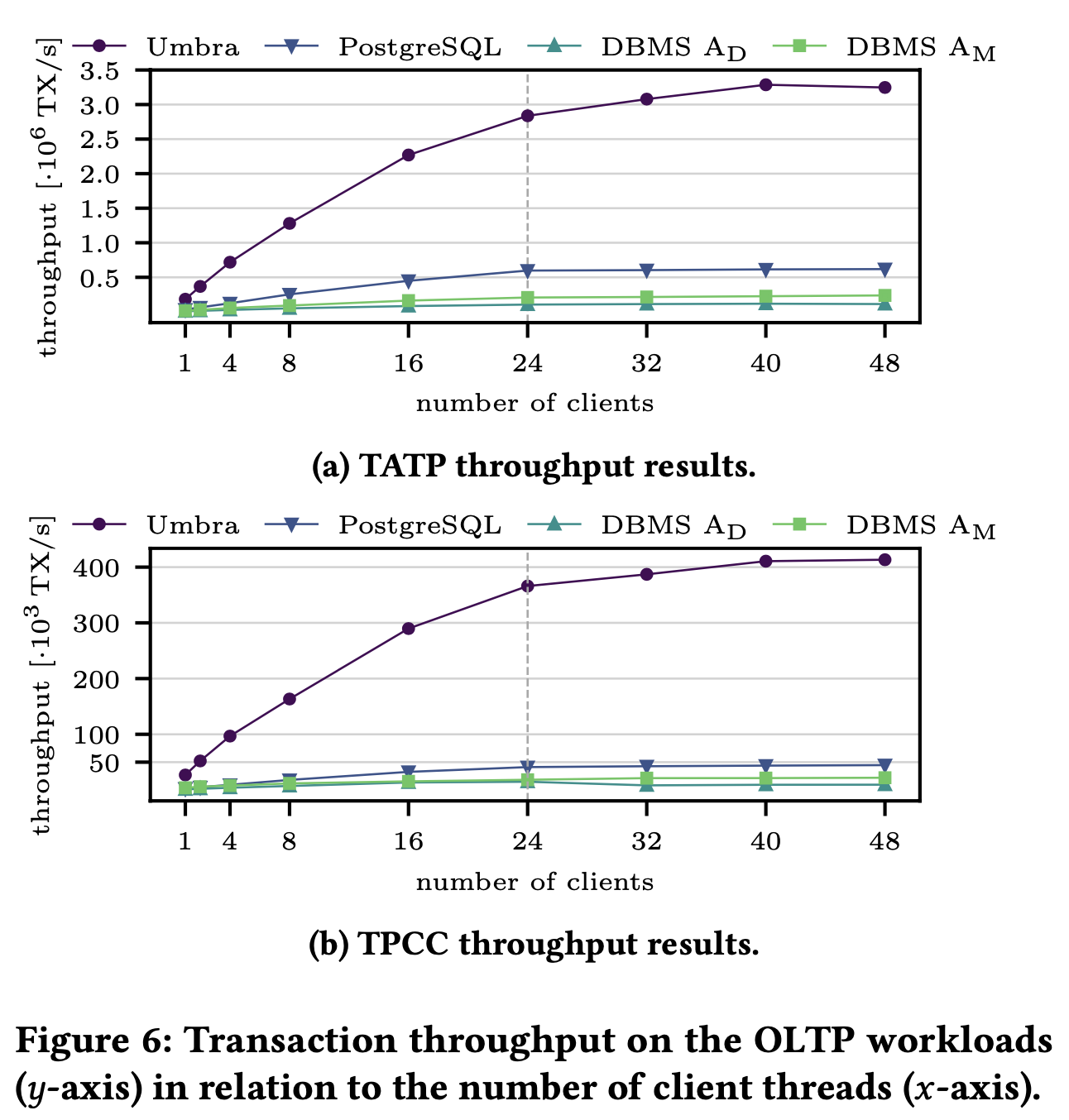
In both TATP an TPCC benchmarks, Umbra outperforms others by up to an order of magnitude, reaching a maximum speedup of 9.2 × over PostgreSQL, 27.6 × over DBMS AD, and 18.8 × over DBMS AM. Transaction throughput universally scales well with the number of client threads on the TATP benchmark. With a single client thread, the systems respectively process 183 000 TX/s (Umbra), 33 400 TX/s (PostgreSQL), 7 900 TX/s (DBMS AD), and 15 000 TX/s (DBMS AM). Umbra, PostgreSQL, and DBMS AM attain their maximum throughput at 48 client threads with 3 247 000 TX/s, 618 700 TX/s, and 237 900 TX/s, respectively. DBMS AD achieves its maximum of 117 700 TX/s at 40 client threads after which throughput decreases marginally to 113 000 TX/s. Since TPCC is much more write-heavy than TATP, we observe generally lower throughput, starting at 27 000 TX/s (Umbra), 2 600 TX/s (PostgreSQL), 1 100 TX/s (DBMS AD), and 4 000 TX/s (DBMS AM ) with a single client thread. Nevertheless, performance scales well for Umbra, PostgreSQL, and DBMS AM as the number of client threads is increased, and they reach maximum throughput at 48 client threads with 413 300 TX/s, 44 700 TX/s, and 22 000 TX/s respectively. In contrast DBMS AD struggles to achieve good scalability, and attains its maximum throughput of 14 900 TX/s at 24 client threads beyond which performance decreases again down to around 9 000 TX/s.
The experiments demonstrate that traditionally designed disk-based database systems such as PostgreSQL and DBMS AD cannot fully exploit the capabilities of modern hardware. The single-threaded throughput numbers constitute particularly strong evidence for this conclusion, as system performance is far from being bound by IO throughput in this case. In fact, even the mature in-memory system DBMS AM falls short of Umbra although it can avoid many of the complexities encountered in a disk-based system. The large speedup of Umbra over its competitors is almost entirely due to the greatly reduced overhead of its novel memory-optimized system architecture and the proposed MVCC implementation.
How does this compare to Hyper? Of course a well-optimized in-memory system can operate with even lower overhead since it can employ highly specialized data structures that are not applicable to a disk-based setting. They measured the single-threaded TPCC throughput of HyPer in our benchmark environment to be 58 800 TX/s, in contrast to the 27 000 TX/s of Umbra.






Comments