Empowering Azure Storage with RDMA
This paper appeared in Usenix'23 last week. The paper presents the experience of deploying across datacenter (i.e., intra-region) Remote Direct Memory Access (RDMA) to support storage workloads in Azure. The paper reports that around 70% of traffic in Azure is RDMA and intra-region RDMA is supported in all Azure public regions.
RDMA is a network technology that offloads the network stack to the network interface card (NIC) hardware. By allowing direct memory access from one computer to another without involving the OS or the CPU, RDMA helps achieve low latency, high throughput and near zero CPU overhead. This means that RDMA frees up CPU cores from processing networking packets, and allows Azure to sell these CPU cycles as customer virtual machines (VMs) or use for application processing.
Although RDMA solutions have been around and being deployed at small scales for a decade now, the paper provides an experience report from a large production system, and talks about practical challenges involved in getting this technology rolled. Here are some contributions of the paper.
- It provides a comprehensive overview of the network and storage architecture of Azure, and explains the motivation for adopting RDMA as the transport layer for storage workloads.
- It identifies and addresses several new challenges that arise from enabling RDMA at regional scale, such as interoperability between different types of RDMA NICs, heterogeneity of switch software and hardware from multiple vendors, and large round-trip time variations within a region.
- It describes the design and implementation of RDMA-based storage protocols for frontend traffic (i.e., sK-RDMA which runs in kernel space and handles traffic between compute VMs and storage clusters) and backend traffic (i.e, sU-RDMA which runs in user space and handles traffic within a storage cluster) that seamlessly integrate with the legacy storage stack and provide dynamic transition between RDMA and TCP.
- It introduces RDMA Estats, a fine-grained telemetry system that provides visibility into the host network stack by providing an accurate breakdown of cost for each RDMA operation.
- It evaluates the performance and benefits of RDMA for storage workloads in Azure using real-world data and experiments.
The presentation of the paper could be better. In general, I find that the quality of writing in papers written by a large number of coauthors is often worse than those written by a couple coauthors. This is probably due to design by committee effect. The paper provides sufficient background information on Azure's network and storage architecture, as well as RDMA technology. But, it explains things at the engineering level with some detail, which results in the user getting lost in the wall of text of the middle sections. I would have loved it better if they could communicate the insights without drowning the reader in details and offloading the burden of distilling the insights to the reader.
Background
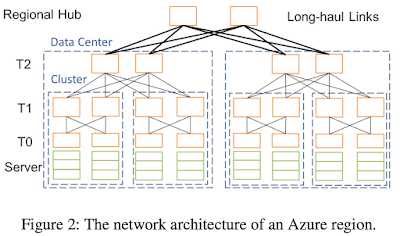
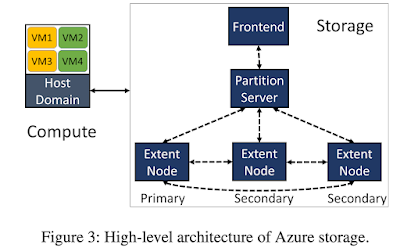
Challenges
In Azure, due to capacity issues, corresponding compute and storage clusters may be located in different datacenters within a region. This imposes a requirement that Azure's storage workloads rely on support for RDMA at regional scale. Enabling intra-region RDMA over the legacy infrastructure introduces many new challenges:
- Interoperability between different types of RDMA NICs: Azure has deployed three generations of commodity RDMA NICs from a popular NIC vendor: Gen1, Gen2 and Gen3. Each NIC generation has a different implementation of Data Center Quantized Congestion Notification (DCQCN), a congestion control algorithm for RDMA. This results in many undesired interactions when different NIC generations communicate with each other. To solve this problem, Azure updated the firmware of NICs to unify their DCQCN behaviors.
- Heterogeneity of switch software and hardware from multiple vendors: Azure has deployed many switch ASICs and multiple switch OSes from different vendors. However, this has increased the operational effort significantly because many aspects are vendor specific, such as buffer architectures, sizes, allocation mechanisms, monitoring and configuration. To solve this problem, Azure developed and deployed an in-house cross-platform switch OS called Software for Open Networking in the Cloud (SONiC), which manages heterogeneous switches from multiple vendors with a simplified and unified software stack.
- Heterogeneity of latency within a region: As shown in Figure 2, there are large round-trip time (RTT) variations from several microseconds to 2 milliseconds within a region, due to long-haul links between datacenters. This brings new challenges to congestion control and Priority-based Flow Control (PFC), a mechanism to prevent packet losses due to congestion. To solve this problem, Azure carefully tuned DCQCN and switch buffer parameters to optimize performance across different scenarios.
Experience

Miscellaneous
Here are some miscellaneous things I found interesting.
According to the paper, deep packet buffers are needed on chassis switches at T2 and RH to store RDMA packets. This is because these switches have high port density and long-haul links, which demand much larger PFC headroom than that of intra-cluster links. PFC headroom is a dedicated buffer space to absorb in-flight packets before the PFC pause frame takes effect on the upstream device. The paper also leverages off-chip DRAM to provide deep packet buffers on chassis switches, which can provide abundant buffer space for PFC headroom.
Unlike TCP, RDMA uses rate based congestion control without tracking the number of in-flight packets (the window size). Hence, RDMA tends to inject excessive in-flight packets, thus triggering PFC. To mitigate this, they implemented a static flow control mechanism in the Azure Storage Network Protocol by dividing a message into fixed-sized chunks and only allowing a single in-flight chunk for each connection. Chunking can significantly improve performance under high-degree incast with negligible CPU overhead.
They use nightly tests to track the quality of SONiC switches. They spent significant attention to build both software and hardware test harnesses for testing RDMA features with SONiC switches. This even involves setting breakpoints, and checking the buffer contents of switches at those points.
The paper discussed some lessons learned from the experience. I found these two important.
Failovers are very expensive for RDMA. While Azure implemented failover solutions in both sU-RDMA and sKRDMA as the last resort, they find that failovers are particularly expensive for RDMA, and should be avoided as much as possible. Cloud providers adopt RDMA to save CPU cores and then use freed CPU cores for other purposes. To move traffic away from RDMA, we need to allocate extra CPU cores to carry these traffic. This increases CPU utilization, and even runs out of CPU cores at high loads. Hence, performing large-scale RDMA failovers is treated as serious incidents in Azure.
Switch buffer is increasingly important and needs more innovations. The conventional wisdom suggests that low latency datacenter congestion control can alleviate the need of large switch buffers as they can preserve short queues. However, they find a strong correlation between switch buffers and RDMA performance problems in production. The importance of switch buffer lies in the prevalence of bursty traffic and short-lived congestion events in datacenters. Conventional congestion control solutions are ill-suited for such scenarios given their reactive nature. Instead, switch buffer plays as the first resort to absorb bursts and provide fast responses. The paper follows up with this on this topic: "Following the trend of programmable data plane, we envision that future switch ASICs would provide more programmability on buffer models and interfaces, thus enabling the implementation of more effective buffer management solutions."





Comments