WormSpace: A modular foundation for simple, verifiable distributed systems
This paper is by Ji-Yong Shin, Jieung Kim, Wolf Honore, Hernán Vanzetto, Srihari Radhakrishnan, Mahesh Balakrishnan, Zhong Shao, and it appeared at SOCC'19.
The paper introduces the Write-Once Register (WOR) abstraction, and argues that the WOR should be a first-class system-building abstraction. By providing single-shot consensus via a simple data-centric API, the WOR acts as a building block for providing distributed systems durability, concurrency control, and failure atomicity.
Each WOR is implemented via a Paxos instance, and leveraging this, WormSpace (Write-Once-Read-Many Address Space) organizes the address space into contiguous write-once segments (WOSes) and provides developers with a shared address space of durable, highly available, and strongly consistent WORs to build on. For example, a sequence of WORs can be used to impose a total order, and a set of WORs can keep decisions taken by participants in distributed transaction protocols such as 2PC.
To demonstrate its utility, the paper implements three applications over WormSpace. These applications are built entirely over the WOR API, yet provide efficiency comparable to or better than handcrafted implementations.
If you like to see how extensions of some of these ideas can be put in action, watch this video by Mahesh Balakrishnan (one of the authors of WormSpace) and Jason Flinn (U Michigan) describe the Delos Storage system for Facebook's Control Plane.
The paper is well-written, and I really enjoyed reading this paper. I think this paper should receive more attention. The paper has another track, which I will not discuss here: Formal verification of WormSpace and reuse of this proof for verifying systems built on top, via the Certified Concurrent Abstraction Layer (CCAL) approach. Sometimes, when a paper includes many ideas, it may dilute the focus and hurt its reception/recognition.
In my summary below, I use many sentences from the paper verbatim. I am saving my MAD questions and in-depth review to the Zoom paper discussion on Wednesday 15:30 EST. Our Zoom Distributed Systems Reading Group meeting is open to anyone who is passionate about distributed systems. Here is an invitation to the Slack workspace for the reading group, where we will conduct pre-meeting discussion and announce the password-protected link to the meeting. (UPDATE: Here is the link to our WormSpace paper discussion.)
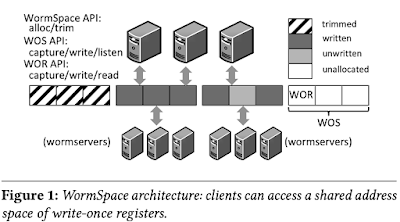
The address space is divided into write-once segments (WOSes) of fixed size. Segments are explicitly allocated via an alloc call that takes in a segment ID and succeeds if it is as yet unallocated. Once a client has allocated a WOS, any client in the system can operate on WORs within the segment. Specifically, it can capture a WOR; write to it; and read from it.
Clients must capture an address before writing to it to coordinate replicated servers to make the write atomic and immutable. The capture call is similar to a preemtable lock (e.g. phase1, prepare of Paxos): the lock must be acquired to write, but it can be stolen by others. A successful capture call returns a unique, non-zero captureID; a subsequent write by the same thread is automatically parameterized with this ID, and succeeds if the WOR has not been captured by some other client in the meantime.
The WormSpace design is similar to a write-once distributed key-value store: WORs are associated with 64-bit IDs (consisting of segment IDs concatenated with offsets within the segment) and mapped to partitions, which in turn consist of replica sets of wormservers. Partitioning occurs at WOS granularity; to perform an operation on a WOR within a WOS, the client determines the partition storing the segment (via a modulo function) and issues the operation to the replica set.
Each WOR is implemented via a single-shot Paxos consensus protocol, with the wormservers within a partition acting as a set of acceptors. In the context of a single WOR, the wormservers act identically to Paxos acceptors; a capture call translates to a phase 1a prepare message, whereas a write call is a phase 2a accept message. The read protocol mirrors a phase 1a message, but if it encounters a half-written quorum, it completes the write. Each wormserver maintains a map from WOR IDs to the acceptor state for that single-shot Paxos instance. If a map entry is not found, the WOR is treated as unwritten.

The client-side library layers the logic for enforcing write-once segments. Each WOS segment is implemented via a set of data WORs, a single metadata WOR, and a single trim WOR. Allocating the WOS requires writing to the metadata WOR. If two clients race to allocate a WOS, the first one to capture and write the WOR wins.

WormPaxos is an implementation of Multi-Paxos over WormSpace, exposing a conventional state machine replication (SMR) API to applications. Implementing Multi-Paxos over WormSpace is simple: the sequence of commands is stored on the WormSpace address space. In WormPaxos, servers that wish to replicate state act as WormSpace clients, and are called WP-servers. They can propose new commands by preparing and writing to the next free address; and learn commands by reading the address space in sequential order.
In WormPaxos, a WP-server becomes a sticky leader simply by using a batch capture on a WOS; accordingly, leadership strategies such as sticky leader, rotating leader, etc. can be implemented simply as policies on who should call the batch capture and when. The leader's identity can be stored within the metadata for each segment, obviating the need for WormSpace to know about the notion of a leader or the leadership strategies involved. If the leader crashes, a new leader that allocates the next WOS can batch capture the WOS of the previous leader, complete partially finished operations, and fill in junk values to unwritten WORs to prevent holes in the SMR/Multi-Paxos log.



The paper introduces the Write-Once Register (WOR) abstraction, and argues that the WOR should be a first-class system-building abstraction. By providing single-shot consensus via a simple data-centric API, the WOR acts as a building block for providing distributed systems durability, concurrency control, and failure atomicity.
Each WOR is implemented via a Paxos instance, and leveraging this, WormSpace (Write-Once-Read-Many Address Space) organizes the address space into contiguous write-once segments (WOSes) and provides developers with a shared address space of durable, highly available, and strongly consistent WORs to build on. For example, a sequence of WORs can be used to impose a total order, and a set of WORs can keep decisions taken by participants in distributed transaction protocols such as 2PC.

To demonstrate its utility, the paper implements three applications over WormSpace. These applications are built entirely over the WOR API, yet provide efficiency comparable to or better than handcrafted implementations.
- WormPaxos, a Multi-Paxos implementation
- WormLog, a distributed shared log (omitted in my summary for brevity)
- WormTX, a distributed, fault tolerant transaction coordinator
If you like to see how extensions of some of these ideas can be put in action, watch this video by Mahesh Balakrishnan (one of the authors of WormSpace) and Jason Flinn (U Michigan) describe the Delos Storage system for Facebook's Control Plane.
The paper is well-written, and I really enjoyed reading this paper. I think this paper should receive more attention. The paper has another track, which I will not discuss here: Formal verification of WormSpace and reuse of this proof for verifying systems built on top, via the Certified Concurrent Abstraction Layer (CCAL) approach. Sometimes, when a paper includes many ideas, it may dilute the focus and hurt its reception/recognition.
In my summary below, I use many sentences from the paper verbatim. I am saving my MAD questions and in-depth review to the Zoom paper discussion on Wednesday 15:30 EST. Our Zoom Distributed Systems Reading Group meeting is open to anyone who is passionate about distributed systems. Here is an invitation to the Slack workspace for the reading group, where we will conduct pre-meeting discussion and announce the password-protected link to the meeting. (UPDATE: Here is the link to our WormSpace paper discussion.)
The WormSpace system
The WOR abstraction hides the logic for distributed coordination under a data-centric API: a client can capture a WOR; write to a captured WOR; and read the WOR.The address space is divided into write-once segments (WOSes) of fixed size. Segments are explicitly allocated via an alloc call that takes in a segment ID and succeeds if it is as yet unallocated. Once a client has allocated a WOS, any client in the system can operate on WORs within the segment. Specifically, it can capture a WOR; write to it; and read from it.
Clients must capture an address before writing to it to coordinate replicated servers to make the write atomic and immutable. The capture call is similar to a preemtable lock (e.g. phase1, prepare of Paxos): the lock must be acquired to write, but it can be stolen by others. A successful capture call returns a unique, non-zero captureID; a subsequent write by the same thread is automatically parameterized with this ID, and succeeds if the WOR has not been captured by some other client in the meantime.
The WormSpace design is similar to a write-once distributed key-value store: WORs are associated with 64-bit IDs (consisting of segment IDs concatenated with offsets within the segment) and mapped to partitions, which in turn consist of replica sets of wormservers. Partitioning occurs at WOS granularity; to perform an operation on a WOR within a WOS, the client determines the partition storing the segment (via a modulo function) and issues the operation to the replica set.
Each WOR is implemented via a single-shot Paxos consensus protocol, with the wormservers within a partition acting as a set of acceptors. In the context of a single WOR, the wormservers act identically to Paxos acceptors; a capture call translates to a phase 1a prepare message, whereas a write call is a phase 2a accept message. The read protocol mirrors a phase 1a message, but if it encounters a half-written quorum, it completes the write. Each wormserver maintains a map from WOR IDs to the acceptor state for that single-shot Paxos instance. If a map entry is not found, the WOR is treated as unwritten.

The client-side library layers the logic for enforcing write-once segments. Each WOS segment is implemented via a set of data WORs, a single metadata WOR, and a single trim WOR. Allocating the WOS requires writing to the metadata WOR. If two clients race to allocate a WOS, the first one to capture and write the WOR wins.
WormPaxos

WormPaxos is an implementation of Multi-Paxos over WormSpace, exposing a conventional state machine replication (SMR) API to applications. Implementing Multi-Paxos over WormSpace is simple: the sequence of commands is stored on the WormSpace address space. In WormPaxos, servers that wish to replicate state act as WormSpace clients, and are called WP-servers. They can propose new commands by preparing and writing to the next free address; and learn commands by reading the address space in sequential order.
In WormPaxos, a WP-server becomes a sticky leader simply by using a batch capture on a WOS; accordingly, leadership strategies such as sticky leader, rotating leader, etc. can be implemented simply as policies on who should call the batch capture and when. The leader's identity can be stored within the metadata for each segment, obviating the need for WormSpace to know about the notion of a leader or the leadership strategies involved. If the leader crashes, a new leader that allocates the next WOS can batch capture the WOS of the previous leader, complete partially finished operations, and fill in junk values to unwritten WORs to prevent holes in the SMR/Multi-Paxos log.
WormTX
2PC is known to be a blocking protocol in the presence of crash failures. WormTX shows how it can be made non-blocking leveraging on WormSpace. A number of variant protocols is presented to show how the efficiency can be gradually improved.
- [Variant A8: 8 message delays] An obvious solution is to simply store the votes in a set of per-RM WORs. In the WOR-based 2PC protocol, an RM initiates the protocol by contacting the TM (message delay #1); the TM contacts the RMs (#2); they capture the WOR (#3 and #4), and then write to it (#5 and #6); send back their decision to the TM (#7), which sends back a commit message to all the RMs (#8).
- [Variant B6: 6 message delays] Each RM can allocate a dedicated WOS for its decisions and batch capture the WOS in advance.
- [Variant C5: 5 message delays] TM can directly observe the decision by listening for write notifications on the WOS.
- [Variant D4: 4 message delays] Individual RMs can directly listen to each other’s WOSes; this brings us down to 4 message delays.
- [Variant E3: 3 message delays] We do not need a TM, since the final decision is a deterministic function of the WORs, and any RM can time-out on the commit protocol and write a no vote to a blocking RM's WOR to abort the transaction. The initiating RM can simply contact the other RMs on its own to start the protocol (combining #1 and #2 of variant A8), bringing down the number of delays to 3. This variant is not described by Gray and Lamport' Consensus of Transaction Commit paper.
- [Variant F2: 2 message delays]: This works only if RMs can spontaneously start and vote.
Evaluation





Comments