Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3 (SOSP21)
This paper comes from my colleagues at AWS S3 Automated Reasoning Group, detailing their experience applying lightweight formal methods to a new class of storage node developed for S3 storage backend. Lightweight formal methods emphasize automation and usability. In this case, the approach involves three prongs:
- developing executable reference models as specifications,
- checking implementation conformance to those models, and
- building infrastructure to ensure the models remain accurate in the future.
ShardStore
ShardStore is a new append-only key-value storage node developed for AWS S3 backend. It is over 40K lines of Rust code. Shardstore is a log-structured merge tree (LSM tree) but with shard data stored outside the tree to reduce write amplification.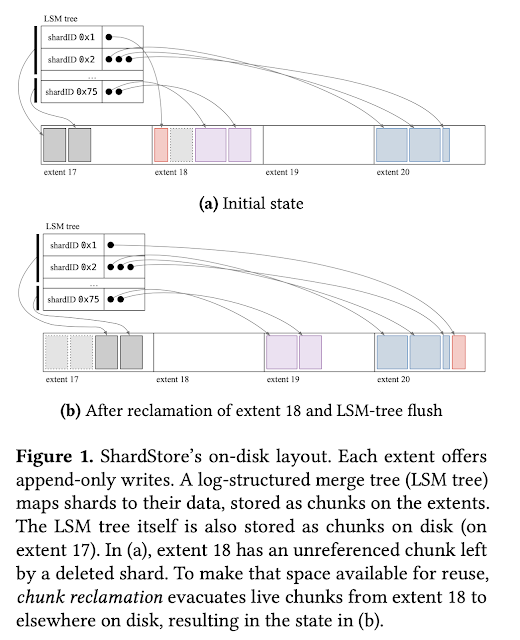
ShardStore employs soft updates for avoiding the cost of redirecting writes through a write-ahead log while still being crash consistent. A soft updates implementation ensures that only writes whose dependencies are persisted are sent to disk so that any crash state of the disk is consistent.

Crash consistency is important for Shardstore, not due to durability issues ---there are already multiple replicas for ensuring eleven 9s durability. Instead crash consistency is important for reducing the cost and operational impact of node failures. A crash that loses an entire storage host's data creates lots of repair network traffic and IO load on potentially dozens of other storage nodes. Crash consistency also ensures that the storage node recovers to a safe state after a crash so it becomes easier, faster, cheaper for it to get back online.
Validating ShardStore
For each ShardStore component, the team developed a reference model --an executable specification in Rust that implements the same interface as the actual component, but using a much simpler implementation. For instance, for the Index component that maps shard identifiers to chunk locators, the ReferenceIndex uses a simple hash table to store the mapping, rather than the persistent LSM-tree implementation.
Unit tests at ShardStore's API layer use ReferenceIndex as a mock implementation of the Index component, rather than instantiating the real implementation. This increases the likelihood that the models will remain accurate, as writing regular unit tests for new functionality added to the system often requires updating the mock. The team found that by writing reference models in the same language as the implementation, it became easier for the engineers to keep the models up to date.
For validating ShardStore, the team decomposed the durability property into three parts, and reasoned about each separately.
- For sequential crash-free executions, conformance to the reference model is checked directly under property-based testing.
- For sequential crashing executions, the reference model is refined to establish which data can be lost after a crash, and that is used for checking the conformance of the implementation under property-based testing (proptesting).
- For concurrent crash-free executions, separate reference models are written and checked under model-checking.
Checking properties of concurrent crashing executions using an automated approach is left as future work.
Conformance checking of crash-free sequential executions
Property-based testing is used for checking that the implementation code refines the reference model. Proptesting can be thought of as an extension of fuzzing with user-provided correctness properties and structured inputs, which allow it to check richer behaviors than fuzzing alone.
The property-based tests are designed to take as input a sequence of operations drawn from an alphabet the team defined. For each operation in the sequence, the test case applies the operation to both reference model and implementation, compares the output of each for equivalence, and then checks invariants that relate the two systems.
The team applied techniques like failure injection and biasing arguments towards potentially problematic corner cases to improve the state coverage of random property-based testing and therefore increase the likelihood of detecting issues.
Checking Crash Consistency
Two crash consistency properties were defined in terms of the user-space dependencies and checked for conformance under property-testing:
- persistence: if a dependency says an operation has persisted before a crash, it should be readable after a crash (or if multiple operations have persisted, the most recent one to persist should be readable)
- forward progress: after a non-crashing shutdown, the dependency for every write should indicate it is persistent
It was very surprising to see that this was able to catch a very subtle bug (issue #10 in Figure 5) in an automated fashion. This was a bug that involved a particular choice of random UUID to collide with the magic bytes, a chunk that was the right size to just barely spill onto a second page, and a crash that lost only the second page
Checking concurrent executions
Since standard proptesting is not suitable for exploring concurrent executions, to check concurrent properties, the team wrote harnesses for key properties and validated them using stateless model checking, which explored all concurrent interleavings of a program. They use Loom to soundly check all interleavings of small, correctness-critical code (e.g., custom concurrency primitives such as sharded reader-writer locks), and Shuttle to randomly check interleavings of larger test harnesses that Loom cannot scale to (e.g., end-to-end stress tests of the entire ShardStore stack).
Experience

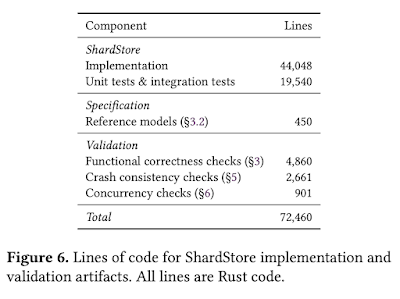
Continuous validation was a priority for the project. The system evolved over time, and is expected to evolve further. It was important for the automated reasoning to support this and provide continuous validation, being maintained alongside code by the developers who wrote the code.
We focused heavily on lowering the marginal cost of future validation: we would not have considered this work successful if future code changes by engineers required kicking off new formal methods engagements. Early in our work, we wrote reference models using modeling languages we were familiar with (Alloy, SPIN, and Yggdrasil-style Python) and imagined developing tooling to check the Rust code against them. It was only when we discussed long-term maintenance implications with the team that we realized writing the models themselves in Rust was a much better choice, and even later when we realized the reference models could serve double duty as mocks for unit testing.





Comments