Realtime Data Processing at Facebook
Recently there has been a lot of development in realtime data processing systems, including Twitter's Storm and Heron, Google's Millwheel, and LinkedIn's Samza. This paper presents Facebook's Realtime data processing system architecture and its Puma, Swift, and Stylus stream processing systems. The paper is titled "Realtime Data Processing at Facebook" and it appeared at Sigmod'16, June 26-July 1.
Another big application is the mobile analytics pipelines that provide realtime feedback for Facebook mobile application developers, who use this data to diagnose performance and correctness issues.
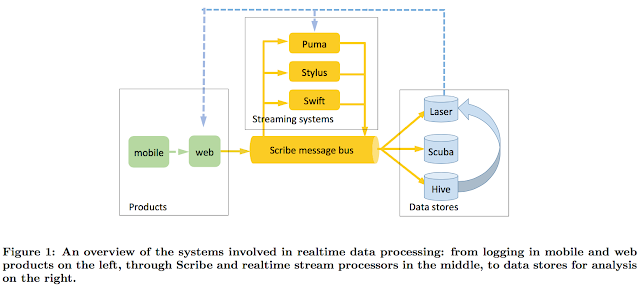
Scribe plays a central role in Facebook's realtime processing architecture. The main idea of the architecture is this: By trading seconds versus milliseconds latency, the architecture is able to employ a persistent message bus, i.e., Scribe, for data transport. Scribe provides a persistent, distributed messaging system for collecting, aggregating and delivering high volumes of log data with a few seconds of latency and high throughput. Scribe is the transport mechanism for sending data to both batch and realtime systems at Facebook. Using Scribe to decouple the data transport from the processing allows the system to achieve fault tolerance, scalability, and ease of use, as well as supporting multiple processing systems as options.
While Scribe incurs a few seconds of latency, it still meets Facebook's performance requirements for latency and provides hundreds of Gigabytes per second throughput. On the other hand, Scribe provides a persistent message bus service that enables decoupling and isolation of the data production and data analysis system components. Moreover, with persistent Scribe streams, the system can replay a stream from a recent time period, which makes debugging and iterative-development much easier.
The Kafka log blog by Jay Kreps described these benefits nicely as well. It talked about how practical systems can by simplified with a log-centric design, and how these log steams can enable data Integration by making all of an organization's data easily available in all its storage and processing systems. Kafka would have similar advantages to Scribe. Facebook uses Scribe because it is developed in house.
Below I copy snippets of descriptions from the paper for each of these subsystems.
Within Scribe, data is organized by distinct streams of "category". Usually, a streaming application consumes one Scribe category as input. A Scribe category has multiple buckets. A Scribe bucket is the basic processing unit for stream processing systems: applications are parallelized by sending different Scribe buckets to different processes. Scribe provides data durability by storing it in HDFS. Scribe messages are stored and streams can be replayed by the same or different receivers for up to a few days.
The realtime stream processing systems Puma, Stylus, and Swift read data from Scribe and also write to Scribe. Laser, Scuba, and Hive are data stores that use Scribe for ingestion and serve different types of queries. Laser can also provide data to the products and streaming systems, as shown by the dashed (blue) arrows.
Puma is a stream processing system whose applications (apps) are written in a SQL-like language with UDFs (user-defined functions) written in Java. Puma apps are quick to write: it can take less than an hour to write, test, and deploy a new app. Unlike traditional relational databases, Puma is optimized for compiled queries, not for ad-hoc analysis. Puma provides filtering and processing of Scribe streams (with a few seconds delay). The output of these stateless Puma apps is another Scribe stream, which can then be the input to another Puma app, any other realtime stream processor, or a data store.
Swift is a basic stream processing engine which provides checkpointing functionalities for Scribe. If the app crashes, you can restart from the latest checkpoint; all data is thus read at least once from Scribe. Swift is mostly useful for low throughput, stateless processing.
Stylus is a low-level stream processing framework written in C++. A Stylus processor can be stateless or stateful. Stylus's processing API is similar to that of other procedural stream processing systems.
Laser is a high query throughput, low (millisecond) latency, key-value storage service built on top of RocksDB. Laser can be used to make the result of a complex Hive query or a Scribe stream available to a Puma or Stylus app, usually for a lookup join, such as identifying the topic for a given hashtag.
Scuba is Facebook's fast slice-and-dice analysis data store, most commonly used for trouble-shooting of problems as they happen. Scuba provides ad hoc queries with most response times under 1 second.
Hive is Facebook's exabyte-scale data warehouse. Facebook generates multiple new petabytes of data per day, about half of which is raw event data ingested from Scribe. (The other half of the data is derived from the raw data, e.g., by daily query pipelines.) Most event tables in Hive are partitioned by day. Scribe does not provide infinite retention; instead Facebook stores input and output streams in our data warehouse Hive for longer retention.

Figure 4 summarizes the five design decisions considered for this Facebook realtime processing system components. Figure 5 summarizes which alternatives were chosen by a variety of realtime systems, both at Facebook and in the related literature.
The highlights from this section are as follows:
Holistic Configuration Management at Facebook
Facebook's Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
Measuring and Understanding Consistency at Facebook
Motivation and applications
Facebook runs hundreds of realtime data pipelines in productions. As a motivation of the realtime data processing system the paper gives Chorus as an example. The Chorus data pipeline transforms a stream of individual Facebook posts into aggregated, anonymized, and annotated visual summaries. E.g., what are the top 5 topics being discussed for the election today? What are the demographic breakdowns (age, gender, country) of World Cup fans?Another big application is the mobile analytics pipelines that provide realtime feedback for Facebook mobile application developers, who use this data to diagnose performance and correctness issues.
The system architecture

Scribe plays a central role in Facebook's realtime processing architecture. The main idea of the architecture is this: By trading seconds versus milliseconds latency, the architecture is able to employ a persistent message bus, i.e., Scribe, for data transport. Scribe provides a persistent, distributed messaging system for collecting, aggregating and delivering high volumes of log data with a few seconds of latency and high throughput. Scribe is the transport mechanism for sending data to both batch and realtime systems at Facebook. Using Scribe to decouple the data transport from the processing allows the system to achieve fault tolerance, scalability, and ease of use, as well as supporting multiple processing systems as options.
While Scribe incurs a few seconds of latency, it still meets Facebook's performance requirements for latency and provides hundreds of Gigabytes per second throughput. On the other hand, Scribe provides a persistent message bus service that enables decoupling and isolation of the data production and data analysis system components. Moreover, with persistent Scribe streams, the system can replay a stream from a recent time period, which makes debugging and iterative-development much easier.
The Kafka log blog by Jay Kreps described these benefits nicely as well. It talked about how practical systems can by simplified with a log-centric design, and how these log steams can enable data Integration by making all of an organization's data easily available in all its storage and processing systems. Kafka would have similar advantages to Scribe. Facebook uses Scribe because it is developed in house.
Below I copy snippets of descriptions from the paper for each of these subsystems.
Within Scribe, data is organized by distinct streams of "category". Usually, a streaming application consumes one Scribe category as input. A Scribe category has multiple buckets. A Scribe bucket is the basic processing unit for stream processing systems: applications are parallelized by sending different Scribe buckets to different processes. Scribe provides data durability by storing it in HDFS. Scribe messages are stored and streams can be replayed by the same or different receivers for up to a few days.
The realtime stream processing systems Puma, Stylus, and Swift read data from Scribe and also write to Scribe. Laser, Scuba, and Hive are data stores that use Scribe for ingestion and serve different types of queries. Laser can also provide data to the products and streaming systems, as shown by the dashed (blue) arrows.
Puma is a stream processing system whose applications (apps) are written in a SQL-like language with UDFs (user-defined functions) written in Java. Puma apps are quick to write: it can take less than an hour to write, test, and deploy a new app. Unlike traditional relational databases, Puma is optimized for compiled queries, not for ad-hoc analysis. Puma provides filtering and processing of Scribe streams (with a few seconds delay). The output of these stateless Puma apps is another Scribe stream, which can then be the input to another Puma app, any other realtime stream processor, or a data store.
Swift is a basic stream processing engine which provides checkpointing functionalities for Scribe. If the app crashes, you can restart from the latest checkpoint; all data is thus read at least once from Scribe. Swift is mostly useful for low throughput, stateless processing.
Stylus is a low-level stream processing framework written in C++. A Stylus processor can be stateless or stateful. Stylus's processing API is similar to that of other procedural stream processing systems.
Laser is a high query throughput, low (millisecond) latency, key-value storage service built on top of RocksDB. Laser can be used to make the result of a complex Hive query or a Scribe stream available to a Puma or Stylus app, usually for a lookup join, such as identifying the topic for a given hashtag.
Scuba is Facebook's fast slice-and-dice analysis data store, most commonly used for trouble-shooting of problems as they happen. Scuba provides ad hoc queries with most response times under 1 second.
Hive is Facebook's exabyte-scale data warehouse. Facebook generates multiple new petabytes of data per day, about half of which is raw event data ingested from Scribe. (The other half of the data is derived from the raw data, e.g., by daily query pipelines.) Most event tables in Hive are partitioned by day. Scribe does not provide infinite retention; instead Facebook stores input and output streams in our data warehouse Hive for longer retention.
Design decisions

Figure 4 summarizes the five design decisions considered for this Facebook realtime processing system components. Figure 5 summarizes which alternatives were chosen by a variety of realtime systems, both at Facebook and in the related literature.
Lessons learned
The paper includes a great lessons learned section. It says: "It is not enough to provide a framework for users to write applications. Ease of use encompasses debugging, deployment, and monitoring, as well. The value of tools that make operation easier is underestimated. In our experience, every time we add a new tool, we are surprised that we managed without it."The highlights from this section are as follows:
- There is no single language that fits all use cases. Needing different languages (and the different levels of ease of use and performance they provide) is the main reason why Facebook has three different stream processing systems, Puma, Swift, and Stylus.
- The ease or hassle of deploying and maintaining the application is equally important. Making Puma deployment self-service let them scale to the hundreds of data pipelines that use Puma. (See Facebook's holistic configuration management about what type of systems Facebook employs to manage/facilitate deployments.)
- Once an app is deployed, we need to monitor it: Is it using the right amount of parallelism? With Scribe, changing the parallelism is often just changing the number of Scribe buckets and restarting the nodes that output and consume that Scribe category. To find out the right amount of parallelism needed, Facebook uses alerts to detect when an app is processing its Scribe input more slowly than the input is being generated.
- Streaming versus batch processing is not an either/or decision. Originally, all data warehouse processing at Facebook was batch processing. Using a mix of streaming and batch processing can speed up long pipelines by hours.
Related posts
Facebook's software architectureHolistic Configuration Management at Facebook
Facebook's Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
Measuring and Understanding Consistency at Facebook





Comments