Seeing is Believing: A Client-Centric Specification of Database Isolation
This paper presents a new way to reason about transaction-isolation based on application-observable states, in lieu of prior history-based approaches. This approach maps more naturally to what applications can observe, and facilitates comparing isolation guarantees. It also frees isolation definitions from implementation-specific details (timestamps, replicas) and opens the way to find alternate implementations.
The paper provides a dense but rewarding read. If you call history-based approaches as operational reasoning on transaction isolation semantics, you can think of the proposed state-based approach as opening the way for invariant-based reasoning for this. So there is a lot of potential to be realized for this work. The paper already illustrates some of these benefits:
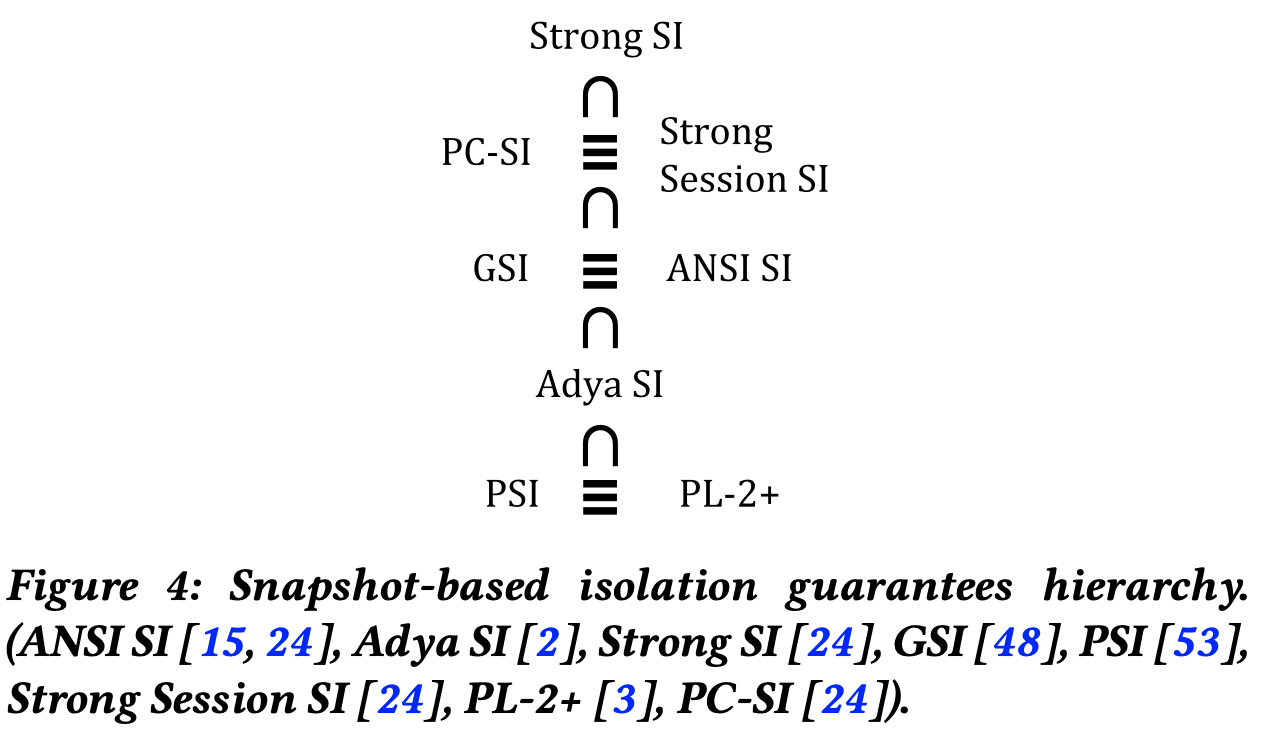
- State-based modeling shows that several well-known guarantees, previously thought to be distinct, are in fact equivalent, and that many previously incomparable flavors of snapshot isolation can be organized in a clean hierarchy. The paper shows that parallel snapshot isolation (PSI) is equivalent to lazy consistency (PL-2+); generalized snapshot isolation (GSI) is actually equivalent to ANSI snapshot isolation (ANSI SI); and strong session SI is equivalent to prefix-consistent SI.
- A state-based definition of PSI shows that the requirement of totally ordering transactions at each datacenter, which is baked into its current definition, is only an implementation artifact. Removing it offers the opportunity of an alternative implementation of PSI that makes it resilient to slowdown cascades.
Traditional history based model
Adya's thesis provides a comprehensive coverage of the traditional history-based model of reasoning about transaction isolation. Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions (1999). Adya's model is expressed in terms of histories, which consist of two parts: a partial order of events that reflect the operations of a set of transactions, and a version order that imposes a total order on committed object versions. Every history is associated with a directed serialization graph DSG(H), whose nodes consist of committed transactions and whose edges mark the conflicts (read-write, write-write, or write-read) that occur between them.
An execution satisfies a given isolation level if it disallows reads from aborted transactions, intermediate reads, and circularity. The first two conditions prevent a transaction T1 from reading, respectively, (i) values produced by an aborted transaction T2 and (ii) a version of an object x written by a transaction T2 that T2 subsequently overwrites. The third condition is more complex. Disallowing circularity prevents cycles in the serialization graph, but the specific edges that compose the cycle are dependent on the particular isolation level.
A state-based model
Instead of relying on some notion of history, the state-based model associates with each transaction the set of read states from which it may have retrieved the values. A storage system guarantees a specific isolation level I if it can produce an execution (a sequence of atomic state transitions) that satisfies two conditions.
- The read states associated with the execution must be consistent with the values observed by each transaction T
- The execution must satisfy the constraints imposed by I: If no read state proves suitable for some transaction, then I does not hold

In the above definition of transaction over states, we refer to s as the parent state of T (denoted as sp). To prevent operations from reading from the future, the valid read states for the operations in T is restricted to be no later than sp. Once an operation in T writes v to k, all subsequent operations in T that read k is also required to return v.

Isolation

Snapshot isolation requires transactions to read from a snapshot (a complete state in our parlance) that reflects a single commit ordering of transactions. The coordination implied by this requirement is expensive to carry out in a geo-replicated system and must be enforced even when transactions do not conflict. Parallel Snapshot Isolation (PSI) aims to offer a scalable alternative by allowing distinct geo-replicated sites to commit transactions in different orders. Thus, PSI has received attention and Table 1 also provides a state based definition of PSI.
Removing implementation artifacts
History-based operational reasoning about isolation leads to many confusions. Several, multiversioned commercial databases (e.g.Oracle 12c), that prevent the four phenomenas ANSI SQL defines in the context of lock-based single version databases, claim to implement serializability, when they in fact implement only snapshot isolation. They accept non-serializable schedules akin to the schedule in Figure 1 (right), an anomaly commonly referred to as write skew. On the other hand, they also commit the reverse sin of overfitting: a majority reject the (serializable) schedule of Figure 1 (left) because, for performance reasons, these systems choose not to reorder writes.

State-based model clarifies things, and facilitates comparison of isolation guarantees introduced in recent years. The paper shows this by comparing ANSI SI, Adya SI, Weak SI, Strong SI, generalized snapshot isolation (GSI), parallel snapshot isolation (PSI), Strong Session SI, PL-2+ (Lazy Consistency), and Prefix-Consistent SI (PC-SI). They establish a clean hierarchy that encompasses them and show that several of these isolation guarantees, previously thought to be distinct, are in fact equivalent from a client's perspective.

Identifying performance opportunities
Defining isolation guarantees in terms of client-observable states helps prevent them from subjecting transactions to stronger requirements than what these guarantees require. Since every dependency created in the state-based model stems from an actual client observation, the number of dependencies that a state-based model creates is minimal. To illustrate this potential benefit for PSI, they simulated the number of transactional dependencies created at each datacenter by the traditional definition of PSI as compared to the "true" dependencies generated by the state-based approach, over an asynchronously replicated transactional key-value store TARDiS. On a workload consisting of read-write transactions (three reads, three writes) accessing data uniformly over 10,000 objects, they found that a client-centric approach decreased dependencies, per transaction, by two orders of magnitude (175×), a reduction that can yield significant dividends in terms of scalability and robustness.

Discussion
I like the proposed state-based approach to reasoning about transaction isolation guarantees. I think we will get more benefits out of using this approach instead of the history-based operational reasoning approach. But, I can't refrain from pointing out a limitation of this approach.
This is a read/write-level formulation rather than a higher operation/application-level formulation (such as in Herlihy Wing, etc). A read/write level formulation is a very restrictive constrained formulation of
the general conflict rules. Some writes do not invalidate a read-invariant as far as the application is concerned. For example, the read(x) may be followed with "if x >10 do this". If the write does not violate x>10, it is not a real conflict. Therefore, making any write on an item conflict with a read is overly restrictive. Capturing this semantics is powerful, but this is application specific. In contrast, the read/write level formulation takes a blackbox level view of the system for broader blackbox application. (Pat Helland would not approve the read/write level conflict capturing.) This observation, though, should not detract from the contributions of this work, which I think is awesome!
With a little digging, I found this followup work which provides a TLA+ formalization of state-based isolation model. There is a paper published on this TLA+ formalization as well. Cool!
UPDATE: Here is my review of the TLA+ formalization of state-based isolation model.





Comments
Also, there is a good review by Adrian Colyer: https://blog.acolyer.org/2020/11/30/seeing-is-believing/