Dissecting performance bottlenecks of strongly-consistent replication protocols
Dissecting performance bottlenecks of strongly-consistent replication protocols
Ailidani Ailijiang, Aleksey Charapko, and Murat Demirbas.
Hey, this is our paper! This appeared in Sigmod 2019 couple weeks back. This paper came out of the dissertation work of Ailidani Ailijiang. He has build the Paxi framework in Go, available on GitHub, to prototype any Paxos flavor quickly. His dissertation is called: "Strongly Consistent Coordination for Wide Area Networks".
Writing blog posts about one's own papers is harder than writing posts about others' papers. When you write a summary of your work, you want to include everything, and cannot detach yourself from specifics easily. I found that I neglected posting about many of our papers, even though it is important to provide brief and accessible summaries of these papers to enhance their reach. It is important to reach more people, because then we can see whether the paper can stand the test of time and push the state of our understanding a bit further. "Science happens only when published work resists critique, otherwise it is speculative fiction. -Frank McSherry"
In this work, we study the performance of Paxos protocols. We take a two-pronged approach, and provide both analytic and empirical evaluations which corroborate and complement each other. We then distill these results to give back-of-the-envelope formulas for estimating the throughput scalability of different Paxos protocols.
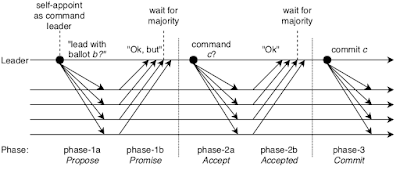
The figure illustrates a single leader (vanilla) Paxos protocol. Yes, three phases look expensive, but in Multi-Paxos, things get a lot better because Phase1 is skipped in the presence of a stable leader. In Multi-Paxos, for upcoming slots (i.e., consensus instances), the leader skips Phase1 and just goes with Phase2. As another optimization, Phase3 messages are piggybacked to the Phase2 messages of upcoming slots rather than being sent separately.
But, even in Multi-Paxos (which we consider henceforth), there is an obvious bottleneck at the leader. The leader is doing a disproportionately large amount of the work, while the followers are slacking off. The followers receive one message and send one message back for each slot. In contrast, the poor leader needs to send N messages in Phase2a, and receive at least a quorum of messages from followers in Phase2b. It turns out, in practice, the overhead of Phase2b is worse than that of Phase2a. For sending Phase1a messages, the leader serializes the message once, and the network card takes care of sending them. For receiving the messages in Phase2b, the leader node needs to deserialize and process each message separately.


Of course many researchers noticed this bottleneck at the leader, and they proposed Paxos flavors to alleviate this issue. EPaxos used opportunistic leaders: any node becomes a leader when it receives a request, and tries to get a ~3/4ths quorum of nodes accept the request to finalize it. In EPaxos, a conflict is possible with concurrent and noncommutative commands, and that requires another round to resolve.


WanKeeper deploys Paxos groups hierarchically. This helps for scalability because key-ranges are sharded to Paxos groups. Using a simpler versions of this idea, Spanner and CockroachDB statically assign keyranges to Paxos groups, and use another service (such as Movedir) to modify the assignments.
WPaxos provides a more decentralized version of sharding. It uses multileaders, and partitions the object-space among these multileaders. Unlike statically partitioned multiple Paxos deployments, WPaxos is able to adapt to the changing access locality through object stealing. Multiple concurrent leaders coinciding in different zones steal ownership of objects from each other using Phase1 of Paxos, and then use Phase2 to commit update-requests on these objects locally until they are stolen by other leaders. To achieve fast Phase2 commits, WPaxos adopts the flexible quorums idea in a novel manner, and appoints Phase2 acceptors to be close to their respective leaders. Here is the link to the journal version of our WPaxos paper for more details.
But what is there to validate/corroborate our experimental results in the first place? For this we compare experimental results of our Paxi MultiPaxos implementation with etcd/Raft implementation. We find that both implementations reach the throughput bottleneck around the same point.

Another thing to observe in this Paxos throughput graph is that, as the throughput approaches system limit, the latency starts to grow exponentially. Different Paxos flavors would have different limiting throughput, and a protocol is more scalable if it has a higher limiting throughput.
If we find a way to plot the increase of latency of protocols, we can determine the limiting throughput of those protocols. The question then becomes: "For a given throughput, what is the average latency for each request?" Queueing theory comes handy for addressing this question, and that is why we employed it for our analytical modeling.

We find that this corresponds to a simple M/D/1 queueing model. M/D/1 represents the queue length in a system having a single server, where arrivals are determined by a Poisson process (occurring at rate $\lambda$) and job service times are fixed and deterministic (serving at rate $\mu$ = 1/s).
Using M/D/1, the model for Multi-Paxos is set up as follows. (For other flavors of Paxos, we extend the model accordingly, and get simulation results respectively.) Latency consists of 3 parts, W + s + rtt, where

To facilitate getting experiment results, the Paxi benchmarker can (1) generate workloads by tuning the read-to-write ratios, creating hot objects, conflicting objects, & locality of access, (2) measure latency & throughput, (3) test scalability by adding more nodes & by increasing dataset size, (4) test availability by injecting faults, and (5) verify the serializability of protocol output utilizin a simple offline read/write linearizability checker.

The figure shows modeled throughput with queueing theory, with 50% write, 50% read, on 1000 objects. As throughput increases the conflict probability also increases, and EPaxos starts to suffer from that. WPaxos shows better scalability than Multi-Paxos.

This figure shows experimental throughput from Paxi implementations under the same conditions. This matches the modeled throughput.

The above figure shows modeled throughput in WANs. EPaxos is hurt by the increase of conflict ratio, and with increased conflict ratio may even perform worse than Multi-Paxos. WPaxos achieves high scalability and low-latency by sharding the key-ranges to leaders and doing this in an access-locality adaptive way.
The figure below shows the experimental results in a WAN deployment, evaluating latency under increased conflict ratios. Paxos is unfazed by conflicts, because the single leader does not experience any conflicts. EPaxos latency remains lower than that of Paxos up to 40% conflict ratio. Conflicts in WPaxos means key-ranges need to be relocated from one leader to another, which involves WAN latency. So as the relocation ratio increases WPaxos latency increases gradually. Similarly VPaxos and WanKeeper also has a gradual increase of latency with respect to increased need to relocate key-ranges.

Please see our paper for many more graphs and results.
Through our analytical modeling and Paxi experiments, we find that the throughput of a protocol is inversely proportional to the load on the busiest node, which is by definition the leader or a leader. The throughput scalability of protocols improve as the load decreases.
Let $L$ be the number of leaders, and Q be quorum size, and c the conflict probability. Then we can approximate Load as follows:
Load = ( 1 + c ) * ( Q-1 ) * 1/L + ( 1 + c ) * 1-1/L
The first part in the summation denotes that a leader is responsible for only 1/L of the requests, and it needs to process messages by Q-1 nodes. Moreover if there is a conflict, with conflict probability c, those fraction of requests incur another round of load.
The second part says that a leader is also responsible for serving as participant in other leaders protocol, adding one message processing cost for the 1-1/L of the requests. Furthermore we also account for $c$ fractional load due to conflicts.
The above formula simplifies to Load = ( 1 + c ) * ( Q + L - 2 ) / L
Recall that, the lower the load, the more scalable is the protocol. Therefore to improve scalability, increase the number of leaders, L. This way each leader get to deal with only a fraction of the requests. However, while increasing L, it is important to make sure this does not increase the conflict rate, c, because each conflict means additional work for the leaders.
For Multi-Paxos, L=1, and the leader is responsible for all requests. But the good news is c=0, because there is no conflicts when there is only one leader. Therefore for each request, the load on the leader is Q-1.
If we take N=9, the load for Multi-Paxos comes to 4. For EPaxos, the load comes to 4/3 *(1+c). For c=1 the load becomes 8/3, and for c=0, the load becomes 4/3.
For WPaxos, c=0, and L=3 and Q=3, so the load comes to 4/3. That means, if EPaxos has no conflict workload, it can has as high throughput as WPaxos, otherwise, WPaxos would have higher throughput. For WanKeeper, c=0, L=3, and Q=3, and a group does not do extra/side work for another, so the load comes to 1.
Note that the load for these protocols matches with the relative throughput scalability of the corresponding protocols.
The Paxi framework is general, and it is possible to implement more than Paxos protocols using Paxi. For example, we implemented the ABD protocol. We haven't implemented any Byzantine Paxos solution, but it would be possible to implement and get results from Byzantine Paxos protocols. It would even be possible to implement gossip protocols with Paxi, maybe the Avalanche protocol.
If you have an idea to implement and benchmark a protocol with Paxi, and have questions, let us know.
2. What are other techniques for alleviating the bottlenecks in Paxos protocols?
Of course you can circumvent Paxos bottlenecks, by not using Paxos. For example, by using chain replication (which has its own drawbacks) you can employ Paxos only in the control path for maintaining the replication topology, and achieve strongly-consistent replication without a bottleneck at leader. Cosmos DB further avoids the downsides of chain replication, and achieves high-throughput, WAN scalable, fault-masking strongly-consistent replication by using nested replicasets in a fanout topology.
Coming back to our question of techniques for alleviating the bottlenecks in Paxos, we have some new promising ideas for improving the dissemination/aggregation paths. Aleksey is exploring these ideas, and we hope to report on them when we get results.
3. Paxos jokes
Here is the cat tax for this long technical post on Paxos. Yes, these are Paxos cats.
Also, if you made it this far, here are some Paxos jokes you might enjoy.
Recently, Aleksey went to the trouble of buying the PaxosJokes.com domain, and building up a website, which you can read more jokes, and submit your jokes about Paxos protocols and distributed systems in general.
Ailidani Ailijiang, Aleksey Charapko, and Murat Demirbas.
Hey, this is our paper! This appeared in Sigmod 2019 couple weeks back. This paper came out of the dissertation work of Ailidani Ailijiang. He has build the Paxi framework in Go, available on GitHub, to prototype any Paxos flavor quickly. His dissertation is called: "Strongly Consistent Coordination for Wide Area Networks".
Writing blog posts about one's own papers is harder than writing posts about others' papers. When you write a summary of your work, you want to include everything, and cannot detach yourself from specifics easily. I found that I neglected posting about many of our papers, even though it is important to provide brief and accessible summaries of these papers to enhance their reach. It is important to reach more people, because then we can see whether the paper can stand the test of time and push the state of our understanding a bit further. "Science happens only when published work resists critique, otherwise it is speculative fiction. -Frank McSherry"
Motivation
The reason Paxos is popular is due to its excellent fault-tolerance properties. Paxos (and Paxos flavors) preserve safety to the face of fully-asynchronous environment, any sequence of faults, and even to the face of network partitions. Paxos and its derivatives are often used for replication in strongly-consistent databases, e.g., CockroachDB, Spanner, YugaByte, PaxosStore. As such, performance of Paxos protocols become important for the performance of distributed databases/systems. However, Paxos variants have widely different performance inherently, and even for the same protocol, different workload, topology, and network conditions result into widely varying performance.In this work, we study the performance of Paxos protocols. We take a two-pronged approach, and provide both analytic and empirical evaluations which corroborate and complement each other. We then distill these results to give back-of-the-envelope formulas for estimating the throughput scalability of different Paxos protocols.
Paxos background
Before we discuss Paxos bottlenecks, here is a brief refresher for the Paxos protocol and variants.
The figure illustrates a single leader (vanilla) Paxos protocol. Yes, three phases look expensive, but in Multi-Paxos, things get a lot better because Phase1 is skipped in the presence of a stable leader. In Multi-Paxos, for upcoming slots (i.e., consensus instances), the leader skips Phase1 and just goes with Phase2. As another optimization, Phase3 messages are piggybacked to the Phase2 messages of upcoming slots rather than being sent separately.
But, even in Multi-Paxos (which we consider henceforth), there is an obvious bottleneck at the leader. The leader is doing a disproportionately large amount of the work, while the followers are slacking off. The followers receive one message and send one message back for each slot. In contrast, the poor leader needs to send N messages in Phase2a, and receive at least a quorum of messages from followers in Phase2b. It turns out, in practice, the overhead of Phase2b is worse than that of Phase2a. For sending Phase1a messages, the leader serializes the message once, and the network card takes care of sending them. For receiving the messages in Phase2b, the leader node needs to deserialize and process each message separately.


Of course many researchers noticed this bottleneck at the leader, and they proposed Paxos flavors to alleviate this issue. EPaxos used opportunistic leaders: any node becomes a leader when it receives a request, and tries to get a ~3/4ths quorum of nodes accept the request to finalize it. In EPaxos, a conflict is possible with concurrent and noncommutative commands, and that requires another round to resolve.


WanKeeper deploys Paxos groups hierarchically. This helps for scalability because key-ranges are sharded to Paxos groups. Using a simpler versions of this idea, Spanner and CockroachDB statically assign keyranges to Paxos groups, and use another service (such as Movedir) to modify the assignments.
WPaxos provides a more decentralized version of sharding. It uses multileaders, and partitions the object-space among these multileaders. Unlike statically partitioned multiple Paxos deployments, WPaxos is able to adapt to the changing access locality through object stealing. Multiple concurrent leaders coinciding in different zones steal ownership of objects from each other using Phase1 of Paxos, and then use Phase2 to commit update-requests on these objects locally until they are stolen by other leaders. To achieve fast Phase2 commits, WPaxos adopts the flexible quorums idea in a novel manner, and appoints Phase2 acceptors to be close to their respective leaders. Here is the link to the journal version of our WPaxos paper for more details.
Analytical modeling using Queueing Theory
Ok, after that brief detour, we continue with analytical modeling of Paxos protocol performance. We use modeling with queueing theory for our analytical results. To fit a queueing model on Paxos protocols, we bootstrap from our experimental results with Paxi. We first fit the model on Multi-Paxos, and then use the queueing model simulations to come up with performance evaluations for other Paxos variants. Then to cross-validate the queueing theory model results, we compare them with the experiment results for the corresponding Paxos variants.But what is there to validate/corroborate our experimental results in the first place? For this we compare experimental results of our Paxi MultiPaxos implementation with etcd/Raft implementation. We find that both implementations reach the throughput bottleneck around the same point.

Another thing to observe in this Paxos throughput graph is that, as the throughput approaches system limit, the latency starts to grow exponentially. Different Paxos flavors would have different limiting throughput, and a protocol is more scalable if it has a higher limiting throughput.
If we find a way to plot the increase of latency of protocols, we can determine the limiting throughput of those protocols. The question then becomes: "For a given throughput, what is the average latency for each request?" Queueing theory comes handy for addressing this question, and that is why we employed it for our analytical modeling.

We find that this corresponds to a simple M/D/1 queueing model. M/D/1 represents the queue length in a system having a single server, where arrivals are determined by a Poisson process (occurring at rate $\lambda$) and job service times are fixed and deterministic (serving at rate $\mu$ = 1/s).
Using M/D/1, the model for Multi-Paxos is set up as follows. (For other flavors of Paxos, we extend the model accordingly, and get simulation results respectively.) Latency consists of 3 parts, W + s + rtt, where
- W: average waiting time in queue
- s: request service time (determined by the size of quorum the leader manages)
- rtt: network latency to reach the quorum
Empirical modeling
We compare/cross-validate the results from queueing theory with the experimental results we obtain from our Paxi framework.The diagram shows main components in our Paxi framework. The developer can easily prototype a distributed coordination/replication protocol by filling in the messages and replica components, shown as shaded blocks.
To facilitate getting experiment results, the Paxi benchmarker can (1) generate workloads by tuning the read-to-write ratios, creating hot objects, conflicting objects, & locality of access, (2) measure latency & throughput, (3) test scalability by adding more nodes & by increasing dataset size, (4) test availability by injecting faults, and (5) verify the serializability of protocol output utilizin a simple offline read/write linearizability checker.
Evaluation results

The figure shows modeled throughput with queueing theory, with 50% write, 50% read, on 1000 objects. As throughput increases the conflict probability also increases, and EPaxos starts to suffer from that. WPaxos shows better scalability than Multi-Paxos.

This figure shows experimental throughput from Paxi implementations under the same conditions. This matches the modeled throughput.

The above figure shows modeled throughput in WANs. EPaxos is hurt by the increase of conflict ratio, and with increased conflict ratio may even perform worse than Multi-Paxos. WPaxos achieves high scalability and low-latency by sharding the key-ranges to leaders and doing this in an access-locality adaptive way.
The figure below shows the experimental results in a WAN deployment, evaluating latency under increased conflict ratios. Paxos is unfazed by conflicts, because the single leader does not experience any conflicts. EPaxos latency remains lower than that of Paxos up to 40% conflict ratio. Conflicts in WPaxos means key-ranges need to be relocated from one leader to another, which involves WAN latency. So as the relocation ratio increases WPaxos latency increases gradually. Similarly VPaxos and WanKeeper also has a gradual increase of latency with respect to increased need to relocate key-ranges.

Please see our paper for many more graphs and results.
Forecasting throughput scalability
Here we give approximate back-of-the-envelope formulas for predicting the limiting throughput of different protocols. These formulas are not the whole story, as they don't show how latency changes as throughput increases as does our queueing theory and empirical results show. But they are useful to relatively rank the scalability of Paxos variants with respect to each other.Through our analytical modeling and Paxi experiments, we find that the throughput of a protocol is inversely proportional to the load on the busiest node, which is by definition the leader or a leader. The throughput scalability of protocols improve as the load decreases.
Let $L$ be the number of leaders, and Q be quorum size, and c the conflict probability. Then we can approximate Load as follows:
Load = ( 1 + c ) * ( Q-1 ) * 1/L + ( 1 + c ) * 1-1/L
The first part in the summation denotes that a leader is responsible for only 1/L of the requests, and it needs to process messages by Q-1 nodes. Moreover if there is a conflict, with conflict probability c, those fraction of requests incur another round of load.
The second part says that a leader is also responsible for serving as participant in other leaders protocol, adding one message processing cost for the 1-1/L of the requests. Furthermore we also account for $c$ fractional load due to conflicts.
The above formula simplifies to Load = ( 1 + c ) * ( Q + L - 2 ) / L
Recall that, the lower the load, the more scalable is the protocol. Therefore to improve scalability, increase the number of leaders, L. This way each leader get to deal with only a fraction of the requests. However, while increasing L, it is important to make sure this does not increase the conflict rate, c, because each conflict means additional work for the leaders.
For Multi-Paxos, L=1, and the leader is responsible for all requests. But the good news is c=0, because there is no conflicts when there is only one leader. Therefore for each request, the load on the leader is Q-1.
If we take N=9, the load for Multi-Paxos comes to 4. For EPaxos, the load comes to 4/3 *(1+c). For c=1 the load becomes 8/3, and for c=0, the load becomes 4/3.
For WPaxos, c=0, and L=3 and Q=3, so the load comes to 4/3. That means, if EPaxos has no conflict workload, it can has as high throughput as WPaxos, otherwise, WPaxos would have higher throughput. For WanKeeper, c=0, L=3, and Q=3, and a group does not do extra/side work for another, so the load comes to 1.
Note that the load for these protocols matches with the relative throughput scalability of the corresponding protocols.
MAD questions
1. What would you prototype with Paxi?The Paxi framework is general, and it is possible to implement more than Paxos protocols using Paxi. For example, we implemented the ABD protocol. We haven't implemented any Byzantine Paxos solution, but it would be possible to implement and get results from Byzantine Paxos protocols. It would even be possible to implement gossip protocols with Paxi, maybe the Avalanche protocol.
If you have an idea to implement and benchmark a protocol with Paxi, and have questions, let us know.
2. What are other techniques for alleviating the bottlenecks in Paxos protocols?
Of course you can circumvent Paxos bottlenecks, by not using Paxos. For example, by using chain replication (which has its own drawbacks) you can employ Paxos only in the control path for maintaining the replication topology, and achieve strongly-consistent replication without a bottleneck at leader. Cosmos DB further avoids the downsides of chain replication, and achieves high-throughput, WAN scalable, fault-masking strongly-consistent replication by using nested replicasets in a fanout topology.
Coming back to our question of techniques for alleviating the bottlenecks in Paxos, we have some new promising ideas for improving the dissemination/aggregation paths. Aleksey is exploring these ideas, and we hope to report on them when we get results.
3. Paxos jokes
Here is the cat tax for this long technical post on Paxos. Yes, these are Paxos cats.
Also, if you made it this far, here are some Paxos jokes you might enjoy.
Recently, Aleksey went to the trouble of buying the PaxosJokes.com domain, and building up a website, which you can read more jokes, and submit your jokes about Paxos protocols and distributed systems in general.





Comments
One more MAD question: How does paxi and friends compare with nopaxos cf. https://www.usenix.org/conference/osdi16/technical-sessions/presentation/li
Ultimately, what people really want is not just consistent replication but scalable ACID _application_ level _transactions_.
I'd be happy to see more research and frameworks in the direction of TAPIR (build consistent transactions with inconsistent replication).