Sundial: Fault-tolerant Clock Synchronization for Datacenters
This paper appeared recently in OSDI 2020. This paper is about clock synchronization in the data center. I presented this paper for our distributed systems zoom meeting group. I took a wider view of the problem by explaining time synchronization challenges and fundamental techniques to achieve precise time synchronization. I will take the same path in this post as well. It is a bit circuitous road, but it gives a scenic pleasurable journey. So let's get going.
The benefits of better time synchronization
For any distributed system, timestamping and ordering of events is a very important thing. Processes in a distributed system run concurrently without knowing what the other processes are doing at the moment. Processes learn about each other's states only by sending and receiving messages and this information by definition come from the past state of the nodes. The process needs to compose the coherent view of the system from these messages and all the while the system is moving along advancing and changing state. This is like trying to compose a panaromic snapshot of a parade moving down the street only by using small 4x6 photos shot by the participants at arbitrary times. This would be impossible without good timestamping and a way to order these events with respect to each other. Thus, timestamping and ordering of events is very important for processes to compose coherent snapshots and to build a foundation for distributed coordination. Of course logical clocks and vector clocks help for this by capturing causality through communication of the nodes. But if you have good time synchronization of the physical clocks at the nodes, you can avoid a lot of headache for timestamping and ordering of events in distributed systems, and achieve finer granularity ordering without relying on communication.
The most important quality metric for time synchronization is epsilon, $\epsilon$, the length of the clock uncertainty. (The sundial paper is entirely about making this epsilon as small as possible, even against the face of failures.) Why is epsilon so important? It is because, if we have a large epsilon we may order the events incorrectly. Consider this example. Event A and event B has the same clock timestamp but they are farther apart in time because of the epsilon uncertainty. Even though A and B should give us a snapshot of the distributed system, this is an inconsistent snapshot. Another event happens after A which then sends a message that affects B, and taints the snapshot. Causality sneaks in between A and B and the integrity of the snapshot is violated. Inconsistent snapshots are dangerous. They are like panorama pictures gone wrong, or like crossing of beams in ghostbusters.
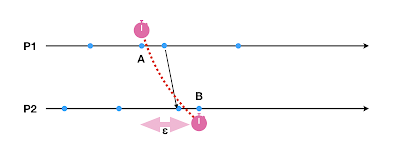
So how can we take a consistent snapshot with epsilon uncertainty bound. Simple we make the node wait out the epsilon duration before allowing another significant event. If after timestamping event A, we waited for epsilon uncertainty bound to expire on that process, the message sent would not happen, and the integrity of the snapshot would have been preserved. Really, wait it out? This doesn't sound like much of an efficient solution. Exactly! That is why it is important to keep epsilon small. So this is an important problem, and this paper gives a really low upperbound for epsilon 100nanoseconds by putting in a rigorous engineering effort.
(Precise time synchronization can help for more. I was toying with the idea of timely algorithms and silent consent protocols, but that is discussion for another time.)
Time synchronization in wireless sensor networks
So here comes our detour!
As I was reading the Sundial paper, my reaction was: "We did this! We did this for wireless sensor networks 20 years ago!" In 2001, I was a PhD student at The Ohio State University. We had gotten funding from DARPA. U.C Berkeley was spearheading the effort, they had made these tiny sensor nodes with 4Mhz CPU and 8K RAM (to suffice as both OS and application memory). Each of these nodes has radios that can wirelessly broadcast to any sensor within 10 yards and these talk to each other form an ad hoc network and try to monitor if there is an intruder crossing the network and classify this intruder as a soldier, car, or tank based on detections fired by the sensors. Time synchronization was crucial for this monitoring because we were timestamping detection events at the nodes, and exfiltrating them to a basestation where we take snapshots counting the number of simultaneous detections. Based on how many sensors detected an event, we would classify it as a soldier, car, tank.
Later, using time synchronization, Vanderbilt University did the demo of shooter localization with sensor networks. They used real rifles to shut at a target, and the sensor nodes had microsecond-level synchronization that when they heard the bullet shockwave they took timestamp and send it to the base station. Using these timestamps, the basestation could determine that the shot was coming this way and could pinpoint the shooter.
We were able to get clock synchronization with epsilon of 5 microsecond using these wimpy nodes (8K RAM and 4Mhz CPU), whereas the Google Spanner paper that came in 2012 was able to provide a timesynchronization epsilon of 6 milliseconds.
How? Read on to see how.
Quartz clocks need frequent synchronizing
Each wireless sensor node had a clock. A clock is just a crystal/quartz oscillator. A circuit counts the number of times a crystal oscillates and declares that a millisecond has passed because it counted say 1000 oscillations. This is not precise of course. Atomic clocks use rubidium, which has an oscillation/clock error of one microsecond a day. But quartz is not like that. It is inaccurate and drifts too much. No two quartz crystals are identical. They have big variations. They are dirt cheap though, that is why they are very popular. Another thing about quartz crystal is they are very temperature sensitive: when the temperature gets colder they oscillate more when it gets hotter they oscillate less.
This is why frequent time synchronization is needed when using crystal oscillator based clocks. Otherwise each node's clock would drift apart from each other.
Error sources for time synchronization
When you try to synchronize two nodes over messaging there are many places where errors will be incurred: packing up the message for transmission, waiting for the MAC layer to find a suitable transmission time, sending the message, the actual message propagation, and on the receiver side receiving the message and unpacking. In WSNs, the propagation of message is light speed, because it is done over radio. But the MAC layer wait, and actual byte-by-byte coding of the message on air at the radio is slow. The important point here is to eliminate the nondeterministic error sources so they don't mess up with the latency in a nondeterministic way, and subtract out the deterministic error durations to compensate for them.

A big source of non-deterministic error in wireless sensor networks come from the MAC layer availability waiting for the channel to go idle so we can transmit. We used MAC layer timestamping to eliminate this problem. When we are sending a synchronization message, we don't put the timestamp in the package in application layer, we put a placeholder in, instead we take the timestamp and insert it in the message buffer later, when the transmission actually started to happen byte-by-byte over the radio, and it is timestamp-bytes turn to be sent.
Lesson 1. Insert the synchronization timestamp during the transmission below the MAC layer.
In WSNs, we had the advantage that messaging is point to point between any two nodes without involving any switch or a router. In wired networks, going through a switch and router adds a lot of hard to control/detect nondeterministic delay, which messes up synchronization.
Lesson 2. Use point-to-point messaging for synchronization, you can't do end to end synchronization with precision.
Reference point for synchronization
"A man with a watch knows what time it is. A man with two watches is never sure." -Segal's law
For pairwise synchronization, we use link-level point-to-point communication. But how do we synchronize a network of nodes, over multihops? We do this by overlaying a single root spanning tree. Using a single root keeps the epsilon to minimum. We don't care being that much fidelity to real-time, but we want the nodes clocks to be very close to each other with low epsilon.
Why do we synchronize to one node wouldn't it make more sense to maybe take average of clocks from nodes to reduce errors each one might have to real time? When the goal is to get the epsilon small, it is better to lock onto one node (have one master) and make every node in order not to create confusion make every node walk with the pace of that node. Trying to adjust to the clock rate of multiple nodes can't get you to very precise synchronization. Maybe more accurate time synchronization with respect to true time, but not more precise synchronization with very low epsilon. (In WSNs case for most applications we didn't even use a real time as clock source/reference anyways, and only cared for synchronizing the clocks of with respect to each other.)
Lesson 3. Use a spanning tree to synchronize the nodes with respect to a single root as reference.
Ok, what if the single root dies? Another root can emerge, and a new spanning tree can form for that root. But this can take a long time. It is better if you can do this pre-arranged. As part of our big deployments (100 nodes and 1000 nodes), we used a grid topology, and we hardcoded backup parents for each node, as well as a backup root. When you impose a regular grid topology, backup route calculation becomes simple, local, and fast.
Lesson 4. Make backup route calculation local and fast.
Wired network time synchronization
After working on wireless sensor network work, when switching back to mainstream distributed systems work in datacenter computing, I was like come on NTP, really, epsilon of 50 milliseconds? That is 10 000 times bigger epsilon than the 5 microsecond epsilon we could get from the wimpy sensor nodes. What gives?
Computers use the same shitty quartz clocks as WSN nodes, but you know that is not an excuse. You should know by now how to ask the important question. Where does the non-deterministic errors come in for synchronization? It comes from the network. The switches and routers are the source of nondeterministic errors for NTP.
NTP does not use any of the four lessons for precise time synchronization we mentioned above. The goal in NTP was to have a general, easy to deploy, broad and rough synchronization.
When the Spanner paper came in 2012, even with atomic clocks as synchronization source, it was able to give an epsilon of 6 milliseconds. That's still huge. That is a lot of epsilon to wait to make sure consistency of timestamp ordering. (To spanner's credit, during this 6ms there is last step of 2phase commit also going in parallel. So it is not a full 6ms wait. You wait the time for the RTT is completed to 6ms.) Again they didn't want to mess with the lower layers of the network, and do link layer point-to-point synchronization. They just used the advantage of better more reliable datacenter networking links.
With the goal of improving precision, PTP improves things significantly by doing synchronization point-to-point at link layer. I wrote about wired network time synchronization overview and NTP and PTP before.
Sundial paper
OK, the detour is complete. Back to the Sundial paper.
Sundial uses all the 4 lessons we mentioned above for precise clock synchronization in wireless sensor networks.
Sundial does timestamping and synchronization at L2 data link level in a point-to-point manner. Sundial uses hardware the network interface cads (nic) to do timestamping and synchronization. They don't go into any details here, saying this is proprietary. But this is likely the most important part of Sundial. Doing synchronization at the hardware enables to them to do very frequent synchronization to compensate for the uncontrollable clock drifts of quartz clocks. They send a synchronization signal every 500 microseconds to reduce clock drift of quartz clocks and to keep epsilon very small. Performing synchronization this frequently would not work over software. (In WSNs we didn't have this luxury.)
Sundial uses a spanning tree as the multihop synchronization structure and synchronizes the nodes with respect to a single root. Sundial uses predetermined backup parents to default to, so it can recover fast from link and root failures.
You can now follow the paper easily by watching its presentation and checking out its slides.
Sundial is able to get epsilon less than 100 nanoseconds; that is very precise! In addition to the four lessons above, two factors contribute to this. They can perform very frequent synchronization doing synchronization at the hardware/NICs. Secondly, they are very diligent about dealing with effects of faults. The datacenter networking having a lot of bandwidth, being fast, and in their control helps a lot as well.
In calm water, every ship has a good captain. Rough waters are truer tests of leadership. -- Swedish proverb
The Sundial paper puts a lot of focus on fault-tolerance and the worse case epsilon to the face of faults. It would be easy to give precise clock synchronization with PTP if it were not for faults. Most of the discussion in the paper is about how to tolerate link failures, node failure, root failure, and even domain (a set of nodes) failure, and still give less than 100 nanosecond epsilon bound to the face of them.

In Sundial backup routes are precalculated for each node. There are some constraints here to make the backup routes loop-free, and to tolerate failure of a domain failure, but this is done centrally at a controller node, so it is not a big deal. There will be enough time to recalculate this between two faults/topology changes to keep the topology rejuvenated.
At runtime, if your parent or link to parent died, you'll switch to backup parent. To keep the epsilon low, and to prevent incurring of drifts at the subtree of this node, it is also important for the subtree of this node to quickly timeout and switch to backup routes. For this they use synchronized messages: I won't send you a message if i don't receive a message from my parent. This way entire subtree time outs shortly and every node would be able to detect the problem and take local action to switch to the backup routes.
What if the root dies? Easy, we have a backup root. But now we also have a problem: what if the backup root thinks the root died but the root did not die? To avoid this disagreement, the backup root needs a witness from another subtree of the root to confirm its suspicion. If the backup root doesn't get signal from the root it could be either the root is dead or this link is bad. If the backup root still gets a signal from the witness that means the root is alive (the witness sends a message only because it is still getting messages from root, because its parent is getting messages, etc., remember synchronized messages). But if the backup node does not get a signal from the witness either, it can be certain the root is dead and takes over as a root.

Related work

Huygens work is worth mentioning here . While it doesn't use hardware support for time synchronization, Huygens is able to get nanosecond level time synchronization by leveraging three key ideas. "First, coded probes identify and reject impure probe data (data captured by probes which suffer queuing delays, random jitter, and NIC timestamp noise). Next, HUYGENS processes the purified data with Support Vector Machines, a widely-used and powerful classifier, to accurately estimate one-way propagation times and achieve clock synchronization to within 100 nanoseconds. Finally, HUYGENS exploits a natural network effect (the idea that a group of pair-wise synchronized clocks must be transitively synchronized) to detect and correct synchronization errors even further."
Huygens uses the spacing between the probes to detect a problem. When probes go through a router if they got into contention the spacing between them would change and the receiver side can look at this tainted spacing, and decide not to use this compromised transmission for time synchronization.





Comments