SOSP19 Lineage Stash: Fault Tolerance Off the Critical Path
This paper is by Stephanie Wang (UC Berkeley), John Liagouris (ETH Zurich), Robert Nishihara (UC Berkeley), Philipp Moritz (UC Berkeley), Ujval Misra (UC Berkeley), Alexey Tumanov (UC Berkeley), Ion Stoica (UC Berkeley).
I really liked this paper. It has a simple idea, which has a good chance of getting adopted by real world systems. The presentation was very well done and was very informative. You can watch the presentation video here.
Low-latency processing is very important for data processing, stream processing, graph processing, and control systems. Recovering after failures is also important for them, because for systems composed of 100s of nodes, node failures are part of daily operation.
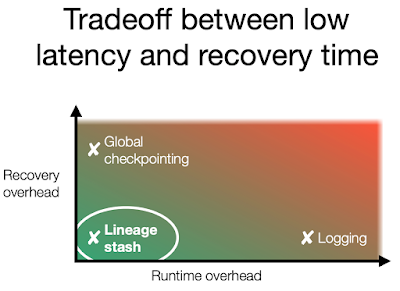
It seems like there is a tradeoff between low latency and recovery time. The existing recovery methods either have low runtime overhead or low recovery overhead, but not both.
Can we have a recovery approach that achieves both low runtime overhead and low recovery overhead? The paper proposes the "lineage stash" idea to achieve that. The idea behind lineage stash is simple.
The first part of the idea is to reduce the amount of data logged by only logging the lineage. Lineage stash logs the pointers to the data messages instead of the data, and also logs task descriptions in case that data needs to be recreated by the previous operation. Lineage stash also logs the order of execution.

The second part of the idea is to do this lineage logging asynchronously, off the critical path of execution. The operators/processes now include a local volatile cache for lineage, which is asynchronously flushed to the underlying remote global lineage storage. The global lineage store is a sharded and replicated key-value datastore.

But then the question becomes, is this still fault tolerant? If we are doing the logging to the global lineage store asynchronously, what if the process crashes before sending the message, and we lose the log information?
The final part of the idea is to use a causal logging approach, and piggybacking the uncommitted lineage information to the other processes/operations for them to store in their stashes as well. So this kind of resembles a tiny decentralized blockchain stored in the stashes of interacting processes/operations.

In the figure, the filter process had executed some tasks and then passed messages to the counter process. Since the logging is off the critical path, the lineage for these tasks was not yet replicated to the global lineage stash. But as part of the rule, the lineage was piggybacked to the messages sent to the counter, so the counter has also a copy of the lineage in its stash, when the filter process crashed. Then in the recovery, the counter process helps by flushing this uncommitted lineage to the global lineage storage for persistence. The recovering filter process can then retrieve and replay this lineage to achieve a correct and quick (on the order of milliseconds) recovery.
Lineage stash idea was implemented and evaluated in Apache Flink for a stream processing word count application over 32 nodes. It was compared against the default global checkpoint recovery, and the default augmented with synchronous logging.

As the figure above shows, by using asynchronous logging approach, linear stash is able to avoid the runtime latency overhead of synchronized logging and matches that of the asynchronous checkpointing approach. Moreover, as the figure below shows, the recovery latency of checkpointing is very high. The lineage stash approach reaches similar recovery latency as the syncronized logging approach.

The lineage stash looks very promising for providing lightweight (off the critical path) fault-tolerance for fine-grain data processing systems. I really like the simplicity of the idea. I feel like I have seen a related idea somewhere else as well. But I can't quite remember it.
I really liked this paper. It has a simple idea, which has a good chance of getting adopted by real world systems. The presentation was very well done and was very informative. You can watch the presentation video here.
Low-latency processing is very important for data processing, stream processing, graph processing, and control systems. Recovering after failures is also important for them, because for systems composed of 100s of nodes, node failures are part of daily operation.
It seems like there is a tradeoff between low latency and recovery time. The existing recovery methods either have low runtime overhead or low recovery overhead, but not both.
- Global checkpoint approach to recovery achieves a low runtime overhead, because a checkpoint/snapshot can be taken asynchronously and off the critical path of the execution. On the other hand, the checkpoint approach has high recovery overhead because the entire system needs to be rolled back to the checkpoint and then start from there again.
- Logging approach to recovery has high runtime overhead, because it synchronously records/logs every data about any nondeterministic execution after the last checkpoint. On the flip side of the coin, it can achieve low overhead to recovery because only the failed processes need to be rolled back a little and resume from there.

Can we have a recovery approach that achieves both low runtime overhead and low recovery overhead? The paper proposes the "lineage stash" idea to achieve that. The idea behind lineage stash is simple.
The first part of the idea is to reduce the amount of data logged by only logging the lineage. Lineage stash logs the pointers to the data messages instead of the data, and also logs task descriptions in case that data needs to be recreated by the previous operation. Lineage stash also logs the order of execution.

The second part of the idea is to do this lineage logging asynchronously, off the critical path of execution. The operators/processes now include a local volatile cache for lineage, which is asynchronously flushed to the underlying remote global lineage storage. The global lineage store is a sharded and replicated key-value datastore.

But then the question becomes, is this still fault tolerant? If we are doing the logging to the global lineage store asynchronously, what if the process crashes before sending the message, and we lose the log information?
The final part of the idea is to use a causal logging approach, and piggybacking the uncommitted lineage information to the other processes/operations for them to store in their stashes as well. So this kind of resembles a tiny decentralized blockchain stored in the stashes of interacting processes/operations.

In the figure, the filter process had executed some tasks and then passed messages to the counter process. Since the logging is off the critical path, the lineage for these tasks was not yet replicated to the global lineage stash. But as part of the rule, the lineage was piggybacked to the messages sent to the counter, so the counter has also a copy of the lineage in its stash, when the filter process crashed. Then in the recovery, the counter process helps by flushing this uncommitted lineage to the global lineage storage for persistence. The recovering filter process can then retrieve and replay this lineage to achieve a correct and quick (on the order of milliseconds) recovery.
Lineage stash idea was implemented and evaluated in Apache Flink for a stream processing word count application over 32 nodes. It was compared against the default global checkpoint recovery, and the default augmented with synchronous logging.

As the figure above shows, by using asynchronous logging approach, linear stash is able to avoid the runtime latency overhead of synchronized logging and matches that of the asynchronous checkpointing approach. Moreover, as the figure below shows, the recovery latency of checkpointing is very high. The lineage stash approach reaches similar recovery latency as the syncronized logging approach.

The lineage stash looks very promising for providing lightweight (off the critical path) fault-tolerance for fine-grain data processing systems. I really like the simplicity of the idea. I feel like I have seen a related idea somewhere else as well. But I can't quite remember it.






Comments