Amazon Aurora: Design Considerations + On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
Amazon Aurora is a high-throughput cloud-native relational database. I will summarize its design as covered by the Sigmod 17 and Sigmod 18 papers from the Aurora team. Aurora uses MySQL or PostgreSQL for the database instance at top, and decouples the storage to a multi-tenant scale-out storage service. In this decoupled architecture, each database instance acts as a SQL endpoint and supports query processing, access methods, transactions, locking, buffer caching, and undo management. Some database functions, including redo logging, materialization of data blocks, garbage collection, and backup/restore, are offloaded to the storage nodes.
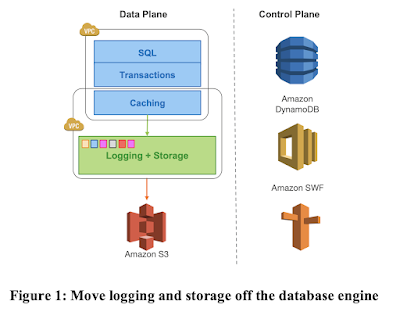
A big innovation in Aurora is to do the replication among the storage
nodes by pushing the redo log; this reduces networking traffic and
enables fault-tolerant storage that heals without database involvement.

Aurora supports "AZ+1" failures (AZ means availability zone). It maintains 6 copies of data, spread across 3 AZs, such that there are 2 replicas per AZ, a 4/6 forms a write quorum, and a 3/6 forms a read/recovery quorum.

Aurora also tackles the double fault problem and tries to keep a write quorum going and not losing availability in the presence of two uncorrelated faults in a small period after an AZ unavailability. It is difficult, past a point, to reduce the probability of MTTF (mean time to failure) on independent failures. They instead focus on reducing MTTR (mean time to repair), to shrink the window of vulnerability to a double fault. They do so by partitioning the database volume into small fixed size segments, 10GB in size. It is faster to recover small size segments than big size segments. Each segment is called a protection group and, as mentioned above, is spread across 3 AZs, with 2 replicas per AZ.
Redo log deep dive
While the redo log is segmented across 10GB and spread across storage nodes, the Log Sequence Number (LSN) space is common across the database volume. The LSN is monotonically increasing, and is allocated by the database instance (i.e., the primary instance).

For example, Figure 3 shows a database with two protection groups, PG1 and PG2, consisting of segments A1-F1 and A2-F2 respectively. In the figure, each solid cell represents a log record acknowledged by a segment, with the odd numbered log records going to PG1 and the even numbered log records going to PG2. Here, PG1's PGCL is 103 because 105 has not met quorum, PG2's PGCL is 104 because 106 has not met quorum, and the database's VCL is 104 which is the highest point at which all previous log records have met quorum.

No consensus is required to advance SCL, PGCL, or VCL: all that is required is bookkeeping by each individual storage node and local ephemeral state on the database instance based on the communication between the database and storage nodes. Since Aurora uses a single writer (i.e., the primary instance), accept versus commit separation in Paxos is not needed in Aurora. In Aurora, everything received at a replica node is labeled as an immediate commit. If needed, the primary instance fail-overs, and leveraging the quorum, the epoch number is increased and recovery is performed, and the new primary keeps advancing the log. We discuss how that works next.
Crash recovery
The time saved in the normal forward processing of commits using local transient state must be paid back by additional work done for re-establishing consistency upon crash recovery. This is a trade worth making since commits are many orders of magnitude more common than crashes.
When opening a database volume, either for crash recovery or for a normal startup, the database instance must be able to reach at least a read quorum for each protection group comprising the volume. The database instance can then locally re-compute PGCLs and VCL for the database by finding read quorum consistency points across SCLs.

Making reads efficient
Aurora uses read views to support snapshot isolation using Multi-Version Concurrency Control (MVCC). A read view establishes a logical point in time before which a SQL statement must see all changes and after which it may not see any changes other than its own.
Aurora does not do quorum reads. Through its bookkeeping of writes and consistency points, the database instance knows which segments have the last durable version of a data block and can request it directly from any of those segments. Aurora MySQL does this by establishing the most recent SCN and a list of transactions active as of that LSN. Reads are one of the few operations in Aurora where threads have to wait. Unlike writes (which can stream asynchronously to storage nodes) or commits (where a worker can move on to other work while waiting for storage to acknowledge), a thread needing a block not in cache typically must wait for the read I/O to complete before it can progress.
Internally, within an Aurora cluster, physical replication is used (as it is faster and more efficient than logical replication). Aurora read replicas attach to the same storage volume as the writer instance. They receive a physical redo log stream from the writer instance and use this to update only data blocks present in their local caches. Redo records for uncached blocks can be discarded, as they can be read from the shared storage volume. Decoupling database from the storage allows Aurora to horizontally scale read instances.
Aurora uses three invariants to manage structural consistency of the replicas. First, replica read views must lag durability consistency points at the writer instance. This ensures that the writer and reader need not coordinate cache eviction. Second, structural changes to the database, for example B-Tree splits and merges, must be made visible to the replica atomically. This ensures consistency during block traversals. Third, read views on replicas must be anchorable to equivalent points in time on the writer instance. This ensures that snapshot isolation is preserved across the system.
Failures and quorum membership
Quorum membership is also managed leveraging the quorum itself using epoch numbers. Membership epochs enable updating membership without complex consensus, fence out others without waiting for lease expiry, and operate using the same failure tolerance as quorum reads and writes themselves. Clients with stale membership epochs have their requests rejected and must update membership information.

Let us now consider what happens if E also fails while we are replacing F with G, and we wish to replace it with H. In this case, we would move from a write quorum set of ((4/6 of ABCDEF AND 4/6 of ABCDEG) AND (4/6 of ABCDFH AND 4/6 of ABCDGH)). As with a single failure, I/Os can proceed, the operation is reversible, and the membership change can occur with an epoch increment.
This simple quorum membership scheme is used for handling unexpected failures, heat management, as well as planned software upgrades.
Using Quorum Sets to Reduce Costs
In Aurora, a protection group is composed of three full segments, which store both redo log records and materialized data blocks, and three tail segments, which contain redo log records alone. Since most databases use much more space for data blocks than for redo logs, this yields a cost amplification closer to 3 copies of the data rather than a full 6 while satisfying the requirement to support AZ+1 failures.
The use of full and tail segments changes the construction of read and write sets. The write quorum is 4/6 of any segment OR 3/3 of full segments. The read quorum is therefore 3/6 of any segment AND 1/3 of full segments. In practice, this means that Aurora writes log records to the same 4/6 quorum. At least one of these log records arrives at a full segment and generates a data block. Data is read from a full segment, using the optimization described earlier to avoid quorum reads.






Comments
So this is something I've always wondered about in Aurora, and never fully understood: if they're not doing consensus for commits or reads etc... what happens when consensus *isn't* satisfied? Surely one of the three consensus properties must (sometimes) fail to hold: safety, liveness, and nontriviality. It sounds like liveness and nontriviality *are* preserved, so... does that leave Aurora violating consensus safety? If so, then somewhere there's got to be learners--perhaps clients, perhaps storage nodes, depending on where you want to draw the boundaries--which *disagree* on the contents or order of transactions. Does this manifest as user-observable consistency violations? If not, why?