An Empirical Evaluation of In-Memory MultiVersion Concurrency Control
This is a closely related paper to the "Evaluation of Distributed Concurrency Control" paper we just covered. This paper is also from VDLB'17, and also has Andy Pavlo as an author. This time we zoom-in on the multiversion concurrency control protocols, and investigate their performances
on a single node database management system (DBMS) with in-memory multicore execution.
(It is worth reminding that Andy's database courses, both the intro and advanced courses, are on YouTube and are worth checking to refresh your database knowledge.)
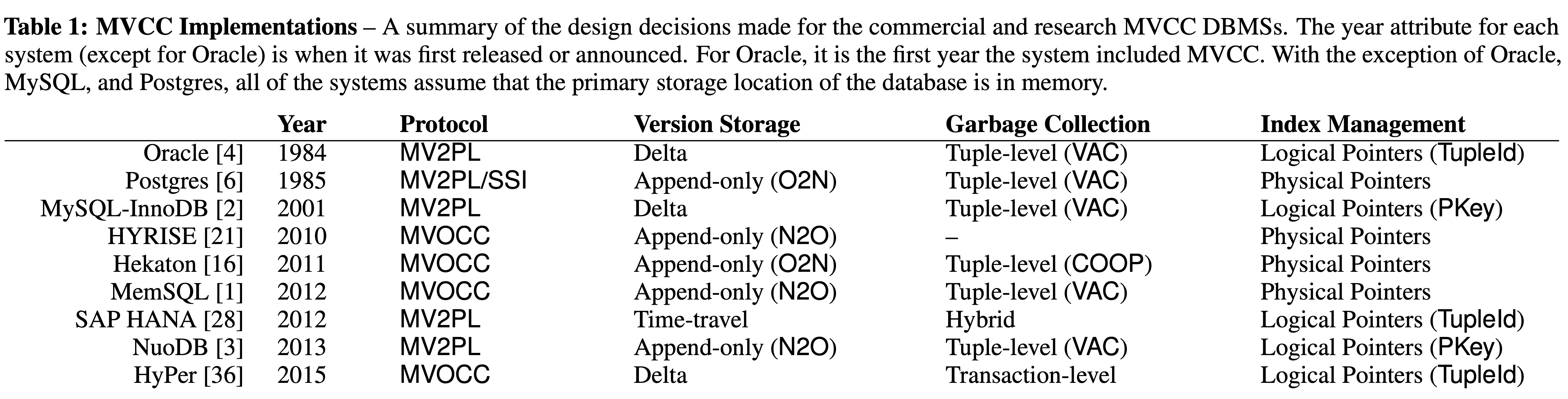
Although multiversion concurrency control (MVCC) is an old idea (going back to 1970s), it is used today by almost every major relational DBMS as shown in Table1. In a single-version system transactions always overwrite a tuple with new information whenever they update it. In contrast, multiversioning allows read-only transactions to access older versions of tuples without preventing read-write transactions from generating newer versions concurrently. This increases parallelism, but scaling MVCC in a multicore and in-memory setting is hard: when many threads run in parallel, their synchronization overhead can outweigh the benefits of multiversioning.
To determine these tradeoffs, this paper investigates four key transaction management design decisions in modern MVCC DBMSs: (1) concurrency control protocol, (2) version storage, (3) garbage collection, and (4) index management. To investigate the effects of these design decisions on the performance, they implemented these in the Peloton in-memory MVCC DBMS. They deployed Peloton on a single machine with 40 cores and evaluate it using two OLTP benchmarks (YCSB and TPC-C).
Important Findings
I will start with the spoilers so you can stop reading if you are in a hurry. The remaining sections will talk about the setup and experiments that enabled the team to draw these conclusions.
They find that the version storage scheme is one of the most important components to scaling an in-memory MVCC DBMS in a multicore environment. This goes against the conventional wisdom in database research that has mostly focused on optimizing the concurrency control protocols. They observed that the performance of append-only and time-travel schemes are influenced by the efficiency of the underlying memory allocation schemes; aggressively partitioning memory spaces per core resolves this problem. Delta storage scheme is able to sustain a comparatively high performance regardless of the memory allocation, especially when only a subset of the attributes stored in the table is modified. But this scheme suffers from low table scan performance, and may not be a good fit for read-heavy analytical workloads.
They also showed that using a workload-appropriate concurrency control protocol improves the performance, particularly on high-contention workloads. They found that multiversion timestamp ordering (MVTO) works well on a variety of workloads. Interestingly, none of the systems listed in Table 1 adopts this protocol.
To verify these findings, they configured Peloton to use the MVCC configurations listed in Table 1 to approximate those DBMSs. They executed the TPC-C workload using one thread to repeatedly execute the StockScan query and measured the DBMS's throughput and the average latency of StockScan queries.

As shown in Fig. 24, the DBMS performs the best on both the low-contention and high-contention workloads with the Oracle/MySQL and NuoDB configurations. This is because these systems' storage schemes scale well in multicore and in-memory systems, and their MV2PL protocol provides comparatively higher performance regardless of the workload contention. HYRISE, MemSQL, and HyPer's configurations yield relatively lower performance, as the use of MVOCC protocol can bring high overhead due to the read-set traversal required by the validation phase. Postgres and Hekaton's configurations lead to the worst performance, and the major reason is that the use of append-only storage with oldest-to-newest (O2N) version ordering severely restricts the scalability of the system. This experiment demonstrates that both concurrency control protocol and version storage scheme can have a strong impact on the throughput. But the latency results in Fig. 25 show that the DBMS's performance is the worst with delta storage. This is because the delta storage has to spend more time on traversing version chains so as to find the targeted tuple version attribute.
Ok, we can continue with the rest of the paper now.
Concurrency control protocols
The paper only considers serializable transaction execution. They consider four core concurrency control protocols.

The multiversion optimistic concurrency control (MVOCC) protocol splits a transaction into read, validate, commit phases. Before committing, the DBMS validates the transaction against all the transactions that committed since the transaction started or are currently in the validation phase. T is allowed to update version Ax if its write lock is not acquired. In a multiversion setting, if the transaction updates version Bx, then the DBMS creates version Bx+1 with its txn-id set to Tid.
The key design decision in two-phase locking (MV2PL) protocols is in how they handle deadlocks. Previous research has shown that the no-wait policy is the most scalable deadlock prevention technique. With this, the DBMS immediately aborts a transaction if it is unable to acquire a lock on a tuple (as opposed to waiting to see whether the lock is released). Since transactions never wait, the DBMS does not have to employ a background thread to detect and break deadlocks.
In the serialization certifier protocol, the DBMS maintains a serialization graph for detecting and removing "dangerous structures" formed by concurrent transactions. The serial safety net (SSN) certifier protocol encodes the transaction dependency information into metadata fields and validates a transaction T's consistency by computing a low watermark that summarizes "dangerous" transactions that committed before the T but must be serialized after T. Reducing the number of false aborts makes SSN more amenable to workloads with read-only or read-mostly transactions.

These protocols handle conflicts differently, and thus are better for some workloads more than others. MV2PL records reads with its read lock for each version. Hence, a transaction performing a read/write on a tuple version will cause another transaction to abort if it attempts to do the same thing on that version. MVTO instead uses the read-ts field to record reads on each version. MVOCC does not update any fields on a tuple's version header during read/operations. This avoids unnecessary coordination between threads, and a transaction reading one version will not lead to an abort other transactions that update the same version. But MVOCC requires the DBMS to examine a transaction's read set to validate the correctness of that transaction's read operations. This can cause starvation of long-running read-only transactions. Certifier protocols reduce aborts because they do not validate reads, but their anti-dependency checking scheme may bring additional overheads.
Version storage
Under MVCC, the DBMS constructs a new physical version of a tuple when a transaction updates it. The DBMS uses the tuples' pointer field to create a latch-free (database speak for lock-free) linked list called a version chain. This version chain allows the DBMS to locate the desired version of a tuple that is visible to a transaction.
In the append-only storage scheme, all of the tuple versions for a table are stored in the same storage space. This approach is used in Postgres, as well as in-memory DBMSs like Hekaton, NuoDB, and MemSQL. To update an existing tuple, the DBMS first acquires an empty slot from the table for the new tuple version. It then copies the content of the current version to the new version. Finally, it applies the modifications to the tuple in the newly allocated version slot. The key decision with the append-only scheme is how the DBMS orders the tuples' version chains and this gives rise to the Oldest-to-Newest (O2N) and Newest-to-Oldest (N2O) flavors.
The time-travel storage scheme is similar to the append-only approach except that the older versions are stored in a separate table. The DBMS maintains a master version of each tuple in the main table and multiple versions of the same tuple in a separate time-travel table. In some DBMSs, like SQL Server, the master version is the current version of the tuple. Other systems, like SAP HANA, store the oldest version of a tuple as the master version to provide snapshot isolation. This incurs additional maintenance costs during garbage collection because the DBMS copies the data from the time-travel table back to the main table when it prunes the current master version. The evaluations implement the first approach.
In the delta storage scheme, the DBMS maintains the master versions of tuples in the main table and a sequence of delta versions in a separate delta storage. This storage is referred to as the rollback segment in MySQL and Oracle, and is also used in HyPer. Most existing DBMSs store the current version of a tuple in the main table. To update an existing tuple, the DBMS acquires a continuous space from the delta storage for creating a new delta version. This delta version contains the original values of modified attributes rather than the entire tuple. The DBMS then directly performs in-place update to the master version in the main table.

Garbage Collection
Since MVCC creates new versions when transactions update tuples, the system will run out of space unless it reclaims the versions that are no longer needed. This also increases the execution time of queries because the DBMS spends more time traversing long version chains. Thus, the performance of a MVCC DBMS is highly dependent on the ability of its garbage collection (GC) component to reclaim memory in a transactionally safe manner.
In the tuple-level garbage collection approach, the DBMS checks the visibility of each individual tuple version in one of two ways: Background Vacuuming (VAC) or Cooperative Cleaning (COOP). In the transaction-level garbage collection approach, the DBMS reclaims storage space at transaction-level granularity. Tuple-level GC with background vacuuming is the most common implementation in MVCC DBMSs.

Index management
All MVCC DBMSs keep the database's versioning information separate from its indexes. That is, the existence of a key in an index means that some version exists with that key but the index entry does not contain information about which versions of the tuple match. The index entry is a key/value pair, where the key is a tuple's indexed attribute(s) and the value is a pointer to that tuple. The DBMS follows this pointer to a tuple's version chain and then scans the chain to locate the version that is visible for a transaction.
Primary key indexes always point to the current version of a tuple. But how often the DBMS updates a primary key index depends on whether or not its version storage scheme creates new versions when a tuple is updated. For example, a primary key index in the delta scheme always points to the master version for a tuple in the main table, thus the index does not need to be updated. For append-only, it depends on the version chain ordering: N2O requires the DBMS to update the primary key index every time a new version is created. If a tuple’s primary key is modified, then the DBMS applies this to the index as a DELETE followed by an INSERT.
For secondary indexes, it is more complicated because an index entry's keys and pointers can both change. The two management schemes for secondary indexes in a MVCC DBMS differ on the contents of these pointers. The first approach uses logical pointers that use indirection to map to the location of the physical version. In the physical pointers approach the value is maintained to be the location of an exact version of the tuple.

Like the other design decisions, these index management schemes perform differently on varying workloads. The logical pointer approach is better for write-intensive workloads, as the DBMS updates the secondary indexes only when a transaction modifies the indexes attributes. Reads are potentially slower, however, because the DBMS traverses version chains and perform additional key comparisons. Likewise, using physical pointers is better for read-intensive workloads because an index entry points to the exact version. But it is slower for update operations because this scheme requires the DBMS to insert an entry into every secondary index for each new version, which makes update operations slower.
Evaluation
The paper implements the protocols introduced above in the Peloton DBMS. Peloton stores tuples in row-oriented, unordered in-memory heaps. It uses libcuckoo hash tables for its internal data structures and the Bw-Tree for database indexes. Peloton's performance is optimized by leveraging latch-free programming techniques. They execute all transactions as stored procedures under the SERIALIZABLE isolation level.
YCSB benchmark is used for most experiments, TPC-C benchmark is used at the end to examine how each protocol behaves under real-world workloads. The evaluation begins with a comparison of the concurrency control protocols. They then pick the best overall protocol and use it to evaluate the version storage, garbage collection, and index management schemes.
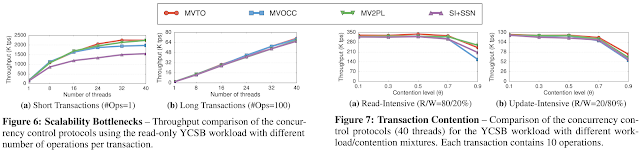

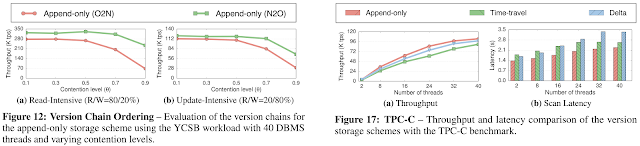

Questions
The single node multi-core DBMS performance is important, and this paper explains the tradeoffs involved there. How do we expect these to interplay in a distributed DBMS deployment? Would multi-node coordination overhead dominate and make these insignificant? Would the best configuration for single-node multicore also be the best configuration in a distributed DBMS setup? Are there any connections/extrapolations we can make from this to Andy's NewSQL survey paper?





Comments