Paper review. Sharding the Shards: Managing Datastore Locality at Scale with Akkio
This paper by Facebook, which appeared in OSDI'18, describes the data locality management service, Akkio. Akkio has been in production use at Facebook since 2014. It manages over 100PB of data, and processes over 10 million data accesses per second.
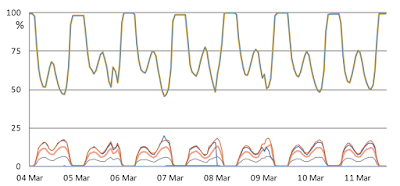
So, let's find suitable home-bases for data, instead of fully replicating it to all datacenters. But the problem is access locality is not static. What was a good location/configuration for the data ceases to become suitable when the data access patterns change. A change in the requesting datacenter can arise because the user travels from one region to another. But, meh, that is old hat, and not very interesting. The paper mentions that the more likely reason for request movements is that because service workloads are shifted from datacenters with high loads to others with lower loads in order to lower service request response latencies. A diurnal peaking pattern is evident in the graphs. During peaks, up to 50% of requests may be shifted to remote datacenters.
Why not shards, but µ-shards? Shards are for datastores, µ-shards are for applications. Shard sizes are set by administrators to balance shard overhead, load balancing, and failure recovery, and they tend to be on the order of gigabytes. Since µ-shards are formed by the client application to refer to a working data set size, they capture access locality better. They are also more amenable to migration. µ-shard migration has an overhead that is many order of magnitude lower than that of shard migration, and its utility is far higher. There is no need to migrate 1GB partition, when the access is to a 1MB portion.
In the rest of this review, we discuss how Akkio leverages the underlying datastore to build a locality management layer, the architecture and components of that management layer, and the evaluation results from deployment of Akkio at Facebook. As always we have a MAD questions section at the end to speculate and free roam.
ZippyDB manages shards as follows. Each shard may be configured to have multiple replicas, with one designated to be the primary and the others referred to as secondaries. A write to a shard is directed to its primary replica, which then replicates the write to the secondary replicas using Paxos to ensure that writes are processed in the same order at each replica. Reads that need to be strongly consistent are directed to the primary replica. If eventual consistency is acceptable then reads can be directed to a secondary.
A shard's replication configuration identifies the number of replicas of the shard and how the replicas are distributed over datacenters, clusters, and racks. A service may specify that it requires three replicas, with two replicas (representing a quorum) in one datacenter for improved write latencies and a third in different datacenter for durability.
A replica set collection refers to the group of all replica sets that have the same replication configuration. Each such collection is assigned a unique id, called location handle. Akkio leverages on replica set collections as housing for µ-shards.

This figure depicts several shard replica sets and a number of µ-shards within the replica sets. You can see datacenters A, B, and C in the figure and imagine it goes all the way to datacenter Z if you like. A replica set collection with location handle 1 has a primary at datacenter A and has two secondaries it replicates to in datacenter B. Replica set collection 345 has a primary in A and secondaries in B and C.
x is a µ-shard originally located in the replica set collection 78 which has a primary in datacenter C, and maybe secondaries in D and E. When access patterns change so that datacenters A and B are better location for µ-shard x, Akkio relocates x from replica set 78 to replica set 1. That means from now on, the writes for x are forwarded to datacenter A, and are automatically replicated to the secondaries of replica set 1 at B and C.
A helpful analogy is to think of replica set collections as condo buildings, which offer different locations and floor plan configurations. You can think of location handle for a replica set collection as the address for the condo building, and µ-shard as the tenant in the condo building. When a µ-shard encounters a need to migrate, Akkio relocates it to a different condo building with suitable location and configuration.

Above is an architectural overview for Akkio. The client application here is View state (which we talk about in the evaluation). The client application is responsible for partitioning data into µ-shards such that it exhibits access locality. The client application must establish its own µ-shard-id scheme that identifies its µ-shards, and specify the µ-shard the data belongs to in the call to the database client library every time it needs to access data in the underlying database.
Harkening back to our analogy above, the µ-shard-id corresponds to the name of the tenant. If you mention that to Akkio, it knows which condo building the tenant lives now and forwards your message. Akkio also acts as the relocation service for the tenants; as the needs of tenants change, Akkio relocates them to different condo buildings, and keeps track of this.
Akkio manages all these functionality transparently to the application using three components: Akkio location service, access counter service, and data placement service.
The location information is configured to have an eventually consistent replica at every datacenter to ensure low read latencies and high availability, with the primary replicas evenly distributed across all datacenters. The eventual consistency is justified because the database has high read-write ratio (> 500). Moreover, distributed in-memory caches are employed at every datacenter to cache the location information to reduce the read load on the database. Note that stale information is not a big problem in ALS, because a µ-shard that is missing in the forwarded location handle will lead to the client application making another ALS query, which is more likely to return new location information.
To decide on the optimal µ-shard placement, DPS uses the following algorithm. First, through querying ACS, DPS computes a per-datacenter score by summing the number of times the µ-shard was accessed from that datacenter over the last X days (where X is configurable), weighting more recent accesses more strongly. The per-datacenter scores for the datacenters on which the replica set collection has replicas are then summed to generate a replica set collection score. If there is a clear winner, DPS pick that winner. Else, among the suitable replica set collection candidates, DPS calculates another score using resource usage data, and go with the highest.
After the optimal location is identified, the migration is performed in a relatively straightforward manner. If the underlying datastore (such as ZippyDB) supports access control lists (ACL) the source µ-shard is restricted to be read-only during the migration. If the datastore does not support ACL (such as the Cassandra implementation used at Facebook), a slightly more involved migration mechanism is employed.


One thing I notice here is, while the replica set collection is a nice abstraction, it leads to some inefficiencies for certain migration patterns. What if we just wanted to swap the primary replica to the location of a secondary replica? (This is a plausible scenario, because the write region may have changed to the location of a secondary replica.) If we were working at a lower layer abstraction, this would be as simple as changing the leader in the Paxos replication group. But since we work on top of the replica set collection abstraction, this will require a full-fledged migration (following the procedure above) to a different replicaset collection where the location of the primary and the secondary replica is reversed.
Wait... Strong consistency is a requirement?? I am surprised strong consistency is required to show the user its feed. I guess this is to improve the user experience by not re-displaying something the user has seen.
Originally, ViewState data was fully replicated across six datacenters. (I presume that was all the datacenters Facebook had back-in-the-day.) Using Akkio with the setup described above led to a 40% smaller storage footprint, a 50% reduction of cross-datacenter traffic, and about a 60% reduction in read and write latencies compared to the original non-Akkio setup. Each remote access notifies the DPS, resulting in approximately 20,000 migrations a second. Using Akkio, roughly 5% of the ViewState reads and writes go to a remote datacenter.
Using Akkio with the setup described above led to a 40% decrease in storage footprint, a roughly 50% reduction of cross-datacenter traffic, negligible increase in read latency (0.4%) and a 60% reduction in write latency. Roughly 0.4% of the reads go remote, resulting in about 1000 migrations a second.

In the figure ViewState is at top, and AccessState at the bottom. The figure shows percentage of accesses to remote data, the number of evaluatePlacement() calls to DPS per second, and the number of ensuing µ-shard migrations per second. For ViewState the number of calls to DPS per second and the number of migrations per second are the same.
The paper mentions the following.
2. Is it possible to support transactions for µ-shards?
Akkio does not currently support inter µ-shard transactions, unless implemented entirely client-side. The paper mentions that providing this support is left for future work.
In our work on wPaxos, we not only showed policies for migration of µ-shards, but also implemented transactions on µ-shards.
We have recently presented a more detailed study on access locality and migration policies, and we hope to expand on that work in the context of Azure Cosmos DB.
3. How does this compare with other datastores?
Many applications already group together data by prefixing keys with a common identifier to ensure that related data are assigned to the same shard. FoundationDB is an example, although they don't have much of a geolocation and location management story yet. Some databases support the concept of separate partition keys, like Cassandra. But you need to deal with locality management yourself as the application developer. Spanner supports directories, and a move-dir command, although Spanner may shard directories into multiple fragments. CockroachDB uses small partitions, that should be amenable to migration. Migration can be done by relocating the Raft replica set responsible for a partition to destination datacenters gradually by leveraging Raft reconfiguration. But I don't think they have a locality management layer yet.
4. What are the limitations to the locality management?
As the paper mentions, some data is not suitable for µ-sharding as they cannot be broken into self-contained small parts without references to other entities. For example, Facebook social graph data and Google search graph data.
When there are multiple writers around the globe, the locality management technique and specifically Akkio's implementation leveraging datastores that use a primary and secondaries will fall short. Also when there are reads from many regions and request serving latency is to be minimized, efficient and streamlined full replication is a better choice.
Cosmos DB, Azure's cloud-native database service, offers frictionless global distribution across any number of 50+ Azure regions, you choose to deploy it on. It enables you to elastically scale throughput and storage worldwide on-demand quickly, and you pay only for what you provision. It guarantees single-digit-millisecond latencies at the 99th percentile, supports multiple read/write regions around the globe, multiple consistency models, and is backed by comprehensive service level agreements (SLAs).
5. Micro is the new black
µ-services, µ-shards. And even FaaS. There is an increasingly strong tendency with going micro. I think the root of this is because going with finer granularity makes for a more flexible, adaptable, agile distributed system.
Why do we need to manage locality?
Replicating all data to all datacenters is difficult to justify economically (due to the extra storage and WAN networking costs) when acceptable durability and request serving latency could be achieved with 3 replicas. It looks like Facebook had been doing full replication (at least for ViewState and AccessState applications discussed in the evaluation) to all the 6 datacenters back-in-the-day, but as the operation and the number of datacenters grew, this became untenable.So, let's find suitable home-bases for data, instead of fully replicating it to all datacenters. But the problem is access locality is not static. What was a good location/configuration for the data ceases to become suitable when the data access patterns change. A change in the requesting datacenter can arise because the user travels from one region to another. But, meh, that is old hat, and not very interesting. The paper mentions that the more likely reason for request movements is that because service workloads are shifted from datacenters with high loads to others with lower loads in order to lower service request response latencies. A diurnal peaking pattern is evident in the graphs. During peaks, up to 50% of requests may be shifted to remote datacenters.

Why are µ-shards the right abstraction for managing locality?
The paper advocates for µ-shards (micro-shards), very fine grained datasets (from ~1Kb to ~1Mb), to serve as the unit of migration and the abstraction for managing locality. A µ-shard contains multiple key-value pairs or database table rows, and should be chosen such that it exhibits strong access locality. Examples could be Facebook viewing history to inform subsequent content, user profile information, Instagram messaging queues, etc.Why not shards, but µ-shards? Shards are for datastores, µ-shards are for applications. Shard sizes are set by administrators to balance shard overhead, load balancing, and failure recovery, and they tend to be on the order of gigabytes. Since µ-shards are formed by the client application to refer to a working data set size, they capture access locality better. They are also more amenable to migration. µ-shard migration has an overhead that is many order of magnitude lower than that of shard migration, and its utility is far higher. There is no need to migrate 1GB partition, when the access is to a 1MB portion.
Enter Akkio
To address these, the paper introduces Akkio, a µ-shard based locality management service for distributed datastores. Akkio is layered between client applications and the distributed datastore systems that implements sharding. It decides in which datacenter to place and how and when to migrate data for reducing access latencies and WAN communication. It helps direct each data access to where the target data is located, and it tracks each access to be able to make appropriate placement decisions.In the rest of this review, we discuss how Akkio leverages the underlying datastore to build a locality management layer, the architecture and components of that management layer, and the evaluation results from deployment of Akkio at Facebook. As always we have a MAD questions section at the end to speculate and free roam.
Underlying datastore & shard management
The paper discusses ZippyDB, as an underlying datastore that Akkio layers upon. (Akkio also runs over Cassandra, and 3 other internally developed databases at Facebook.)ZippyDB manages shards as follows. Each shard may be configured to have multiple replicas, with one designated to be the primary and the others referred to as secondaries. A write to a shard is directed to its primary replica, which then replicates the write to the secondary replicas using Paxos to ensure that writes are processed in the same order at each replica. Reads that need to be strongly consistent are directed to the primary replica. If eventual consistency is acceptable then reads can be directed to a secondary.
A shard's replication configuration identifies the number of replicas of the shard and how the replicas are distributed over datacenters, clusters, and racks. A service may specify that it requires three replicas, with two replicas (representing a quorum) in one datacenter for improved write latencies and a third in different datacenter for durability.
A replica set collection refers to the group of all replica sets that have the same replication configuration. Each such collection is assigned a unique id, called location handle. Akkio leverages on replica set collections as housing for µ-shards.

This figure depicts several shard replica sets and a number of µ-shards within the replica sets. You can see datacenters A, B, and C in the figure and imagine it goes all the way to datacenter Z if you like. A replica set collection with location handle 1 has a primary at datacenter A and has two secondaries it replicates to in datacenter B. Replica set collection 345 has a primary in A and secondaries in B and C.
x is a µ-shard originally located in the replica set collection 78 which has a primary in datacenter C, and maybe secondaries in D and E. When access patterns change so that datacenters A and B are better location for µ-shard x, Akkio relocates x from replica set 78 to replica set 1. That means from now on, the writes for x are forwarded to datacenter A, and are automatically replicated to the secondaries of replica set 1 at B and C.
A helpful analogy is to think of replica set collections as condo buildings, which offer different locations and floor plan configurations. You can think of location handle for a replica set collection as the address for the condo building, and µ-shard as the tenant in the condo building. When a µ-shard encounters a need to migrate, Akkio relocates it to a different condo building with suitable location and configuration.
Akkio Design and Architecture
I once heard that "All problems in computer science can be solved by another level of indirection". Akkio is built upon the following level of indirection idea. Akkio maps µ-shards onto shard replica set collections whose shards are in turn mapped to datastore storage servers. This is worth repeating, because this is the key idea in Akkio. When running on top of ZippyDB, Akkio places µ-shards on, and migrates µ-shards between different such replica set collections. This allows Akkio to piggyback on ZippyDB functionality to provide replication, consistency, and intra-cluster load balancing.
Above is an architectural overview for Akkio. The client application here is View state (which we talk about in the evaluation). The client application is responsible for partitioning data into µ-shards such that it exhibits access locality. The client application must establish its own µ-shard-id scheme that identifies its µ-shards, and specify the µ-shard the data belongs to in the call to the database client library every time it needs to access data in the underlying database.
Harkening back to our analogy above, the µ-shard-id corresponds to the name of the tenant. If you mention that to Akkio, it knows which condo building the tenant lives now and forwards your message. Akkio also acts as the relocation service for the tenants; as the needs of tenants change, Akkio relocates them to different condo buildings, and keeps track of this.
Akkio manages all these functionality transparently to the application using three components: Akkio location service, access counter service, and data placement service.
Akkio location service (ALS)
ALS maintains a location database. The location database is used on each data access to look up the location of the target µ-shard. The ZippyDB client library makes a call to the Akkio client library getLocation(µ-shard-id) function which returns a ZippyDB location handle (representing a replica set collection) obtained from the location database. This location handle (the condo building address in our analogy) enables ZippyDB’s client library to direct the access request to the appropriate storage server. The location database is updated when a µ-shard is migrated.The location information is configured to have an eventually consistent replica at every datacenter to ensure low read latencies and high availability, with the primary replicas evenly distributed across all datacenters. The eventual consistency is justified because the database has high read-write ratio (> 500). Moreover, distributed in-memory caches are employed at every datacenter to cache the location information to reduce the read load on the database. Note that stale information is not a big problem in ALS, because a µ-shard that is missing in the forwarded location handle will lead to the client application making another ALS query, which is more likely to return new location information.
Access counter service (ACS)
Each time the client service accesses a µ-shard, the Akkio client library requests the ACS to record the access, the type of access, and the location from which the access was made, so that Akkio collects statistics for making µ-shard placement and migration decisions. This request is issued asynchronously so that it is not in the critical path.Data placement service (DPS)
The DPS initiates and manages µ-shard migrations. The Akkio Client Library asynchronously notifies the DPS that a µ-shard placement may be suboptimal whenever a data access request needs to be directed to a remote datacenter. The DPS re-evaluates the placement of a µ-shard only when it receives such a notification, in a reactive fashion. The DPS maintains historical migration data: e.g., time of last migration to limit migration frequency (to prevent the ping-ponging of µ-shards).To decide on the optimal µ-shard placement, DPS uses the following algorithm. First, through querying ACS, DPS computes a per-datacenter score by summing the number of times the µ-shard was accessed from that datacenter over the last X days (where X is configurable), weighting more recent accesses more strongly. The per-datacenter scores for the datacenters on which the replica set collection has replicas are then summed to generate a replica set collection score. If there is a clear winner, DPS pick that winner. Else, among the suitable replica set collection candidates, DPS calculates another score using resource usage data, and go with the highest.
After the optimal location is identified, the migration is performed in a relatively straightforward manner. If the underlying datastore (such as ZippyDB) supports access control lists (ACL) the source µ-shard is restricted to be read-only during the migration. If the datastore does not support ACL (such as the Cassandra implementation used at Facebook), a slightly more involved migration mechanism is employed.


One thing I notice here is, while the replica set collection is a nice abstraction, it leads to some inefficiencies for certain migration patterns. What if we just wanted to swap the primary replica to the location of a secondary replica? (This is a plausible scenario, because the write region may have changed to the location of a secondary replica.) If we were working at a lower layer abstraction, this would be as simple as changing the leader in the Paxos replication group. But since we work on top of the replica set collection abstraction, this will require a full-fledged migration (following the procedure above) to a different replicaset collection where the location of the primary and the secondary replica is reversed.
Evaluation
The paper gives an evaluation of Akkio using 4 applications used in Facebook, of which I will only cover the first two.ViewState
ViewState stores a history of content previously shown to a user. Each time a user is shown some content, an additional snapshot is appended to the ViewState data. ViewState data is read on the critical path when displaying content, so minimizing read latencies is important. The data needs to be replicated 3-ways for durability. Strong consistency is a requirement.Wait... Strong consistency is a requirement?? I am surprised strong consistency is required to show the user its feed. I guess this is to improve the user experience by not re-displaying something the user has seen.
Originally, ViewState data was fully replicated across six datacenters. (I presume that was all the datacenters Facebook had back-in-the-day.) Using Akkio with the setup described above led to a 40% smaller storage footprint, a 50% reduction of cross-datacenter traffic, and about a 60% reduction in read and write latencies compared to the original non-Akkio setup. Each remote access notifies the DPS, resulting in approximately 20,000 migrations a second. Using Akkio, roughly 5% of the ViewState reads and writes go to a remote datacenter.
AccessState
The second application is AccessState. AccessState stores information about user actions taken in response to content displayed to the user. The information includes the action taken, what content it was related to, a timestamp of when the action was taken, etc. The data needs to be replicated three ways but only needs to be eventually consistent.Using Akkio with the setup described above led to a 40% decrease in storage footprint, a roughly 50% reduction of cross-datacenter traffic, negligible increase in read latency (0.4%) and a 60% reduction in write latency. Roughly 0.4% of the reads go remote, resulting in about 1000 migrations a second.

In the figure ViewState is at top, and AccessState at the bottom. The figure shows percentage of accesses to remote data, the number of evaluatePlacement() calls to DPS per second, and the number of ensuing µ-shard migrations per second. For ViewState the number of calls to DPS per second and the number of migrations per second are the same.
MAD questions
1. What are some future applications for Akkio?The paper mentions the following.
Akkio can be used to migrate µ-shards between cold storage media (e.g. HDDs) and hot storage media (e.g., SSDs) on changes in data temperatures, similar in spirit to CockroachDB’s archival partitioning support. For public cloud solutions, Akkio could migrate µ-shards when shifting application workloads from one cloud provider to another cloud provider that is operationally less expensive. When resharding is required, Akkio could migrate µ-shards, on first access, to newly instantiated shards, allowing a more gentle, incremental form of resharding in situations where many new nodes come online simultaneously.I had written about the need for data aware distributed systems/protocols in 2015.
This trend may indicate that the distributed algorithms should need to adopt to the data it operates on to improve performance. So, we may see the adoption of machine-learning as input/feedback to the algorithms, and the algorithms becoming data-driven and data-aware. (For example, this could be a good way to attack the tail-latency problem discussed here.)I think the trend is still strong. And we will see more work on data aware distributed systems/protocols in the coming years.
Similarly, driven by the demand from the large-scale cloud computing services, we may see power-management, energy-efficiency, electricity-cost-efficiency as requirements for distributed algorithms. Big players already partition data as hot, warm, cold, and employ tricks to reduce power. We may see algorithms becoming more aware of this.
2. Is it possible to support transactions for µ-shards?
Akkio does not currently support inter µ-shard transactions, unless implemented entirely client-side. The paper mentions that providing this support is left for future work.
In our work on wPaxos, we not only showed policies for migration of µ-shards, but also implemented transactions on µ-shards.
We have recently presented a more detailed study on access locality and migration policies, and we hope to expand on that work in the context of Azure Cosmos DB.
3. How does this compare with other datastores?
Many applications already group together data by prefixing keys with a common identifier to ensure that related data are assigned to the same shard. FoundationDB is an example, although they don't have much of a geolocation and location management story yet. Some databases support the concept of separate partition keys, like Cassandra. But you need to deal with locality management yourself as the application developer. Spanner supports directories, and a move-dir command, although Spanner may shard directories into multiple fragments. CockroachDB uses small partitions, that should be amenable to migration. Migration can be done by relocating the Raft replica set responsible for a partition to destination datacenters gradually by leveraging Raft reconfiguration. But I don't think they have a locality management layer yet.
4. What are the limitations to the locality management?
As the paper mentions, some data is not suitable for µ-sharding as they cannot be broken into self-contained small parts without references to other entities. For example, Facebook social graph data and Google search graph data.
When there are multiple writers around the globe, the locality management technique and specifically Akkio's implementation leveraging datastores that use a primary and secondaries will fall short. Also when there are reads from many regions and request serving latency is to be minimized, efficient and streamlined full replication is a better choice.
Cosmos DB, Azure's cloud-native database service, offers frictionless global distribution across any number of 50+ Azure regions, you choose to deploy it on. It enables you to elastically scale throughput and storage worldwide on-demand quickly, and you pay only for what you provision. It guarantees single-digit-millisecond latencies at the 99th percentile, supports multiple read/write regions around the globe, multiple consistency models, and is backed by comprehensive service level agreements (SLAs).
5. Micro is the new black
µ-services, µ-shards. And even FaaS. There is an increasingly strong tendency with going micro. I think the root of this is because going with finer granularity makes for a more flexible, adaptable, agile distributed system.





Comments