FoundationDB: A Distributed Unbundled Transactional Key Value Store (Sigmod 2021)
This paper from Sigmod 2021 presents FoundationDB, a transactional key-value store that supports multi-key strictly serializable transactions across its entire key-space. FoundationDB (FDB, for short) is opensource. The paper says that: "FDB is the underpinning of cloud infrastructure at Apple, Snowflake and other companies, due to its consistency, robustness and availability for storing user data, system metadata and configuration, and other critical information."
The main idea in FDB is to decouple transaction processing from logging and storage. Such an unbundled architecture enables the separation and horizontal scaling of both read and write handling.
The transaction system combines optimistic concurrency control (OCC) and multi-version concurrency control (MVCC) and achieves strict serializability or snapshot isolation if desired.
The decoupling of logging and the determinism in transaction orders greatly simplify recovery by removing redo and undo log processing from the critical path, thus allowing unusually quick recovery time and improving availability.
Finally, a purpose-built deterministic and randomized simulation framework is used for ensuring the correctness of the database implementation.
Let's zoom in each of these areas next.
Unbundled architecture
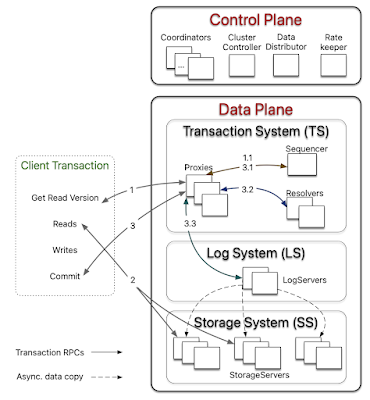
FDB architecture comprises of a control plane and a data plane.
The control plane is responsible for persisting critical system metadata (such as the configuration of servers) on Coordinators. These Coordinators form a disk Paxos group and select a single ClusterController. The ClusterController monitors all servers in the cluster and recruits three processes, Sequencer, DataDistributor, and Ratekeeper, which are re-recruited if they fail or crash. The Sequencer assigns read and commit versions to transactions. The DataDistributor is responsible for monitoring failures and balancing data among StorageServers. Ratekeeper provides overload protection for the cluster.
The data plane consists of a transaction management system, responsible for processing updates, and a distributed storage layer serving reads; both of which can be independently scaled out. A distributed transaction management system (TS) performs in-memory transaction processing, a log system (LS) stores Write-Ahead-Log (WAL) for TS, and a separate distributed storage system (SS) is used for storing data and servicing reads.
LogServers act as replicated, sharded, distributed persistent queues, where each queue stores WAL data for a StorageServer. The SS consists of a number of StorageServers for serving client reads, where each StorageServer stores a set of data shards, i.e., contiguous key ranges. StorageServers are the majority of processes in the system, and together they form a distributed B-tree. Currently, the storage engine on each StorageServer is a modified version of SQLite. (The paper says that a switch to RocksDB is being planned, but the FoundationDB website says a better B+-tree implementation using Redwood is being considered.)
Now, let's focus on transaction management system (TS) in the next section.
Concurrency control
The TS provides transaction processing and consists of a Sequencer, Proxies, and Resolvers. The Sequencer assigns a read version and a commit version to each transaction. Proxies offer MVCC read versions to clients and orchestrate transaction commits. Resolvers are key-partitioned and help check for conflicts between transactions.
An FDB transaction observes and modifies a snapshot of the database at a certain version and changes are applied to the underlying database only when the transaction commits. A transaction’s writes (i.e., set() and clear() calls) are buffered by the FDB client until the final commit() call, and read-your-write semantics are preserved by combining results from database look-ups with uncommitted writes of the transaction.
Getting a read-version
On the topic of getting a read-version (GRV), there is a divergence between the FDB website and the paper. The website says, a Proxy needs to talk to all proxies before it can provide the view. "When a client requests a read version from a proxy, the proxy asks all other proxies for their last commit versions, and checks a set of transaction logs satisfying replication policy are live. Then the proxy returns the maximum commit version as the read version to the client. The reason for the proxy to contact all other proxies for commit versions is to ensure the read version is larger than any previously committed version. Consider that if proxy A commits a transaction, and then the client asks proxy B for a read version. The read version from proxy B must be larger than the version committed by proxy A. The only way to get this information is by asking proxy A for its largest committed version."
The paper is terse on this topic and says this: "As illustrated in Figure 1, a client transaction starts by contacting one of the Proxies to obtain a read version (i.e., a timestamp). The Proxy then asks the Sequencer for a read version that is guaranteed to be no less than any previously issued transaction commit version, and this read version is sent back to the client. Then the client may issue multiple reads to StorageServers and obtain values at that specific read version."
I asked for clarification, and a friend who is a coauthor on the FDB paper provided this answer. "There was a change in the get-a-read-version (GRV) path in a recent release (7.0, I think?). Pre-7.0, proxies did a broadcast amongst eachother. Post-7.0, proxies have to register the version they committed with the sequencer before they can reply to clients, and thus they can also just ask the sequencer for the most recently committed version instead of broadcasting. It makes commits take slightly longer, but makes GRV latencies more stable."
Committing the transaction
A Proxy commits a client transaction in three steps.
- First, the Proxy contacts the Sequencer to obtain a commit version that is larger than any existing read versions or commit versions.
- Then, the Proxy sends the transaction information to range-partitioned Resolvers, which implement FDB's OCC by checking for read-write conflicts. If all Resolvers return with no conflict, the transaction can proceed to the final commit stage. Otherwise, the Proxy marks the transaction as aborted.
- Finally, committed transactions are sent to a set of LogServers for persistence. A transaction is considered committed after all designated LogServers have replied to the Proxy, which reports the committed version to the Sequencer (to ensure that later transactions’ read versions are after this commit) and then replies to the client. At the same time, StorageServers continuously pull mutation logs from LogServers and apply committed updates to disks.
Read-only transactions
In addition to the above read-write transactions, FDB also supports read-only transactions and snapshot reads. A read-only transaction in FDB is both serializable (happens at the read version) and performant (thanks to the MVCC). The client can commit these transactions locally without contacting the database. Snapshot reads in FDB selectively relax the isolation property of a transaction by reducing conflicts, i.e., concurrent writes will not conflict with snapshot reads.
Atomic operations
FDB supports atomic operations such as atomic add, bitwise “and” operation, compare-and-clear, and set-versionstamp. These atomic operations enable a transaction to write a data item without reading its value, saving a round-trip time to the StorageServers. Atomic operations also eliminate read-write conflicts with other atomic operations on the same data item (only write-read conflicts can still happen). This makes atomic operations ideal for operating on keys that are frequently modified, such as a key-value pair used as a counter. The set-versionstamp operation is another interesting optimization, which sets part of the key or part of the value to be the transaction’s commit version. This enables client applications to later read back the commit version and has been used to improve the performance of client-side caching. In the FDB Record Layer, many aggregate indexes are maintained using atomic mutations.
Discussion about concurrency control
By decoupling the read and write path, and leveraging the client to do the staging of the transaction updates before Commit, FDB achieves simple concurrency control. I really liked that FDB has a very simple transition going from strict serializability to snapshot isolation consistency level, by just relaxing the GRV appropriately. If you remember our CockroachDB discussion, this was not possible in CockroachDB. I think FDB also enjoys the benefit of using a single sequencer for timestamping here.
(CockroachDB, of course has a more decentralized architecture, using different Paxos groups potentially in different regions. As we will discuss in replication section, even for geo replication FDB takes the simple solution of a single master solution compared to the multiple master solution in CockroachDB.)
Resolvers are simple, key-partitioned hot-caches for updates so they can check conflicts. Unfortunately resolvers are prone to false-positives. It is possible that an aborted transaction is admitted by a subset of Resolvers, which may cause other transactions to conflict (i.e., a false positive). The paper says this: "In practice, this has not been an issue for our production workloads, because transactions’ key ranges usually fall into one Resolver. Additionally, because the modified keys expire after the MVCC window, the false positives are limited to only happen within the short MVCC window time (i.e., 5 seconds)."
The paper also includes a discussion about the tradeoffs of using lock free OCC in FDB concurrency control. The OCC design of FDB avoids the complicated logic of acquiring and releasing (logical) locks, which greatly simplifies interactions between the TS and the SS. The price paid for this simplification is to keep the recent commit history in Resolvers. Another drawback is not guaranteeing that transactions will commit, a challenge for OCC. Because of the nature of our multi-tenant production workload, the transaction conflict rate is very low (less than 1%) and OCC works well. If a conflict happens, the client can simply restart the transaction.
Fault tolerance
Besides a lock-free architecture, one of the features distinguishing FDB from other distributed databases is its approach to handling failures. Unlike most similar systems, FDB does not rely on quorums to mask failures, but rather tries to eagerly detect and recover from them by reconfiguring the system. FDB handles all failures through the recovery path: instead of fixing all possible failure scenarios, the transaction system proactively shuts down and restarts when it detects a failure. As a result, all failure handling is reduced to a single recovery operation, which becomes a common and well-tested code path. Such error handling strategy is desirable as long as the recovery is quick, and pays dividends by simplifying the normal transaction processing. This reminds me of the crash-only software approach.
For each epoch (i.e., shutdown & restart of TS), the Sequencer executes recovery in several steps. First, the Sequencer reads the previous transaction system states (i.e. configurations of the transaction system) from Coordinators and locks the coordinated states to prevent another Sequencer process from recovering at the same time. Then the Sequencer recovers previous transaction system states, including the information about all older LogServers, stops these LogServers from accepting transactions, and recruits a new set of Proxies, Resolvers, and LogServers. After previous LogServers are stopped and a new transaction system is recruited, the Sequencer then writes the coordinated states with current transaction system information. Finally, the Sequencer accepts new transaction commits.
In FDB, StorageServers always pull logs from LogServers and apply them in the background, which essentially decouples redo log processing from the recovery. The recovery process starts by detecting a failure, recruits a new transaction system, and ends when old LogServers are no longer needed. The new transaction system can even accept transactions before all the data on old LogServers is processed, because the recovery only needs to find out the end of redo log and re-applying the log is performed asynchronously by StorageServers.
To improve availability, FDB strives to minimize Mean-Time-To-Recovery (MTTR), which includes the time to detect a failure, proactively shut down the transaction management system, and recover. The paper says that the total time is usually less than five seconds.
I really liked this discussion about how FDB leverages this reset-restart approach for continuous deployment in production. "Fast recovery is not only useful for improving availability, but also greatly simplifies the software upgrades and configuration changes and makes them faster. Traditional wisdom of upgrading a distributed system is to perform rolling upgrades so that rollback is possible when something goes wrong. The duration of rolling upgrades can last from hours to days. In contrast, FoundationDB upgrades can be performed by restarting all processes at the same time, which usually finishes within a few seconds. Because this upgrade path has been extensively tested in simulation, all upgrades in Apple’s production clusters are performed in this way. Additionally, this upgrade path simplifies protocol compatibility between different versions--we only need to make sure on-disk data is compatible. There is no need to ensure the compatibility of RPC protocols between different software versions."
Although the paper says 5 seconds is enough, about recovery the website gives a slightly different story. It says that for recovery the sequencer time is punted in to the future for 90seconds, and this makes in-progress transaction abort. I was confused about this statement, and asked my friend about this. "Is Sequencer time a logical clock? Then what does it mean to punt it by 90secs? Also isn’t recovery achievable in 5sec of rebooting? Does this 90sec punt mean 90 seconds of unavailability instead of 5s?". He replied as follows: "Sequencer time is logical, but it's roughly correlated with real time. It'll advance by 1M versions/second except when it doesn't. Advancing the sequencer time doesn't mean waiting for however many seconds, it just means the sequencer jumps it's version numbers forward. 90s or 5s of versions can be advanced in an instant. I think there's a figure somewhere that shows the CDF of recovery unavailability, which was also basically a worst case graph as it was pulled from rather large clusters."
Replication
When a Proxy writes logs to LogServers, each sharded log record is synchronously replicated on f+1 LogServers. Only after all f+1 have replied with successful persistence, the Proxy sends back the commit response to the client. These WAL logs also does double-duty for simplifying replication to other datacenters and for providing automatic failover between regions without losing data.
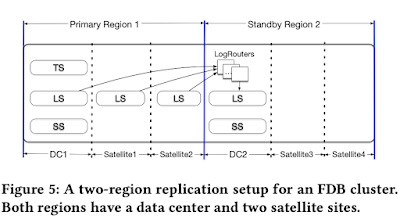
Figure 5 illustrates the layout of a two-region replication of a cluster. Both regions have a data center (DC) as well as one or more satellite sites. Satellites are located in close proximity to the DC (in the same region) but are failure independent. The resource requirements from satellites are insignificant as they only need to store log replicas (i.e., a suffix of the redo logs), while data centers host LS, SS, and (when primary) the TS. Control plane replicas (i.e., coordinators) are deployed across three or more failure domains (in some deployments utilizing an additional region), usually with at least 9 replicas. Relying on majority quorums allows the control plane to tolerate one site (data center/satellite) failure and an additional replica failure. The cluster automatically fails-over to the secondary region if the primary data center becomes unavailable. Satellite failures could, in some cases, also result in a fail-over, but this decision is currently manual. When the fail-over happens, DC2 might not have a suffix of the log, which it proceeds to recover from the remaining log server in the primary region. Next, we discuss several alternative satellite configurations which provide different levels of fault-tolerance.
Integrated deterministic simulation framework
Last but not least, the integrated deterministic simulation framework became a hallmark of FDB. Even before building the database itself, FDB team built a deterministic database simulation framework that can simulate a network of interacting processes using synthetic workloads and simulating disk/process/network failures and recoveries, all within a single physical process. FDB relies on this randomized, deterministic simulation framework for failure injecting and end-to-end testing of the correctness of its distributed database (with real code) in a single box. Since simulation tests (of course the synthetic workloads and assertions checking properties of FDB need to be written by developers) are both efficient and repeatable, they help developers debug deep bugs. Randomization/fuzzing of tuning parameters (response latency, error code return rate) in the simulation framework complements failure injection and ensures that specific performance tuning values do not accidentally become necessary for correctness. Maybe most important of all, the simulation framework also boosts developer productivity and the code quality, because it enables its developers to develop and test new features and releases in a rapid cadence in this single process testbox.
FDB was built from the ground up to make this testing approach possible. All database code is deterministic; multithreaded concurrency is avoided (one database node is deployed per core). Figure 6 illustrates the simulator process of FDB, where all sources of nondeterminism and communication are abstracted, including network, disk, time, and pseudo random number generator.
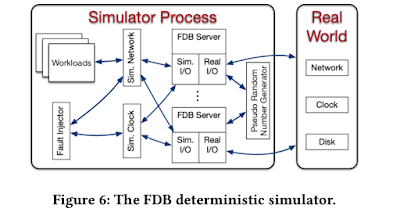
The amount of effort they put in to the simulator is impressive. They went the extra mile to optimize the simulator to improve testing coverage. The discrete-event simulator runs arbitrarily faster than real-time when the CPU utilization is low, since then the simulator can fast-forward clock to the next event. Additionally, bugs can be found faster simply by running more simulations in parallel. Randomized testing is embarrassingly parallel and FDB developers do "burst" the amount of testing they do immediately before major releases.
The payoff is also great. The paper shares this interesting anecdote. "The success of simulation has led us to continuously push the boundary of what is amenable to simulation testing by eliminating dependencies and reimplementing them ourselves in Flow. For example, early versions of FDB depended on Apache Zookeeper for coordination, which was deleted after real-world fault injection found two independent bugs in Zookeeper (circa 2010) and was replaced by a de novo Paxos implementation written in Flow (a novel syntactic extension to C++ adding async/await-like concurrency primitives). No production bugs have ever been reported since."
Evaluation
The paper shows evaluations from deployments with up to 25 nodes in a single DC. Under the traffic pattern (shown in Figure 7a) hitting Apple's FDB production two DC replicated deployment, Figure 7b
shows the average and 99.9-percentile of client read and commit latencies. For reads, the average and 99.9- percentile are about 1 and 19 ms, respectively. For commits, the average and 99.9-percentile are about 22 and 281 ms, respectively. The commit latencies are higher than read latencies because commits always write to multiple disks in both primary DC and one satellite. Note the average commit latency is lower than the WAN latency of 60.6 ms, due to asynchronous replication to the remote region. The 99.9-percentile latencies are an order of magnitude higher than the average, because they are affected by multiple factors such as the variability in request load, queue length, replica performance, and transaction or key value sizes.
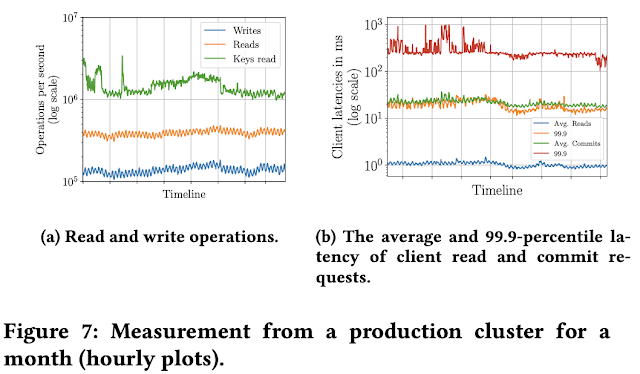
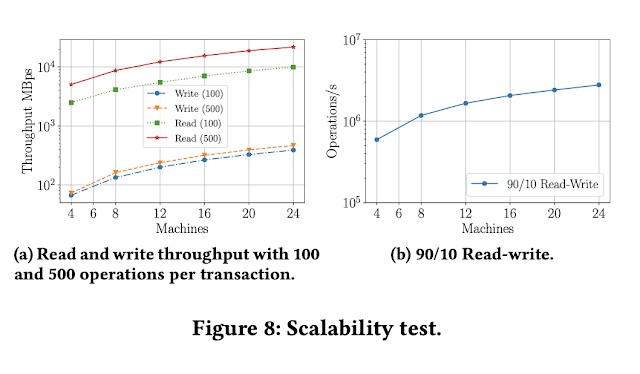
Figure 8 illustrates the scalability test of FDB from 4 to 24 machines using 2 to 22 Proxies or LogServers.






Comments
Hi Murat, I'm doing some research about distributed transactions. I'am really curious, about what you said about how does fdb support transition going from strict serializability to snapshot isolation consistency level. Would you explain more about it?
In my humble opinion, isolation levels usually only relates to conflicts resolving, I didn't quite get the point of relaxing GRV.