Kafka, Samza, and the Unix Philosophy of Distributed Data
This paper is very related to the "Realtime Data Processing at Facebook" paper I reviewed in my previous post. As I mentioned there Kafka does basically the same thing as Facebook's Scribe, and Samza is a stream processing system on Kafka.
This paper is very easy to read. It is delightful in its simplicity. It summarizes the design of Apache Kafka and Apache Samza and compares their design principles to the design philosophy of Unix, in particular, Unix pipes.
Who says plumbing can't be sexy? (Seriously, don't Google this.) So without further ado, I present to you Mike Rowe of distributed systems.
In theory you can achieve this personalization goal with a batch workflow system, like MapReduce, which provides system scalability, organizational scalability (that of the engineering/development team's efforts), operational robustness, multi-consumer support, loose coupling, data provenance, and friendliness to experimentation. However, batch processing will add large delays. Stream processing systems preserve all the good scalability features of batch workflow systems, and add "timeliness" feature as well.
I am using shortened descriptions from the paper for the following sections.
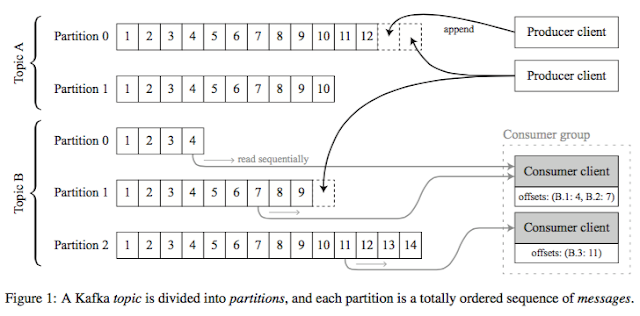
Kafka provides a publish-subscribe messaging service. Producer (publisher) clients write messages to a named topic, and consumer (subscriber) clients read messages in a topic. A topic is divided into partitions, and messages within a partition are totally ordered. There is no ordering guarantee across different partitions. The purpose of partitioning is to provide horizontal scalability: different partitions can reside on different machines, and no coordination across partitions is required.
Each partition is replicated across multiple Kafka broker nodes to tolerate node failures. One of a partition's replicas is chosen as leader, and the leader handles all reads and writes of messages in that partition. Writes are serialized by the leader and synchronously replicated to a configurable number of replicas. On leader failure, one of the in-sync replicas is chosen as the new leader.
The throughput of a single topic-partition is limited by the computing resources of a single broker node --the bottleneck is usually either its NIC bandwidth or the sequential write throughput of the broker's disks. When adding nodes to a Kafka cluster, some partitions can be reassigned to the new nodes, without changing the number of partitions in a topic. This rebalancing technique allows the cluster's computing resources to be increased or decreased without affecting partitioning semantics.

Figure 3 illustrates the use of partitions in the word-count example: by using the word as message key, the SplitWords task ensures that all occurrences of the same word are routed to the same partition of the words topic.

Samza implements durable state through the KeyValueStore abstraction, exemplified in Figure 2. Samza uses the RocksDB embedded key-value store, which provides low-latency, high-throughput access to data on local disk. To make the embedded store durable in the face of disk and node failures, every write to the store (i.e., the changelog) is also sent to a dedicated topic-partition in Kafka, as illustrated in Figure 4. When recovering after a failure, a task can rebuild its store contents by replaying its partition of the changelog from the beginning. Rebuilding a store from the log is only necessary if the RocksDB database is lost or corrupted. While the changelog publishing to Kafka for durability seems wasteful, it can also be a useful feature for applications: other stream processing jobs can consume the changelog topic like any other stream, and use it to perform further computations.

One characteristic form of stateful processing is a join of two or more input streams, most commonly an equi-join on a key (e.g. user ID). One type of join is a window join, in which messages from input streams A and B are matched if they have the same key, and occur within some time interval delta-t of one another. Alternatively, a stream may be joined against tabular data: for example, user clickstream events could be joined with user profile data, producing a stream of clickstream events with embedded information about the user. When joining with a table, the authors recommend to make the table data available in the form of a log-compacted stream through Kafka. Processing tasks can consume this stream to build an in-process replica of a database table partition, using the same approach as the recovery of durable local state, and then query it with low latency. It seems wasteful to me, but it looks like the authors do not feel worried about straining Kafka, and are comfortable with using Kafka as a work horse.
Even though the intermediate state between two Samza stream processing operators is always materialized to disk, Samza is able to provide good performance: a simple stream processing job can process over 1 million messages per second on one machine, and saturate a gigabit Ethernet NIC.
Apache Bookkeeper and Hedwig are good alternatives to Kafka
These days, there is also DistributedLog.
This paper is very easy to read. It is delightful in its simplicity. It summarizes the design of Apache Kafka and Apache Samza and compares their design principles to the design philosophy of Unix, in particular, Unix pipes.
Who says plumbing can't be sexy? (Seriously, don't Google this.) So without further ado, I present to you Mike Rowe of distributed systems.
Motivation/Applications
I had talked about the motivation and applications of stream processing in the Facebook post. The application domain is basically building web services that adapt to your behaviour and personalize on the fly, including Facebook, Quora, Linkedin, Twitter, Youtube, Amazon, etc. These webservices take in your most recent actions (likes, clicks, tweets), analyze it on the fly, merge with previous analytics on larger data, and adapt to your recent activity as part of a feedback loop.In theory you can achieve this personalization goal with a batch workflow system, like MapReduce, which provides system scalability, organizational scalability (that of the engineering/development team's efforts), operational robustness, multi-consumer support, loose coupling, data provenance, and friendliness to experimentation. However, batch processing will add large delays. Stream processing systems preserve all the good scalability features of batch workflow systems, and add "timeliness" feature as well.
I am using shortened descriptions from the paper for the following sections.
Apache Kafka

Kafka provides a publish-subscribe messaging service. Producer (publisher) clients write messages to a named topic, and consumer (subscriber) clients read messages in a topic. A topic is divided into partitions, and messages within a partition are totally ordered. There is no ordering guarantee across different partitions. The purpose of partitioning is to provide horizontal scalability: different partitions can reside on different machines, and no coordination across partitions is required.
Each partition is replicated across multiple Kafka broker nodes to tolerate node failures. One of a partition's replicas is chosen as leader, and the leader handles all reads and writes of messages in that partition. Writes are serialized by the leader and synchronously replicated to a configurable number of replicas. On leader failure, one of the in-sync replicas is chosen as the new leader.
The throughput of a single topic-partition is limited by the computing resources of a single broker node --the bottleneck is usually either its NIC bandwidth or the sequential write throughput of the broker's disks. When adding nodes to a Kafka cluster, some partitions can be reassigned to the new nodes, without changing the number of partitions in a topic. This rebalancing technique allows the cluster's computing resources to be increased or decreased without affecting partitioning semantics.
Apache Samza
A Samza job consists of a Kafka consumer, an event loop that calls application code to process incoming messages, and a Kafka producer that sends output messages back to Kafka. Unlike many other stream-processing frameworks, Samza does not implement its own network protocol for transporting messages from one operator to another.
Figure 3 illustrates the use of partitions in the word-count example: by using the word as message key, the SplitWords task ensures that all occurrences of the same word are routed to the same partition of the words topic.

Samza implements durable state through the KeyValueStore abstraction, exemplified in Figure 2. Samza uses the RocksDB embedded key-value store, which provides low-latency, high-throughput access to data on local disk. To make the embedded store durable in the face of disk and node failures, every write to the store (i.e., the changelog) is also sent to a dedicated topic-partition in Kafka, as illustrated in Figure 4. When recovering after a failure, a task can rebuild its store contents by replaying its partition of the changelog from the beginning. Rebuilding a store from the log is only necessary if the RocksDB database is lost or corrupted. While the changelog publishing to Kafka for durability seems wasteful, it can also be a useful feature for applications: other stream processing jobs can consume the changelog topic like any other stream, and use it to perform further computations.

One characteristic form of stateful processing is a join of two or more input streams, most commonly an equi-join on a key (e.g. user ID). One type of join is a window join, in which messages from input streams A and B are matched if they have the same key, and occur within some time interval delta-t of one another. Alternatively, a stream may be joined against tabular data: for example, user clickstream events could be joined with user profile data, producing a stream of clickstream events with embedded information about the user. When joining with a table, the authors recommend to make the table data available in the form of a log-compacted stream through Kafka. Processing tasks can consume this stream to build an in-process replica of a database table partition, using the same approach as the recovery of durable local state, and then query it with low latency. It seems wasteful to me, but it looks like the authors do not feel worried about straining Kafka, and are comfortable with using Kafka as a work horse.
Even though the intermediate state between two Samza stream processing operators is always materialized to disk, Samza is able to provide good performance: a simple stream processing job can process over 1 million messages per second on one machine, and saturate a gigabit Ethernet NIC.
Discussion
The paper includes a nice discussion section as well.- Since the only access methods supported by a log are an appending write and a sequential read from a given offset, Kafka avoids the complexity of implementing random-access indexes. By doing less work, Kafka is able to provide much better performance than systems with richer access methods. Kafka's focus on the log abstraction is reminiscent of the Unix philosophy: "Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new features."
- If Kafka is like a streaming version of HDFS, then Samza is like a streaming version of MapReduce. The pipeline is loosely coupled, since a job does not know the identity of the jobs upstream or downstream from it, only the topic names. This principle again evokes a Unix maxim: “Expect the output of every program to become the input to another, as yet unknown, program.”
- There are some key differences between Kafka topics and Unix pipes: A topic can have any number of consumers that do not interfere with each other, it tolerates failure of producers, consumers or brokers, and a topic is a named entity that can be used for tracing data provenance. Kafka topics deliberately do not provide backpressure: the on-disk log acts as an almost-unbounded buffer of messages.
- The log-oriented model of Kafka and Samza is fundamentally built on the idea of composing heterogeneous systems through the uniform interface of a replicated, partitioned log. Individual systems for data storage and processing are encouraged to do one thing well, and to use logs as input and output. Even though Kafka's logs are not the same as Unix pipes, they encourage composability, and thus Unix-style thinking.
Related links
Further reading on this is Jay Kreps excellent blog post on logs.Apache Bookkeeper and Hedwig are good alternatives to Kafka
These days, there is also DistributedLog.






Comments