Paper summary. Dynet: The Dynamic Neural Network Toolkit
The programming model that underlies several popular toolkits such as TensorFlow uses a static declaration approach: they separate declaration and execution of the network architecture.
Static declaration has a number of advantages. After the computation graph is defined, it can be optimized in a number of ways so that the subsequent repeated executions of computation can be performed as quickly as possible. This also simplifies distribution of computation across multiple devices, as in TensorFlow. But static declaration is inconvenient for the following:
Of course, it is possible to process variable sized inputs if the computation graphs can represent objects whose size is unspecified at declaration time. Flow control operations such as conditional execution and iteration can be added to the inventory of operations supported by the computation graph. For example, to run an RNN over variable length sequences, Theano offers the scan operation, and TensorFlow offers the dynamic RNN operation.
While it is therefore possible to deal with variable architectures with static declaration in theory, that still poses some difficulties in practice:
These are associated with some serious software engineering risks. As an alternative, DyNet proposes reviving an alternative programming model: dynamic declaration of computation graphs.
Dynamic declaration reduces the complexity of the computation graph implementation since it does not need to contain flow control operations or support dynamically sized data. DyNet is designed to allow users to implement their models in their preferred programming language (C++ or Python). A symbolic computation graph is still constructed, but by using the host language (C++ or Python) rather than providing them separately at the computation graph level. Thus, dynamic declaration facilitates the implementation of more complicated network architectures.
DyNet's backend, which is written in C++, is optimized to remove overhead in computation graph construction, and support efficient execution on both CPU and GPU. This is feasible to do. Since flow control and facilities for dealing with variably sized inputs remain in the host language (rather than in the computation graph, as is required by static declaration), the computation graph needs to support fewer operation types, and these tend to be more completely specified (e.g., tensor sizes are always known rather than inferred at execution time).
1. Create a Model.
2. Add the necessary Parameters and LookupParameters to the model. Create a Trainer object and associate it with the Model.
3. For each input example:
(a) Create a new ComputationGraph, and populate it by building an Expression representing the desired computation for this example.
(b) Calculate the result of that computation forward through the graph by calling the value() or npvalue() functions of the final Expression
(c) If training, calculate an Expression representing the loss function, and use its backward() function to perform back-propagation
(d) Use the Trainer to update the parameters in the Model
In contrast to static declaration libraries such as TensorFlow, in DyNet the "create a graph" step falls within the loop. This has the advantage of allowing the user to flexibly create a new graph structure for each instance and to use flow control syntax (e.g., iteration) from their native programming language.
Here is an example program.
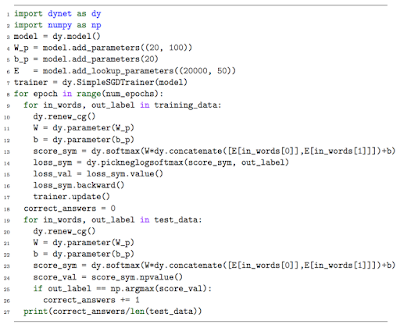
This program shows the process of performing maximum likelihood training for a simple classifier that calculates a vector of scores for each class it will be expected to predict, then returns the ID of the class with the highest score. Notice that, at line 14: symbolic graph is defined dynamically, at line 15: forward pass is executed, and at line 16: backward pass automatic diff is executed. At line 19, after the training, inference is done. To account for dynamic input/graphs at inference, the graph is reconstructed for each serving input.

Dynet allows dynamic flow control at the inference time easily. This can allow the classifier to avoid wasting processing time when the answer is clear. It is also possible to perform dynamic flow control at training time, and this supports more sophisticated training algorithms using reinforcement learning. These algorithms require interleaving model evaluation and decision making on the basis of that evaluation.
Petuum Inc. is working on extending this parallelism from single machine to multiple machines data-parallel processing, by using Poseidon machine-learning communication framework.
Static declaration has a number of advantages. After the computation graph is defined, it can be optimized in a number of ways so that the subsequent repeated executions of computation can be performed as quickly as possible. This also simplifies distribution of computation across multiple devices, as in TensorFlow. But static declaration is inconvenient for the following:
- variably sized inputs
- variably structured inputs
- nontrivial inference algorithms
- variably structured outputs
Of course, it is possible to process variable sized inputs if the computation graphs can represent objects whose size is unspecified at declaration time. Flow control operations such as conditional execution and iteration can be added to the inventory of operations supported by the computation graph. For example, to run an RNN over variable length sequences, Theano offers the scan operation, and TensorFlow offers the dynamic RNN operation.
While it is therefore possible to deal with variable architectures with static declaration in theory, that still poses some difficulties in practice:
- Difficulty in expressing complex flow-control logic
- Complexity of the computation graph implementation
- Difficulty in debugging
These are associated with some serious software engineering risks. As an alternative, DyNet proposes reviving an alternative programming model: dynamic declaration of computation graphs.
Dynamic declaration
The dynamic declaration model in Dynet takes a single-step approach: the user defines the computation graph programmatically as if they were calculating the outputs of their network on a particular training instance. There are no separate steps for definition and execution: the necessary computation graph is created, on the fly, as the loss calculation is executed, and a new graph is created for each training instance. (To avoid the overhead, DyNet strives to provide very lightweight graph construction.)Dynamic declaration reduces the complexity of the computation graph implementation since it does not need to contain flow control operations or support dynamically sized data. DyNet is designed to allow users to implement their models in their preferred programming language (C++ or Python). A symbolic computation graph is still constructed, but by using the host language (C++ or Python) rather than providing them separately at the computation graph level. Thus, dynamic declaration facilitates the implementation of more complicated network architectures.
What is the innovation in DyNet?
DyNet aims to minimize the computational cost of graph construction in order to allow efficient dynamic computation. This way DyNet aspires to remove barriers to rapid prototyping and implementation of more sophisticated applications of neural nets that are not easy to implement in the static computation paradigm.DyNet's backend, which is written in C++, is optimized to remove overhead in computation graph construction, and support efficient execution on both CPU and GPU. This is feasible to do. Since flow control and facilities for dealing with variably sized inputs remain in the host language (rather than in the computation graph, as is required by static declaration), the computation graph needs to support fewer operation types, and these tend to be more completely specified (e.g., tensor sizes are always known rather than inferred at execution time).
DyNet programs
DyNet programs follow the following template1. Create a Model.
2. Add the necessary Parameters and LookupParameters to the model. Create a Trainer object and associate it with the Model.
3. For each input example:
(a) Create a new ComputationGraph, and populate it by building an Expression representing the desired computation for this example.
(b) Calculate the result of that computation forward through the graph by calling the value() or npvalue() functions of the final Expression
(c) If training, calculate an Expression representing the loss function, and use its backward() function to perform back-propagation
(d) Use the Trainer to update the parameters in the Model
In contrast to static declaration libraries such as TensorFlow, in DyNet the "create a graph" step falls within the loop. This has the advantage of allowing the user to flexibly create a new graph structure for each instance and to use flow control syntax (e.g., iteration) from their native programming language.
Here is an example program.

This program shows the process of performing maximum likelihood training for a simple classifier that calculates a vector of scores for each class it will be expected to predict, then returns the ID of the class with the highest score. Notice that, at line 14: symbolic graph is defined dynamically, at line 15: forward pass is executed, and at line 16: backward pass automatic diff is executed. At line 19, after the training, inference is done. To account for dynamic input/graphs at inference, the graph is reconstructed for each serving input.

Dynet allows dynamic flow control at the inference time easily. This can allow the classifier to avoid wasting processing time when the answer is clear. It is also possible to perform dynamic flow control at training time, and this supports more sophisticated training algorithms using reinforcement learning. These algorithms require interleaving model evaluation and decision making on the basis of that evaluation.
How do we make DyNet distributed
Dynet is currently centralized. There is also support for automatic mini-batching to improve computational efficiency, taking the burden off of users who want to implement mini-batching in their models. For more complicated models that do not support mini-batching, there is support for data-parallel multi-processing, in which asynchronous parameter updates are performed across multiple threads, making it simple to parallelize (on a single machine) any variety of model at training time.Petuum Inc. is working on extending this parallelism from single machine to multiple machines data-parallel processing, by using Poseidon machine-learning communication framework.





Comments