SDPaxos: Building efficient semi-decentralized geo-replicated state machines
In the last decade, the Paxos protocol family grew with the addition of new categories.
This paper, which appeared in SOCC 18, proposes SDPaxos which prescribes separating the control plane (single leader) from the replication plane (multiple leaders). SD in SDPaxos stands for "semi-decentralized".
The motivation for this stems from the following observation. Single leader Paxos approach has a centralized leader and runs into performance bottleneck problems. On the other hand, the leaderless (or opportunistic multileader) approach is fully decentralized but suffers from the conflicting command problems. Taking a hybrid approach to capture the best of both worlds, SDPaxos makes the command-leaders to be decentralized (the closest replica can lead the command), but the ordering-leader (i.e., the sequencer) is still centralized/unique in the system.
Below I give a brief explanation of the Paxos protocol categories before I discuss how SDPaxos compares and contrasts with those.
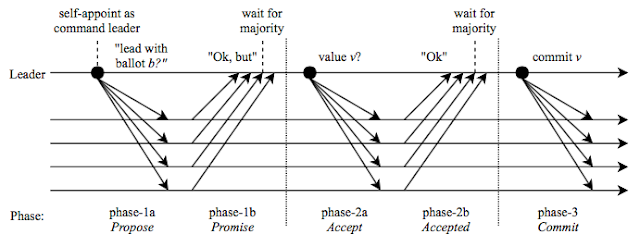
Paxos runs in 3 phases: propose (phase-1), accept (phase-2), and commit (phase-3).
It's important to see that after phase-2, an anchored value cannot be overridden later as it is guaranteed that any leader with higher ballot number would learn it as part of its phase-1 before proposing a value in its phase-2.
You can find more information on Paxos in this blog, and especially Modeling Paxos in TLA+ could be of interest to you.
Unfortunately, services like E-commerce and social network can generate high-contention workload, with many interfering commands on the same object from multiple clients. This problem is aggrevated in wide area network deployments: since requests take much longer time to finish, the probability of contention rises.
WPaxos uses sharding of the key space and takes advantage of flexible quorums idea to improve WAN performance, especially in the presence of access locality. In WPaxos, every node can own some objects/microshards and operate on these independently. Unlike Vertical Paxos, WPaxos does not consider changing the object/microshard ownership as a reconfiguration operation and does not require an external consensus group. Instead WPaxos performs object/microshard migration between leaders by carrying out a phase-1 across the WAN with a higher ballot number, and commands are committed via phase-2 within the region or neighboring regions.
To address this issue, SDPaxos divides the consensus protocol in 2 parts: durably replicating each command across replicas without global order (via C-instance Paxos), and ordering all commands to enforce the consistency guarantee (via O-instance Paxos). Replicating via C-instance Paxos is completely decentralized where every replica can freely propose commands and replicate them to other replicas. This evenly distributes the load among replicas, and enables clients to always contact the nearest one. On the other hand, as part of O-instance Paxos, one replica is elected as the sequencer and handles the ordering in a centralized manner: the global view enables this replica to always order commands appropriately. Provided that the ordering messages are smaller than replication messages, the load on the sequencer will not be as severe as that on the single leader in Paxos.
Fault tolerance is provided as both the replicating and ordering instances are conducted based on Paxos. Each replica proposes commands in a series of C-instances of its own to produce its partial log. The sequencer proposes replicas' IDs in O-instances to produce an assignment log. Based on the assignment log, all replicas' partial logs are finally merged into a global log.
So, SDPaxos is like Paxos, but it has local leader in each region. This way it avoids the cost of going to the leader, and back.
Also SDPaxos is like EPaxos but with no conflicts, ever!
In SDPaxos, the sequencer is one node, but is backed by O-instances. A new sequencer can be chosen easily in a fault-tolerant way using Phase-1 of Paxos over O-instances. This alleviates the availability problems due to the serializer failure in systems that use Paxos for serializing the log in a central region. In such systems (e.g., Calvin) if the single log serializer is Paxos-replicated within a region, then the availability suffers on region failure. Instead, if the serializer is Paxos-replicated across regions then the performance suffers.

In this example, upon receiving a client request for a command, replica R0 becomes the command leader of this command, picks one of its own C-instance and replicates the command to others (using the C-accept, i.e., Accept phase message of the C-instance). In the meantime, this C-accept also informs the sequencer (R2) to start an O-instance for this command. Then R2 proposes R0’s ID in the next (e.g., the jth) O-instance and sends O-accepts to others, to assign this command to the jth global slot. Replicas will then accept these instances and send C-ACKs and O-ACKs to R0; R2 also sends an O-ACK as it has sent an O-accept to itself. The algorithm denotes the ith C-instance of Rn as Cni, and the jth O-instance as Oj.

A command being ready requires the C-instance and enough number of O-instances be committed. The conditions of an instance being committed and a command being ready are defined in lines 18 through 31, which we discuss next. There are two questions here.

In 3-replica groups, when the command leader receives O-ACK from the sequencer, the majority (2 out of 3) is readily established for O-instance completion. This provides the one-round-trip consensus. (For the case, the command leader is also the sequencer, sequencing can be done in advance and one round-trip is satisfied as well.)

In 5-replica groups, a command can also be ready in one round trip, but unlike the case of three replicas, an O-instance cannot be accepted by a majority in half a round trip. Instead, SDPaxos lets each non-sequencer replica commit an O-instance, upon receiving the O-accept from the sequencer (line 29). Here, the O-instance does not rigorously follow Paxos, which raises a complication for recovery: if this non-sequencer replica and the sequencer fail, we cannot recover this O-instance simply by Paxos because the other alive replicas may have not seen the O-accept yet. However, the paper discusses a way for SDPaxos to correctly recover the O-instances of all replicas' ready commands even in such cases (omitted in my review), and is able to allow for 1-round-trip commits for N=5.

Note that the dynamic per key leader approach in WPaxos still has an edge over SDPaxos when there is good locality in the workload (which is often the case in practice) and/or when the number of replicas is greater than 5 (which is often the case for geo-replicated databases). It may be possible to use WPaxos for coordination across regions and integrate SDPaxos for coordination within the region upto 5 replicas.
As another optimization, in some cases, it is possible to divide the responsibility of sequencer to all replicas for more load balancing. For example, in a key-value store, we can partition the key space using approaches like consistent hashing, then make each replica order the commands on one partition (commands on different keys can be out-of-order). Again, in this case, it would be possible to use the WPaxos approach for safe key-stealing among the sequencers, and dynamically adapt to the access pattern, rather than being confined to static partitioning.


I wrote above that "Provided that the ordering messages are smaller than the replication messages, the load on the sequencer will not be as severe as that on the single leader in Paxos." But on close inspection I don't think I believe that sentence anymore. Ailidani, Aleksey, and I have done a detailed bottleneck analysis of Paxos protocol categories (under submission), and we found that the outcast messages are not the biggest source of bottleneck for the leader, as they are serialized once before being sent out to the replicas. The incast messages contribute most to the bottleneck, as the CPU needs to process them one by one and they queue up. Moreover, the incast messages are ACK messages, which are already small, and SDPaxos does not make them smaller. So, maybe SDPaxos does not improve significantly on the single-leader bottleneck in Paxos. On the other hand, it is true that SDPaxos helps distribute the client request load to the C-instance replicas relieving that bottleneck, and it definitely helps with lowering the latency in WAN.
2. How would you build reconfiguration of participants for this protocol?
Reconfiguration of participants is important to re-establish fault-tolerance capability by replacing failed replicas by accepting fresh new replicas to the system. How would reconfiguration work for SDPaxos? Would Raft's 2-phase reconfiguration method apply readily for SDPaxos?
3. What are additional challenges for efficient strongly-consistent geo-replication implementation at scale?
I am at Microsoft Azure Cosmos DB for my sabbatical. Cosmos DB recently introduced general-availability of multiple write regions. While providing strong-consistency with multi-master writes allowed from any region has cost across the globe, could SDPaxos ideas help improve efficiency further?
- Rotating leader: Mencius
- Leaderless: EPaxos, Fast Paxos
- Paxos federations: Spanner, vertical Paxos
- Dynamic key-leader: WPaxos
This paper, which appeared in SOCC 18, proposes SDPaxos which prescribes separating the control plane (single leader) from the replication plane (multiple leaders). SD in SDPaxos stands for "semi-decentralized".
The motivation for this stems from the following observation. Single leader Paxos approach has a centralized leader and runs into performance bottleneck problems. On the other hand, the leaderless (or opportunistic multileader) approach is fully decentralized but suffers from the conflicting command problems. Taking a hybrid approach to capture the best of both worlds, SDPaxos makes the command-leaders to be decentralized (the closest replica can lead the command), but the ordering-leader (i.e., the sequencer) is still centralized/unique in the system.
Below I give a brief explanation of the Paxos protocol categories before I discuss how SDPaxos compares and contrasts with those.
Plain vanilla Paxos
Paxos provides fault tolerant consensus among a set of nodes.- Agreement: No two correct nodes can decide on different values.
- Validity: If all initial values are same, nodes must decide that value.
- Termination: Correct nodes decide eventually.

Paxos runs in 3 phases: propose (phase-1), accept (phase-2), and commit (phase-3).
- A node tries to become the leader by proposing a unique ballot number b to its followers with a phase-1a message. The followers acknowledge a leader with the highest ballot seen so far, or reject it with a ballot seen with a number greater than b. Receiving any rejection fails the candidate.
- In the absence of a rejection, a node becomes leader and advances to phase-2 after receiving a majority quorum of acknowledgments. In this phase, the leader chooses a suitable value v for its ballot. The value would be some uncommitted value associated with the highest ballot learned in previous phase, or a new value if no pending value exists. The leader commands its followers to accept the value v and waits for acknowledgement messages. Once the majority of followers acknowledge the value, it becomes anchored and cannot be revoked. Again a single rejection message (carrying an observed higher ballot number) received in phase-2b nullifies the leadership of the node, and sends it back to phase-1 to try with a higher ballot number.
- Finally, the leader sends a commit message in phase-3 that allows the followers to commit and apply the value to their respected state machines.
It's important to see that after phase-2, an anchored value cannot be overridden later as it is guaranteed that any leader with higher ballot number would learn it as part of its phase-1 before proposing a value in its phase-2.
You can find more information on Paxos in this blog, and especially Modeling Paxos in TLA+ could be of interest to you.
Single leader approach
The traditional single-leader Paxos protocol employs a centralized leader to process all client requests and propose commands. The single leader takes a significantly heavier load than the other replicas, and becomes a performance bottleneck. Moreover, in geo-replication, clients not co-located with the leader need to send the requests to the remote leader, which incurs significantly higher wide-area network latency.Mencius approach
Mencius is a multileader version of Paxos that aims to eliminate the single leader bottleneck in Paxos. Mencius achieves load balancing by partitioning the consensus instances among multiple servers. E.g., if we have 3 servers, server 0 is responsible for acting as a leader for consensus instances numbered 0,3,6, server 1 for 1,4,7, and server 2 for 2,5,8, etc. Mencius tries to avoid the straggler problem by making the replicas skip their turns when they fall behind, however, it cannot fully eliminate the slow-down. Since it uses multiple leaders, Mencius also loses out on the "serve reads locally at the leader" optimization possible in Paxos.Optimistic leaders approach
EPaxos is a solution, where every node can opportunistically become a leader for some command and commit it. When a command does not interfere with other concurrent commands, it is committed in a single round after receiving the acks from a fast quorum (which is approximately 3/4ths of all nodes). In a sense, EPaxos compresses the phase-2 to be a part of phase-1 when there are no conflicts. However, if the fast quorum detects a conflict between the commands, EPaxos defaults back to the traditional Paxos mode and proceeds with a second phase to establish order on the conflicting commands.Unfortunately, services like E-commerce and social network can generate high-contention workload, with many interfering commands on the same object from multiple clients. This problem is aggrevated in wide area network deployments: since requests take much longer time to finish, the probability of contention rises.
Multileader approach
Spanner and CockroachDB are examples of databases that uses a federation of Paxos groups to work on different partitions/shards. These partitioned consensus systems employ another solution on top (such as vertical Paxos) for relocating/assigning data from one Paxos group to another.WPaxos uses sharding of the key space and takes advantage of flexible quorums idea to improve WAN performance, especially in the presence of access locality. In WPaxos, every node can own some objects/microshards and operate on these independently. Unlike Vertical Paxos, WPaxos does not consider changing the object/microshard ownership as a reconfiguration operation and does not require an external consensus group. Instead WPaxos performs object/microshard migration between leaders by carrying out a phase-1 across the WAN with a higher ballot number, and commands are committed via phase-2 within the region or neighboring regions.
The SDPaxos approach
The root of the inefficiency of leaderless and multileader protocols is the decentralized coordination pattern. Although decentralization addresses the single-leader bottleneck as every replica can propose commands, the replicas still need to agree on a total order on conflicting commands proposed by different replicas to avoid inconsistent state.To address this issue, SDPaxos divides the consensus protocol in 2 parts: durably replicating each command across replicas without global order (via C-instance Paxos), and ordering all commands to enforce the consistency guarantee (via O-instance Paxos). Replicating via C-instance Paxos is completely decentralized where every replica can freely propose commands and replicate them to other replicas. This evenly distributes the load among replicas, and enables clients to always contact the nearest one. On the other hand, as part of O-instance Paxos, one replica is elected as the sequencer and handles the ordering in a centralized manner: the global view enables this replica to always order commands appropriately. Provided that the ordering messages are smaller than replication messages, the load on the sequencer will not be as severe as that on the single leader in Paxos.
Fault tolerance is provided as both the replicating and ordering instances are conducted based on Paxos. Each replica proposes commands in a series of C-instances of its own to produce its partial log. The sequencer proposes replicas' IDs in O-instances to produce an assignment log. Based on the assignment log, all replicas' partial logs are finally merged into a global log.
Comparison with other protocols
The separation between C-instances and O-instances is the source of SDPaxos's advantages over existing protocols. The decentralization distributes load evenly across replicas, and allows clients to always contact the nearest replica in geo-replication to serve as the command leader. The O-instance leader, i.e., the sequencer, provides conflict free operation.So, SDPaxos is like Paxos, but it has local leader in each region. This way it avoids the cost of going to the leader, and back.
Also SDPaxos is like EPaxos but with no conflicts, ever!
In SDPaxos, the sequencer is one node, but is backed by O-instances. A new sequencer can be chosen easily in a fault-tolerant way using Phase-1 of Paxos over O-instances. This alleviates the availability problems due to the serializer failure in systems that use Paxos for serializing the log in a central region. In such systems (e.g., Calvin) if the single log serializer is Paxos-replicated within a region, then the availability suffers on region failure. Instead, if the serializer is Paxos-replicated across regions then the performance suffers.
The protocol

In this example, upon receiving a client request for a command, replica R0 becomes the command leader of this command, picks one of its own C-instance and replicates the command to others (using the C-accept, i.e., Accept phase message of the C-instance). In the meantime, this C-accept also informs the sequencer (R2) to start an O-instance for this command. Then R2 proposes R0’s ID in the next (e.g., the jth) O-instance and sends O-accepts to others, to assign this command to the jth global slot. Replicas will then accept these instances and send C-ACKs and O-ACKs to R0; R2 also sends an O-ACK as it has sent an O-accept to itself. The algorithm denotes the ith C-instance of Rn as Cni, and the jth O-instance as Oj.

A C-instance can come from any node without a Paxos
phase-1a, because each replica has its own distinct replication
log for C-instance. The C-instance messages do not conflict with each other and gets
accepted immediately. The C-instance messages do not even need a ballotnum; the
ballotnum used is that of the O-instance to denote epoch (i.e., which sequencer the sender thinks is still in-charge).
- The safety question is: How do we ensure that the replication is anchored (performed at the majority quorum) from the command leader perspective?
- The performance question is: How do we achieve consensus in one round while satisfying the safety concern?
The 1-round feat
In the best case when O-instance of the sequencer overlaps perfectly with the C-instance of the command replication leader, consensus is achieved in one round-trip time ---the optimal possible. But, since the O-instance starts half a round trip later than the C-instance for non-sequencer replicas, it is not always possible to optimize the O-instance completion to just half a round trip to achieve the one-round-trip latency. But the paper shows how this can be achieved for N=3 and N=5 replicas. In groups with more than 5 replicas, the O-instances still need one round trip, thus the overall latency remains at 1.5 round-trips.
In 3-replica groups, when the command leader receives O-ACK from the sequencer, the majority (2 out of 3) is readily established for O-instance completion. This provides the one-round-trip consensus. (For the case, the command leader is also the sequencer, sequencing can be done in advance and one round-trip is satisfied as well.)

In 5-replica groups, a command can also be ready in one round trip, but unlike the case of three replicas, an O-instance cannot be accepted by a majority in half a round trip. Instead, SDPaxos lets each non-sequencer replica commit an O-instance, upon receiving the O-accept from the sequencer (line 29). Here, the O-instance does not rigorously follow Paxos, which raises a complication for recovery: if this non-sequencer replica and the sequencer fail, we cannot recover this O-instance simply by Paxos because the other alive replicas may have not seen the O-accept yet. However, the paper discusses a way for SDPaxos to correctly recover the O-instances of all replicas' ready commands even in such cases (omitted in my review), and is able to allow for 1-round-trip commits for N=5.

Note that the dynamic per key leader approach in WPaxos still has an edge over SDPaxos when there is good locality in the workload (which is often the case in practice) and/or when the number of replicas is greater than 5 (which is often the case for geo-replicated databases). It may be possible to use WPaxos for coordination across regions and integrate SDPaxos for coordination within the region upto 5 replicas.
Optimizations
As an optimization for reads, SDPaxos uses sequencer leases to authorize the sequencer to directly reply to the read requests. In contrast, such an optimization is not possible for leaderless approaches, as there is no single/dedicated leader to lease and read from.As another optimization, in some cases, it is possible to divide the responsibility of sequencer to all replicas for more load balancing. For example, in a key-value store, we can partition the key space using approaches like consistent hashing, then make each replica order the commands on one partition (commands on different keys can be out-of-order). Again, in this case, it would be possible to use the WPaxos approach for safe key-stealing among the sequencers, and dynamically adapt to the access pattern, rather than being confined to static partitioning.
Evaluation
They implemented a prototype of SDPaxos, and compared its performance with typical single-leader (Multi-Paxos) and multileader (Mencius, EPaxos) protocols. The experiment results demonstrate that SDPaxos achieves: (1) 1.6× the throughput of Mencius with a straggler, (2) stable performance under different contention degrees and 1.7× the throughput of EPaxos even with a low contention rate of 5%, (3) 6.1× the throughput of Multi-Paxos without straggler or contention, (4) 4.6× the throughput of writes when performing reads, and (5) up to 61% and 99% lower wide-area latency of writes and reads than other protocols.

MAD questions
1. Does SDPaxos help with the leader bottleneck significantly?I wrote above that "Provided that the ordering messages are smaller than the replication messages, the load on the sequencer will not be as severe as that on the single leader in Paxos." But on close inspection I don't think I believe that sentence anymore. Ailidani, Aleksey, and I have done a detailed bottleneck analysis of Paxos protocol categories (under submission), and we found that the outcast messages are not the biggest source of bottleneck for the leader, as they are serialized once before being sent out to the replicas. The incast messages contribute most to the bottleneck, as the CPU needs to process them one by one and they queue up. Moreover, the incast messages are ACK messages, which are already small, and SDPaxos does not make them smaller. So, maybe SDPaxos does not improve significantly on the single-leader bottleneck in Paxos. On the other hand, it is true that SDPaxos helps distribute the client request load to the C-instance replicas relieving that bottleneck, and it definitely helps with lowering the latency in WAN.
2. How would you build reconfiguration of participants for this protocol?
Reconfiguration of participants is important to re-establish fault-tolerance capability by replacing failed replicas by accepting fresh new replicas to the system. How would reconfiguration work for SDPaxos? Would Raft's 2-phase reconfiguration method apply readily for SDPaxos?
3. What are additional challenges for efficient strongly-consistent geo-replication implementation at scale?
I am at Microsoft Azure Cosmos DB for my sabbatical. Cosmos DB recently introduced general-availability of multiple write regions. While providing strong-consistency with multi-master writes allowed from any region has cost across the globe, could SDPaxos ideas help improve efficiency further?





Comments