Consus: Taming the Paxi
This is a 2016 paper by Robert Escriva and Robbert van Renesse. As far as I can see the paper did not get published in a conference or journal, but it is available on arxiv. The code (C++) is also available as opensource.
Consus introduces a leaderless-consensus-based commit protocol that completes in three one way message delays in the wide area. If your data centers were equidistant from each other with a uniform round trip time of 100ms between any pair of data centers, that means Consus could commit each transaction with 150ms of wide area latency.
In this setup, each data center has a full replica of the data and a transaction processing engine. The transaction processor executes the transaction against the local data center, and through the Consus-commit protocol it achieves serializable transaction execution. (The fully replicated requirement can be relaxed, I think, if the voting is on the outcome of partial transactions in each datacenter.)
Commit protocol
The commit protocol is based upon generalized consensus. Consus defers all inter-data center communication to the commit protocol, which both globally replicate transactions and decide their outcomes.
The commit protocol has 3 phases.
- In the first phase, a single datacenter (the one that the client contacts, presumably because it is the closest one) executes the transaction; if the transaction executes to completion, it is sent to other data centers alongside sufficient information to determine that these data centers' executions match the execution in the original data center.
- In the second phase, each datacenter broadcasts the result of its own execution--whether it was able to reproduce the original execution-- to all other data centers.
- In the final phase, the datacenters feed these results to an instance of Generalized Paxos that allows all data centers to learn the transaction’s outcome.

The below figure illustrates how leaderless/generalized Paxos works, compared to a leader-based classical Paxos. Generalized Paxos has a fast path where acceptors can accept proposals without communicating with other acceptors back-and-forth.

But, when acceptors accept conflicting posets (partial ordered sets), a classic round of Paxos is necessary.

When adopting the generalized Paxos for the commit protocol, Consus makes the set of learnable commands be outcomes for the different data centers. Outcomes are incomparable in acceptors’ posets (effectively making them unordered sets). After accepting an outcome, the datacenters broadcast the newly accepted state, and each data center’s learner will eventually learn the same poset. This does give that one way communication in phase-3 (guaranteed I think) for deciding/learning the fate of the transaction.
The paper mentions that with this setup, it is possible for transactions to deadlock using the inter-datacenter commit protocol. To prevent deadlock, the commit protocol accepts upcalls from the transaction execution component that indicate when a transaction may be potentially dead- locked. Such an upcall signals to the commit protocol that the transaction might not ever commit and the proto- col should act to avoid the deadlock. This is totally ordered with respect to all other commands, and may invoke slow path to abort a transaction.
Paxos variants used in Consus implementation
Consus uses several different Paxos flavors/optimizations in its implementation.
Client-as-Leader: Client holds a permanent ballot for transaction log. Transaction is fate shared with the client; this helps for optimizing away much of Paxos there.
Gray-Lamport Paxos Commit: This is for intra-datacenter transaction execution. The N instances of Paxos vote on commit.Each participant leads a round of Paxos to record its desire to commit or abort.

Generalized Paxos is used in the inter-datacenter commit protocol as described above. It uses one acceptor per data center computes commit or abort for transaction
Recursive Paxos: Consus's commit protocol uses Paxos across multiple data centers with a different member of the Paxos group in each. We would like for these different members to never fail unless the data center containing them fails. This is achieved again by using a recursive Generalized Paxos-replicated state machine. Each datacenter’s acceptor is a Paxos replicated state machine. This ensures a single server failure doesn't cause disruption.
The paper was very hard to follow for me with many ideas and with a presentation that is opaque to me. The recursive Paxos discussion is an example of this. I wasn't able to follow this well, without a figure and clearer explanation.
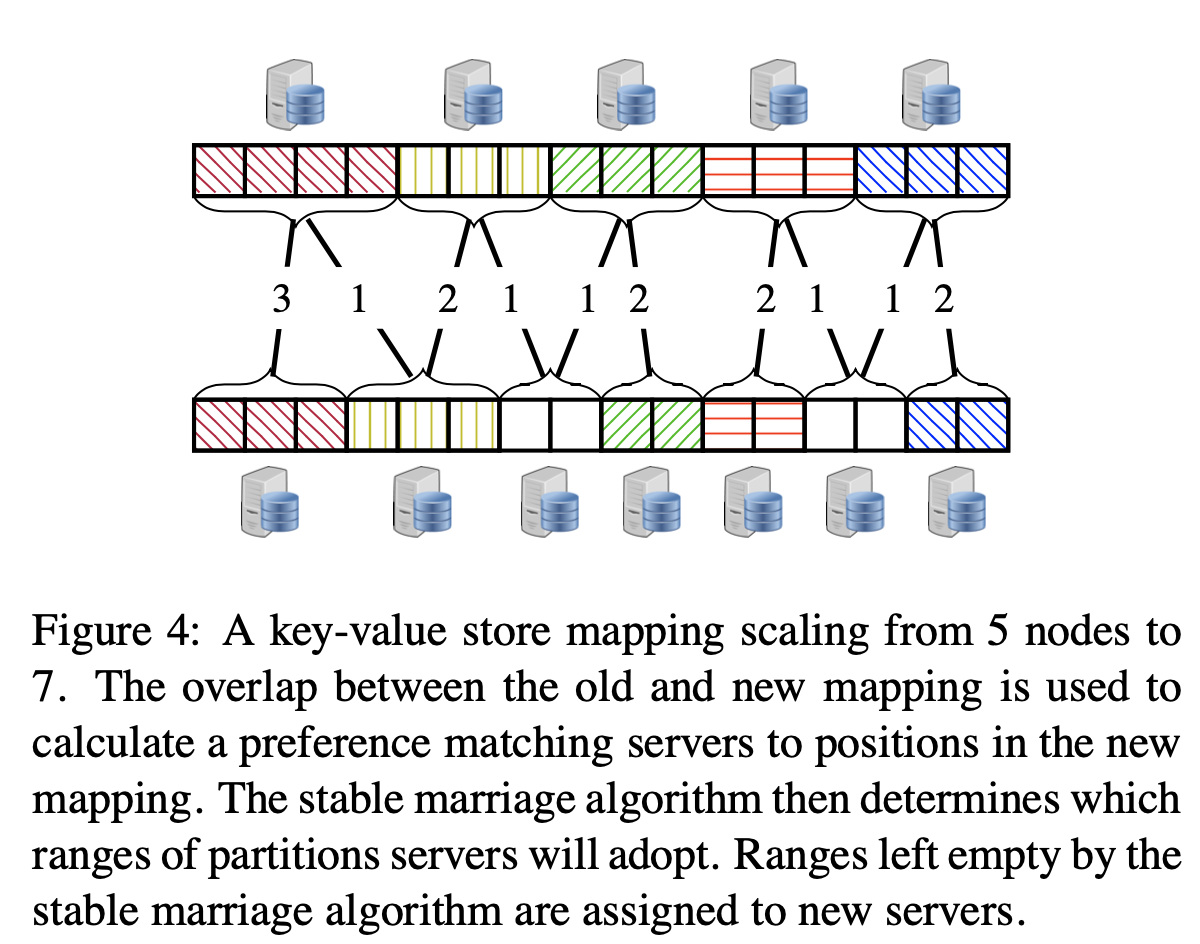
Before I finish, I want to mention that I liked the application of the stable marriage solution to reconfiguration.
Links
I used figures from the paper and this StrangeLoop 17 presentation.
Robert has two blog posts on Consus on his blog
I also liked this post in his blog. It comes with a github repo. Paxos in Proof-of-Concept DB






Comments