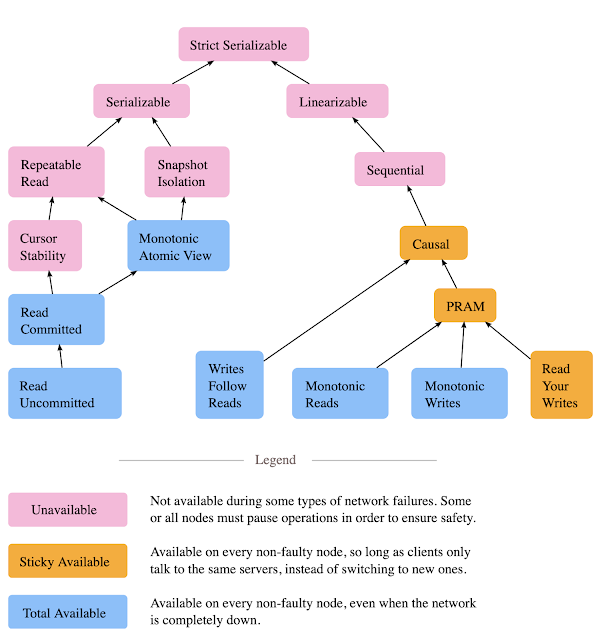
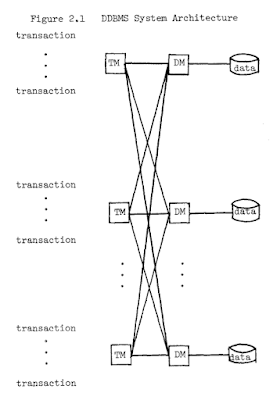
Best of Metadata in 2022
It is time to reflect back on the year. Here are some selected papers I covered in 2022. Production systems Amazon Aurora: Design Considerations + On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes Aurora provides a a high-throughput relational database on AWS cloud by decoupling the storage to a multi-tenant scale-out storage service. Each database instance acts as a SQL endpoint and supports query processing and transactions. Many database functions, such as redo logging, materialization of data blocks, garbage collection, and backup/restore, are offloaded to the storage nodes. Aurora performs replication among the storage nodes by pushing the redo log; this reduces networking traffic and enables fault-tolerant storage that heals without database involvement. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service (USENIX ATC 2022) DynamoDB has massive scale; it powers Alexa, Amazon.com sites, and all Amazon fulfillment c...