SIGMOD/PODS Day 1
This week I am attending the SIGMOD/PODS conference at Seattle. I am a bit out of my depth here, because I am a distributed systems person putting on a database hat. But so far, so good. I am happy to see that I am able to follow most talks well. I also enjoyed meeting and talking with many database people in coffee breaks and the receptions.
Today, day 1, was the PODS conference. I thought PODS was like about storage systems, because you know, in US we see these PODS boxes that are used to pack/store and transport stuff. As I attended PODS talk after another and saw blocks of Greek symbols and formulas, it dawned on me to check what the acronym meant. Turns out PODS stands for "Symposium on Principles of Database Systems". Like its namesake "Principles of Distributed Computing (PODC)", PODS is also a theory conference. These two conferences use "principles" as a code word for theory, I guess. I don't see why that would be the case though, I like my practical systems principled as well! In fact the top venue in practical systems is titled: "SOSP: Symposium on Operating Systems Principles".
Another surprise for me was to meet a lot of graph processing people in SIGMOD/PODS. I didn't expect to see so many graph processing people. And of course there are a lot of machine learning people as well. (Everybody is an ML person these days!) Based on my sampling set, the number of core database people had to be a small minority.
Ok, so here are some notes on some of the talks I attended and liked. These are from PODS. SIGMOD sessions start tomorrow.
PODS keynote: "Databases as Graphs: Predictive Queries for Declarative Machine Learning", Jure Leskovec, Stanford University
The PODS keynote was about how to do ML over relational databases. Jure did an excellent job packing an impressive amount of work/results into an easy to follow presentation. They build a startup, called Kumo, based on the idea, and released an opensource framework (PyG) as well.
ML has been delivering wonders for computer vision (with deep convolutional neural networks) and for natural language processing and text (with transformers). But the modern deep learning toolbox is designed for simple input, simple data types: matrix of bits.
As a result, Jure argues, the today's ML system architectures for data systems are complex brittle, they are expensive and slow to build, and hard to maintain. It takes 6-12 months for a team of data scientists, engineers, and product managers to stand up first iteration of systems.
There is an impedance mismatch on how data is stored (relational), and how it needs to be as input for ML (matrix of bits).
One way to address this is to transform tables into a simple table by denormalizing them, and add a final column for the label that ml predicts. But this has a lot of problems. Firstly, this leads to a state explosion and result in large number of rows/columns. Secondly, you need to compute a lot of features first, and the features are chosen arbitrarily using aggregations/time windows. Other problems are with respect to training examples being isolated from each other, using a limited set of data, and the potential of point-in-time correctness/information leakage.
Ok, then, can we address the problem head on? Can we build a DNN for databases, point it to the database, and make it learn directly from the database? This will give more accurate models, and shorten the time to go to production.
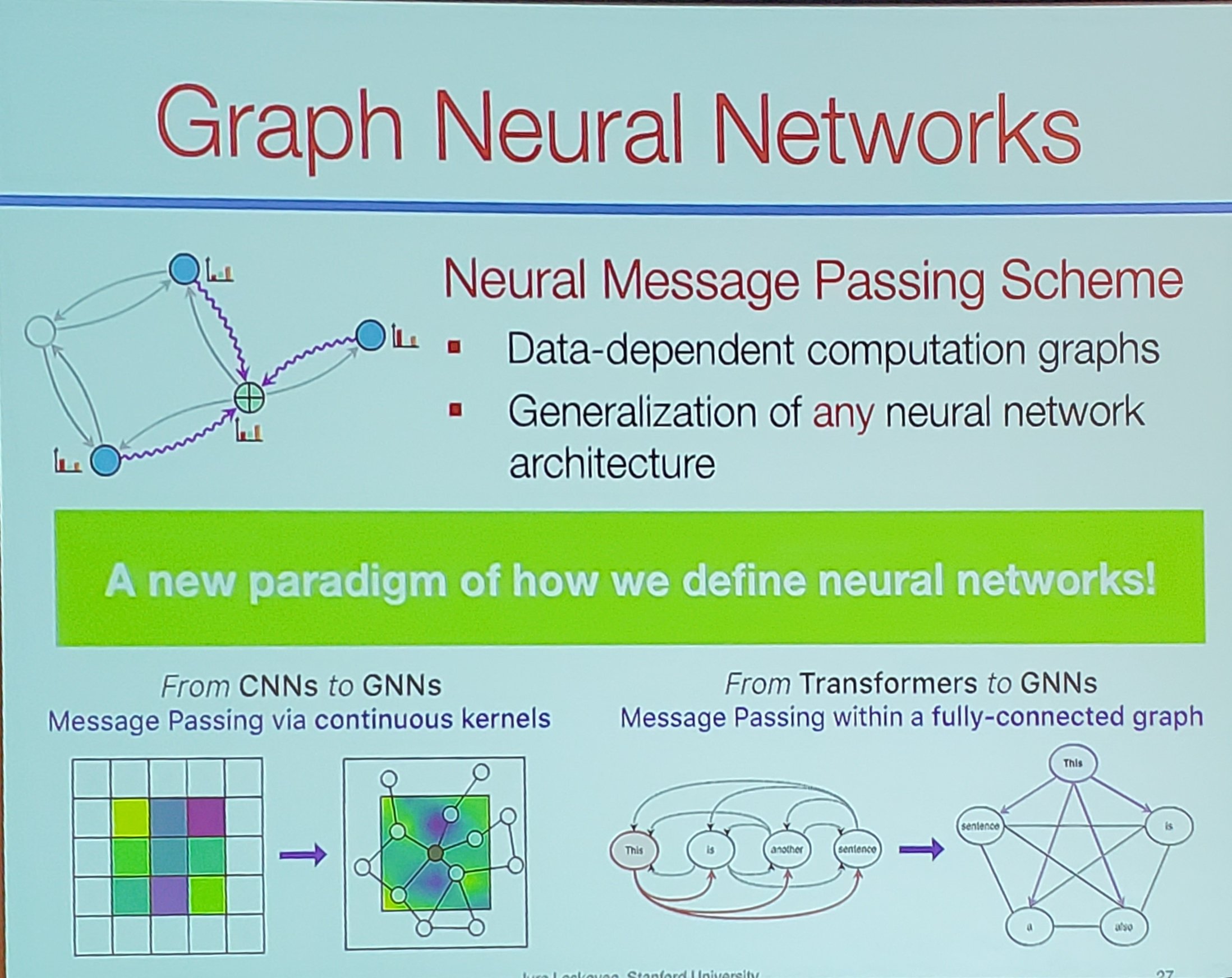
The question is: How do you generalize deep learning to a database? The insight is to treat your data as a graph! (Well, Jure is a graph processing person after all.)
Given a database with a set of table, construct G(V,E) where the set of nodes V is defined by all rows in all tables, and the set of edges E is defined by all matching keys. We create connections through fact tables as hyperedges (which is a generalization of an edge that connects multiple nodes).
Jure calls this novel concept graph neural network (GNN). Photo credit C. Mohan.
Every node defines a computation graph based on its neighborhood. In GNNs, nodes perform a join and aggregation without materializing that join. Nodes learn how to optimally use info from their neighbors graph to obtain enhanced node representations, and children aggregate information before sending to parent. This is like pushing ML in the graph.
The main benefits of GNNs are that we don't need to do manual feature engineering, we can have end to end data driven machine learning, and we can have drastic simplification of process and cut down on time to production.
Using GNNs, you can do analysis at different levels: node-level (churn,lifetime value), link-level(product affinity, recommendations), and graph-level (fraud detection).
Predictive queries would look like the following. The system interprets the query and automatically generates a training table.
PREDICT SUM(spend.amount WHERE spend.state= NY, 0, 30, days)
FOR EACH user.ID WHERE LIST_DISTINCT(spend.state, -30, 0, days) CONTAINS NY
Jure's startup Kumo implements the predictive query platform which can have efficient scaling to 50 billion entities. This is built on top of PyG graph learning framework they released. Using the H&M data publicly available from Kaggle they showed that predquery scores top 2% out of the box with a single GNN model, with no feature engineering, and no model ensembling.
(Gems of PODS) Applications of Sketching and Pathways to Impact Graham Cormode (Facebook and University of Warwick)
Turns out this is a recently new tradition at PODS. They get an invited short paper and talk to draw attention and summarize a certain line of work. Almost like systematization of knowledge (SoK) papers some conferences have.
Graham's talk was an overview of the data summary algorithms, known as sketches. Sketches are compact data structures that capture certain properties of data. Sketches may be updated incrementally or merged together. They answer queries with approx guarantees, e.g., how many distinct items seen, capture frequency distributions, etc. Sketches are a good example of how theory can be used to improve applications, and the talk did a review.
Early history of sketching involve reservoir sampling algs (60s), Bloom filters (70s), Morris counter O(log log n) bits (1977), Munro & Paterson median finding in few passes, Flakolet & Martin distinct counting, Johnson-Lindenstrauss lemma for dimensionality reduction.
This is followed by streaming years, with AMS sketching, LSH (Indyk-Motwani) approximate similarity 1998, Q-digest for quantiles 2004. Which is followed by work on mergeability, with compressed sensing 2004, HLL+ from Google 2013, mergeable summaries
Sketching also found applications in multimedia search, online advertising, and
big data analytics. The applications in big data analytics diminished after sometime, because data warehouses caught up and started providing exact answers to queries in reasonable time.
Finally sketching also found applications in private data analysis, including the differential privacy work deployed at Apple.
In lessons learned, Graham emphasized the importance of communicating sketches research ideas more accessibly via blogs, talks, and working directly with companies, and incorporating them into undergraduate teaching. He believes, this would have improved the technology transfer on sketches and would have improved adoption and provide efficiency returns. He is right you know. I have seen people run hours of Hadoop jobs on many machines, which clever algorithms would solve in minutes on a laptop.
Test of time awards
PODS had two test of time awards for papers published 10 years ago in PODS 2013. The authors did a short presentation of their earlier papers, and discussed how things changed since then.
The first one was "Communication steps for parallel query processing" by Paul Beame, Paraschos Koutris, and Dan Suciu. The paper formalized a massive parallel computation (MPC) model with local computation followed by barrier sync at the end of each round to go on for multiple rounds, and proved upper bounds and lower bounds on how many global communication steps are needed to compute a relational query over the data.
The second was "Ontology-based data access: a study through disjunctive datalog, CSP, and MMSNP" by Meghyn Bienvenu, Balder ten Cate, Carsten Lutz, and Frank Wolter. Ontology provides domain knowledge for queries, and enable filtering based on that. The paper considered the following questions about OMQs: expressive power and descriptive complexity of OMQs, which OMQs can be answered in PTimes, which are coNP-hard, and when can OMQs be rewritten as first order (FO) queries? The main contribution of the paper was to show a tight connection to constraint satisfaction problems (CSPs).
Allocating Isolation Levels to Transactions in a Multiversion Setting
This paper asks the question that, if we are given more knowledge on the workload (think of stored procedures in a database), can we choose a weaker isolation and still guarantee serializability.
A workload is said to be robust for an isolation level, if all executions under that isolation are serializable equivalent. Famously, TPC-C is shown to be robust under snapshot isolation (Fekete et al 2005).
We can go finer granularity and mix and match, if we can set isolation level for each transaction independently (for example postgres allows this for RC, SI, and SSI). This paper adopts this model, and explores if we can find the optimal isolation level for each transaction while keeping robustness.
An optimal allocation is when we cannot lower the isolation level of any transaction without violating robustness. The paper is on the theory side on theme with PODS, and proves some properties about the model, and gives a polynomial time algorithm for constructing the optimal allocation for a given set of transactions. Unfortunately there isn't a tool/implementation to compute and check robustness for a given set of transaction.
DAMON workshop papers
There was a parallel workshop track called Data Management on New Hardware (DaMoN). There are some interesting papers and talks there, but I was unable to attend them due to overlapping talks at PODS.
My random likes and gripes
Likes
People are friendlier (and more laid back) than people in systems and networking conferences. This is my subjective view! I don't want to start a flamewar (with systems and networking people :-).
I love that the elevator to the guest rooms is just 20 seconds from the conference rooms. I can go to my room to get some headroom when I am overwhelmed.
Amazon is the diamond sponsor of the conference. Thanks Amazon!
Gripes
Many PODS talks lacked practical takeaways. I approached a couple speakers after their talks to ask about the practical takeaways, but I didn't get satisfactory answers. If I could have it my way, I would have PODS talks to include an obligatory slide titled "Practical Takeaways". It would be OK for that slide to be empty. In any case, this would be very helpful to non-PODS people attending the talks. Also what is with that Greek letter soup in the slides. The talk is for communicating the idea and insights. If people find it interesting, they can read the full paper.
This is again my subjective perspective. I guess some theory people would find SIGMOD too far in the applied spectrum. (Credit XKCD)

There must be more than 500 people staying in the hotel, but only a handful people use the gym and the pool.






Comments