FoundationDB Record Layer: A Multi-Tenant Structured Datastore
This is a 2019 arxiv report. Back in 2019, when the report was out, I wrote a review about it, but did not publish it then because I felt I didn't have enough information on FoundationDB yet. With FoundationDB Sigmod 2021 paper out recently, I am now releasing that earlier write up. I will follow up on this soon with a review of the Sigmod21 paper on FoundationDB.
UPDATE: I wrote a summary of the Sigmod 2021 paper here.
Introduction
FoundationDB made a bold design choice of ACID key-value store. They had released a transaction manifesto:
- Everyone needs transactions
- Transactions make concurrency simple
- Transactions enable abstraction
- Transactions enable efficient data representations
- Transactions enable flexibility
- Transactions are not as expensive as you think
- Transactions are the future of NoSQL
FoundationDB, available as opensource, consists of the transactional minimalist storage engine as the base layer, and other layers are developed on top of the base layer to extend functionality. The record layer, that the report describes, is stateless!
Unfortunately, I couldn't find a paper explaining the base layer, the storage layer of FoundationDB (Update: Now there is the Sigmod'21 paper). This paper skips over the base layer, and I had to learn that through watching some YouTube talks.
FoundationDB, storage engine

I wanted to start with the base layer, although it is glossed over in this paper. The above figure from the FoundationDB website shows a logical abstraction picture of the base layer architecture, which is a distributed database that organizes data as an ordered key-value store with ACID transactions. The base layer is composed of two logical clusters, one for storing data and processing transactions, and one for coordinating membership & configuration of the first cluster (using Active Disk Paxos). Reads learn about which version (commit-timestamp) to read from the transactional authority and then directly contact the corresponding storage node to get the value. For commits, the transactional authority "somehow" enforces ACID guarantees and the storage nodes asynchronously copy updates from committed transactions. The paper does not elaborate on this, and says the following. FoundationDB provides ACID multi-key transactions with strictly-serializable isolation, implemented using multi-version concurrency control (MVCC). Neither reads nor writes are blocked by other readers or writers, instead conflicting transactions fail at commit time (and are usually retried by the client).
This figure is from the FoundationDB storage engine technical overview talk. Unfortunately, there is no paper or documentation explaining this more concrete/detailed architecture figure.
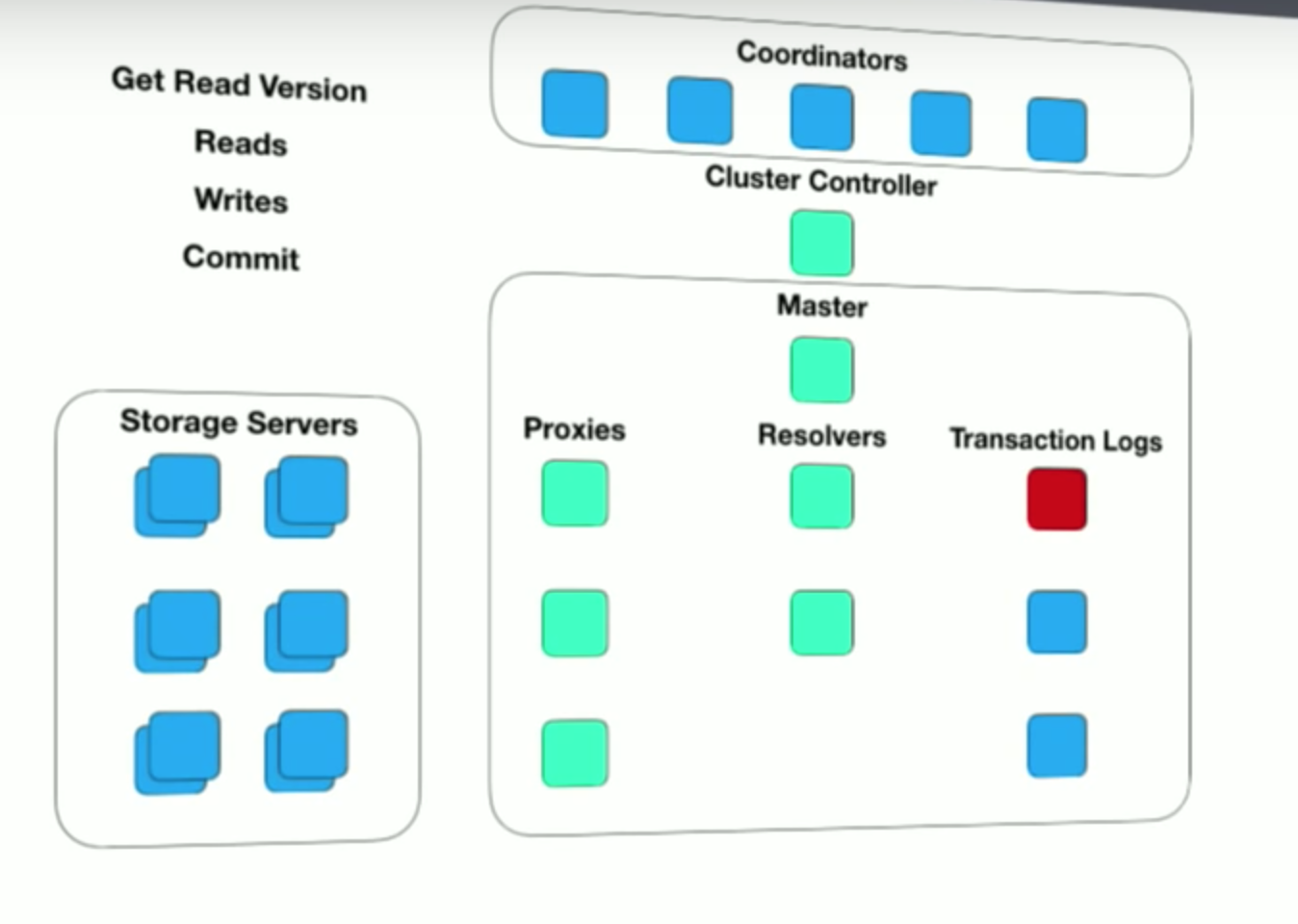
The transactional authority is comprised of 4 different type of components. The master is tasked with providing increasing monotonic timestamps, which serve as commit-times of transactions. Proxies accept commit requests and coordinate the commits. There are also resolvers to check if the transactions conflict with each other and fail the conflicting ones. Resolvers check the recent transactions to see if they have changed the read values in the transaction that the proxy is trying to commit. Resolvers are key-range sharded, for a multikey transaction many need to be contacted, leading to conflict amplification. Resolvers don't know about the decisions others are making for that transaction, so a resolver that thinks the transaction should be OK, may unnecessarily and indirectly causing further transactions to fail on behalf of this non-existing transaction that is potentially a conflict. Finally, the fourth type of component is the transaction logs. If the transaction clears the resolvers, it will be made durable at the transaction logs. Transaction logs are replicated for durability against a node crash.
The proxy waits until all transaction logs replicate the transaction, and then sends the commit to the client. Finally, the transaction logs are asynchronously streamed to the storage servers, so that the storage servers can execute them and make them durable. The proxies also need to communicate among each other very frequently: in order to ensure external consistency for Get-Read version requests, each proxy need to be aware of other every committed transaction on that key, which might have happened on another proxy. (I wonder if a data race condition is possible here? Does this mean proxy waits until it hears from all other proxies?) This is an intricate dance. The write takes 3-4 hops, if the components are on different nodes, this is going to add to the latency. The proxies and the resolvers need to exchange information continually, which makes them susceptible to become throughput and latency bottlenecks at scale.
Even if a single transaction log crashes, FoundationDB will create a new transactional authority cluster (a new master, new proxies, new resolvers, new transactional logs) and transfer the control to the new transactional authority, eliminating the old transactional authority. This seems excessive to handle a single transaction log/node failure. On the bright side, by handling any node failure with the same way, they get a pretty robust and well-exercised way of recovery.
The record layer
Keys are part of a single global namespace, and it is up to the applications to divide and manage that namespace with the help of APIs at higher layers. One example is a tuple layer. The tuple layer encodes tuples into keys such that the binary ordering of those keys preserves the ordering of tuples and the natural ordering of typed tuple elements. A common prefix of the tuple is serialized as a common byte prefix and defines a key subspace. E.g., a client may store the tuple (state, city) and later read using a prefix like (state,*).The record layer takes this further. It amends the key-value data model of the base layer, which is insufficient for applications that need structured data storage, indexing, and querying. It also provides the multi-tenancy features the base layer lacks: isolation, resource sharing, and elasticity.
The record layer provides schema management, a rich set of query and indexing facilities. The layer provides a KeySpace API which exposes the key space like a filesystem directory structure. The record layer also inherits FoundationDB's ACID semantics from the base layer, and ensures secondary indexes are updated transactionally with the data. Finally, it is stateless and lightweight.
I really like that the record layer is stateless. This simplifies scaling of the compute service: just launch more stateless instances. A stateless design means that load-balancers and routers need only consider where the data (at the base layer) are located, and need not worry about routing to specific compute servers that can serve them.
The record store abstraction
The layer achieves resource sharing and elasticity with its record store abstraction. Each record store is assigned a contiguous range of keys, ensuring that data belonging to different tenants is logically isolated.
The record store is the key abstraction here. The type of records in a record store are defined with Protocol Buffer definitions.
The schema, also called the metadata, of a record store is a set of record types and index definitions on these types. The metadata is versioned and stored separately.
The record store is responsible for storing raw records, indexes defined on the record fields, and the highest version of the metadata it was accessed with.
Isolation between record stores is key for multitenancy. The keys of each record store start with a unique binary prefix, defining a FoundationDB subspace, and the subspaces of different record stores do not overlap. To facilitate resource isolation further, the Record Layer tracks and enforces limits on resource consumption for each transaction, provides continuations to resume work, and can be coupled with external throttling.
Metadata management
Because the Record Layer is designed to support millions of independent databases with a common schema, it stores metadata separately from the underlying data. The common metadata can be updated atomically for all stores that use it.Since records are serialized into the underlying key-value store as Protocol Buffer messages, some basic data evolution properties are inherited. New fields can be added to a record type and show up as uninitialized in old records. New record types can be added without interfering with old records. As a best practice, field numbers are never reused and should be deprecated rather than removed altogether.
Indexing at the record layer
Index maintenance occurs in the same transaction as the record change itself, ensuring that indexes are always consistent with the data, achieved via FoundationDB's fast multi-key transactions. Efficient index scans use range reads and rely on the lexicographic ordering of stored keys.A key expression defines a logical path through records; applying it to a record extracts record field values and produces a tuple that becomes the primary key for the record or key of the index for which the expression is defined.
The index is updated using FoundationDB’s atomic mutations, which do not conflict with other mutations:
- COUNT: number of records
- COUNT UPDATES: num. times a field has been updated
- COUNT NON NULL: num. records where a field isn't null
- SUM: summation of a field's value across all records
- MAX (MIN) EVER: max (min) value ever assigned to a field, over all records, since the index has been created.
The Record Layer controls its resource consumption by limiting its semantics to those that can be implemented on streams of records. For example, it supports ordered queries (such as in SQL’s ORDER BY clause) only when there is an available index supporting the requested sort order. It doesn't create new joins. It looks like FoundationDB does not fully support SQL. I understand that at some point there was some work on a SQL layer, but it wasn't regarded very highly. "What’s Really New with NewSQL?" paper said this: "We exclude [FoundationDB] because this system was at its core a NoSQL key-value store with an inefficient SQL layer grafted on top of it."
For the record layer, the paper lists as future work the following: avoiding hotspots, providing more query operations, providing materialized views, and building higher layers providing some SQL like support.
CloudKit usecase
FoundationDB is used by CloudKit, Apple's cloud backend service to serve millions of users. Within CloudKit a given application is represented by a logical container, defined by a schema that specifies the record types, typed fields, and indexes that are needed to facilitate efficient record access and queries.The application clients store records within named zones to organize records into logical groups which can be selectively synced across client devices.

CloudKit was initially implemented using Cassandra; Cassandra prevented concurrency within a zone, and multi-record atomic operations were scoped to a single partition. The implementation of CloudKit on FoundationDB and the Record Layer addresses both issues. Transactions are now scoped to the entire database, allowing CloudKit zones to grow significantly larger than before. Transactions also support concurrent updates to different records within a zone.





Comments