Replicated Data Consistency Explained Through Baseball
I had mentioned this report in my first overview post about my sabbatical at Cosmos DB. This is a 2011 technical report by Doug Terry, who was working at Microsoft Research at the time. The paper explains the consistency models through publishing of baseball scores via multiple channels. (Don't worry, you don't have to know baseball rules or scoring to follow the example; the example works as well for publishing of, say, basketball scores.)
Many consistency models have been proposed for distributed and replicated systems. The reason for exploring different consistency models is that there are fundamental tradeoffs between consistency, performance, and availability.
While seeing the latest written value for an object is desirable and reasonable to provide within a datacenter, offering strong consistency for georeplicated services across continents results in lower performance and reduced availability for reads, writes, or both.
On the opposite end of the spectrum, with eventual consistency, the data returned by a read operation is the value of the object at some point in the past, yet the performance and availability dimensions are greatly improved.
The paper argues that eventual consistency is insufficient for most of the use cases, but strong consistency is not needed either; most use-cases benefit from some intermediate consistency guarantees.
This concurs with Cosmos DB production workloads. As I mentioned in my first overview post, about 73% of Cosmos DB tenants use session consistency and 20% prefer bounded staleness. This limits strong-consistency and eventual-consistency to the fringes. After I introduce the model and consistency guarantees the paper considers, I will talk about how these map to the consistency levels used in Cosmos DB.
The paper considers a simple abstract model for the data store. In this model, clients perform write operations to a master node in the data store. Writes are serialized and eventually performed/replicated in the same order (with that of the master) at all the servers (a.k.a. replicas). The client perform reads from the servers/replicas. Reads return the values of data objects that were previously written, though not necessarily the latest values. This is because the entire set of writes at the master may not yet be reflected in order and in entirety at the servers.
The 6 consistency guarantees below are defined by which set of previous writes are visible to a read operation.
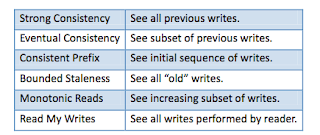
Strong consistency ensures that a read operation returns the value that was last written for a given object. In other words, a read observes the effects of all previously completed writes: if write operations can modify or extend portions of a data object, such as appending data to a log, then the read returns the result of applying all writes to that object. (Note that in order to achieve strong consistency in the presence of crashes, the write operation at the master should be going lockstep with a quorum of replicas to permanently record writes, requiring synchronous replication!)
Eventual consistency is the weakest of the guarantees, so it allows the greatest set of possible return values. Such a read can return results from a replica that has received an arbitrary subset of the writes to the data object being read.
By requesting a consistent prefix, a reader is guaranteed to observe an ordered sequence of writes starting with the first write to a data object. In other words, the reader sees a version of the data store that existed at the master at some time in the past.
Bounded staleness ensures that read results are not too stale. That is, the read operation is guaranteed to see at least all writes that completed d time (or number of updates) before the read started. The read may potentially see some more recently written values.
Monotonic Reads (sometimes also called as a session guarantee) is a property that applies to a sequence of read operations that are performed by a given client. It states that if the client issues a read operation and then later issues another read to the same object(s), the second read will return the same value(s) or the results of later writes.
Read My Writes is also a session property specific to a client. It guarantees that the effects of all writes that were performed by the client are visible to the client's subsequent reads. If a client writes a new value for a data object and then reads this object, the read will return the value that was last written by the client (or some other value that was later written by a different client).
None of these last four read guarantees are stronger than each other, thus applications may want to combine a multiple of these guarantees. For example, a client could request monotonic reads and read my writes so that it observes a data store that is consistent with its own actions.

The table shows the performance and availability typically associated with each consistency guarantee. Strong consistency is desirable from a consistency viewpoint but offers the worst performance and availability since it generally requires reading from a majority of replicas. Eventual consistency, on the other hand, allows clients to read from any replica, but offers the weakest consistency. The table illustrates the tradeoffs involved as each guarantee offers a unique combination of consistency, performance, and availability.

Cosmos DB allows developers to choose among 5 well-defined consistency models along the consistency spectrum. While the definitions of strong, eventual, and consistent prefix are the same as the ones discussed in the report, Cosmos DB strengthens the definitions for bounded staleness and session consistency, making them more useful for the clients.
More specifically, Cosmos DB's bounded staleness is strengthened to offer total global order except within the "staleness window". In addition, monotonic read guarantees exist within a region both inside and outside the "staleness window".
Cosmos DB's session consistency (again scoped to a client session) is strengthened to include consistent prefix, monotonic writes, read my writes, and write-follows-reads in addition to the monotonic read property. As such, it is ideal for all scenarios where a device or user session is involved. (You can check the clickable consistency map by Kyle Kingsburry to read about the definitions of monotonic writes and write-follows-reads which impose order on the writes.)
It is possible to sign up for a free trial (with no credit card and commitment) to test these guarantees on Cosmos DB. Once you create a Cosmos DB resource, you can also see an animation of the consistency guarantees after selecting the default consistency option from the tab. I am pasting screenshots for strong consistency and bounded staleness animations below.


While animations are nice for intuitively understanding consistency levels, inside Cosmos DB, the TLA+ specification language is used for specifying these models precisely and model checking them with the global distribution protocols considered. In the coming weeks, as I promised, I will try to sanitize and publish from a client-side perspective the TLA+ specifications for these consistency levels.
To put their money where their mouth is, Cosmos DB offers comprehensive 99.99% SLAs which guarantee throughput, consistency, availability, and latency for Cosmos DB database accounts scoped to a single Azure region configured with any of the five consistency levels, or database accounts spanning multiple regions, configured with any of the four relaxed consistency levels. Furthermore, independent of the choice of a consistency level, Cosmos DB offers a 99.999% SLA for read and write availability for database accounts spanning two or more regions. I will dedicate a separate blog post on SLAs in the coming weeks, as I start learning more about them.

This sequence of writes is from a hypothetical baseball game with the inning-by-inning line score, and the game is currently in the middle of the seventh inning, and the home team is winning 2-5.
Different read guarantees may result in clients reading different scores for this game that is in progress. The table below lists the complete set of scores that could be returned by reading the visitors and home scores with each of the 6 consistency guarantees. The visitors' score is listed first, and different possible return values are separated by comas.

A strong consistency read can only return one result, the current score. On the other hand, an eventual consistency read can return one of 18 possible scores, many of which are ones that were never the actual score. The consistent prefix property limits the result to scores that actually existed at some time. The results that can be returned by a bounded staleness read depend on the desired bound.
The paper considers 6 hypothetical participants querying the baseball database for scores: the scorekeeper, umpire, radio reporter, sportswriter, statistician, and the stat-watcher. The table lists the consistencies that these participant use. Of course, each participant would be okay with strong consistency, but, by relaxing the consistency requested for her reads, she will likely observe better performance and availability. Additionally, the storage system may be able to better balance the read workload across servers since it has more flexibility in selecting servers to answer weak consistency read requests.

The toy example is meant to illustrate that the desired consistency depends as much on who is reading the data as on the type of data. All of the 6 presented consistency guarantees are useful, because each guarantee appears at least once in the participant needs table. That is, different clients may want different consistencies even when accessing the same data.
Clients should be able to choose their desired consistency. The system cannot possibly predict or determine the consistency that is required by a given application or client. The preferred consistency often depends on how the data is being used. Moreover, knowledge of who writes data or when data was last written can sometimes allow clients to perform a relaxed consistency read, and obtain the associated benefits, while reading up-to-date data. This could be of practical significance since the inherent trade-offs between consistency, performance, and availability are tangible and may become more pronounced with the proliferation of georeplicated services. This suggests that cloud storage systems should at least consider offering a larger choice of read consistencies.
As I discussed above, Cosmos DB fits the bill. It provides 5 consistency level choices in an all-in-one packet. It is easy to configure the consistency level on the fly, and the effects take place quickly. Cosmos DB also allows you the flexibility to override the default consistency level you configured for your account on a specific read request. It turns out only about 2% of Cosmos DB tenants override consistency levels on a per request basis.
The paper said: "We assume that the score of the game is recorded in a key-value store in two objects, one for the number of runs scored by the visitors and one for the home team's runs."
Why keep two separate objects "home" "visitor" though? Instead, what if we used just one object called "score" that consists of a tuple <visitor, home>. Then the reads would be more consistent by design; even the eventual consistency read will not return a score that was not an actual store at one point in the game.
Sometimes you don't get to design the data storage/access schemes, but when you get to decide this, you can act smartly and improve consistency. This reminds me of techniques used in self-stabilizing systems for compacting the state space to forbid bad states by construction.
2. What are the theoretical limits on the tradeoffs among consistency levels?
As we have seen, each proposed consistency model occupies some point in the complex space of tradeoffs. The CAP theorem shows a coarse tradeoff between consistency and availability. The PACELC model tries to capture further tradeoffs between consistency, availability, and latency.
More progress has been made in exploring the tradeoff space from the theoretical perspective since then. The causal consistency result showed that natural causal consistency, a strengthening of causal consistency that respects the real-time ordering of operations, provides a tight bound on consistency semantics that can be enforced without compromising availability and convergence. There has been plethora of papers recently on improvements on causal consistency georeplicated datastores, and I hope to summarize the prominent ones in the coming weeks.
3. Is baseball scoring also nonlinear?
Baseball is still foreign to me, even though I have been in US for 20 years now. While I try to be open-minded and eager to try new things, I can be stubborn about not learning some things. Here is another example where I was unreasonably close minded. Actually, though I had seen this paper earlier, I didn't read it then because I thought I would have to learn about baseball rules to understand it. Funny? No! I wonder what other opportunities I miss because of being peculiarly close minded on certain things.
Well, to win a battle against my obstinate and peculiar ignorance on baseball, I just watched this 5 minute explanation of baseball rules. Turns out, it is not that complicated. Things never turn out as scary/complicated/bad as I make them to be in my mind.
I had written about how bowling scoring is nonlinear and consequences of that. Does baseball scoring also have a nonlinear return? It looks like you can get a lot of runs scored in a single inning. So maybe that counts as nonlinearity as it can change the game score quickly, at any inning.
Many consistency models have been proposed for distributed and replicated systems. The reason for exploring different consistency models is that there are fundamental tradeoffs between consistency, performance, and availability.
While seeing the latest written value for an object is desirable and reasonable to provide within a datacenter, offering strong consistency for georeplicated services across continents results in lower performance and reduced availability for reads, writes, or both.
On the opposite end of the spectrum, with eventual consistency, the data returned by a read operation is the value of the object at some point in the past, yet the performance and availability dimensions are greatly improved.
The paper argues that eventual consistency is insufficient for most of the use cases, but strong consistency is not needed either; most use-cases benefit from some intermediate consistency guarantees.
This concurs with Cosmos DB production workloads. As I mentioned in my first overview post, about 73% of Cosmos DB tenants use session consistency and 20% prefer bounded staleness. This limits strong-consistency and eventual-consistency to the fringes. After I introduce the model and consistency guarantees the paper considers, I will talk about how these map to the consistency levels used in Cosmos DB.
Read consistency guarantees
The paper considers 6 consistency guarantees. These are all examples of the read-write centric operation consistency we discussed in the "Many Faces of Consistency" paper.The paper considers a simple abstract model for the data store. In this model, clients perform write operations to a master node in the data store. Writes are serialized and eventually performed/replicated in the same order (with that of the master) at all the servers (a.k.a. replicas). The client perform reads from the servers/replicas. Reads return the values of data objects that were previously written, though not necessarily the latest values. This is because the entire set of writes at the master may not yet be reflected in order and in entirety at the servers.
The 6 consistency guarantees below are defined by which set of previous writes are visible to a read operation.

Strong consistency ensures that a read operation returns the value that was last written for a given object. In other words, a read observes the effects of all previously completed writes: if write operations can modify or extend portions of a data object, such as appending data to a log, then the read returns the result of applying all writes to that object. (Note that in order to achieve strong consistency in the presence of crashes, the write operation at the master should be going lockstep with a quorum of replicas to permanently record writes, requiring synchronous replication!)
Eventual consistency is the weakest of the guarantees, so it allows the greatest set of possible return values. Such a read can return results from a replica that has received an arbitrary subset of the writes to the data object being read.
By requesting a consistent prefix, a reader is guaranteed to observe an ordered sequence of writes starting with the first write to a data object. In other words, the reader sees a version of the data store that existed at the master at some time in the past.
Bounded staleness ensures that read results are not too stale. That is, the read operation is guaranteed to see at least all writes that completed d time (or number of updates) before the read started. The read may potentially see some more recently written values.
Monotonic Reads (sometimes also called as a session guarantee) is a property that applies to a sequence of read operations that are performed by a given client. It states that if the client issues a read operation and then later issues another read to the same object(s), the second read will return the same value(s) or the results of later writes.
Read My Writes is also a session property specific to a client. It guarantees that the effects of all writes that were performed by the client are visible to the client's subsequent reads. If a client writes a new value for a data object and then reads this object, the read will return the value that was last written by the client (or some other value that was later written by a different client).
None of these last four read guarantees are stronger than each other, thus applications may want to combine a multiple of these guarantees. For example, a client could request monotonic reads and read my writes so that it observes a data store that is consistent with its own actions.

The table shows the performance and availability typically associated with each consistency guarantee. Strong consistency is desirable from a consistency viewpoint but offers the worst performance and availability since it generally requires reading from a majority of replicas. Eventual consistency, on the other hand, allows clients to read from any replica, but offers the weakest consistency. The table illustrates the tradeoffs involved as each guarantee offers a unique combination of consistency, performance, and availability.
Cosmos DB consistency levels

Cosmos DB allows developers to choose among 5 well-defined consistency models along the consistency spectrum. While the definitions of strong, eventual, and consistent prefix are the same as the ones discussed in the report, Cosmos DB strengthens the definitions for bounded staleness and session consistency, making them more useful for the clients.
More specifically, Cosmos DB's bounded staleness is strengthened to offer total global order except within the "staleness window". In addition, monotonic read guarantees exist within a region both inside and outside the "staleness window".
Cosmos DB's session consistency (again scoped to a client session) is strengthened to include consistent prefix, monotonic writes, read my writes, and write-follows-reads in addition to the monotonic read property. As such, it is ideal for all scenarios where a device or user session is involved. (You can check the clickable consistency map by Kyle Kingsburry to read about the definitions of monotonic writes and write-follows-reads which impose order on the writes.)
It is possible to sign up for a free trial (with no credit card and commitment) to test these guarantees on Cosmos DB. Once you create a Cosmos DB resource, you can also see an animation of the consistency guarantees after selecting the default consistency option from the tab. I am pasting screenshots for strong consistency and bounded staleness animations below.


While animations are nice for intuitively understanding consistency levels, inside Cosmos DB, the TLA+ specification language is used for specifying these models precisely and model checking them with the global distribution protocols considered. In the coming weeks, as I promised, I will try to sanitize and publish from a client-side perspective the TLA+ specifications for these consistency levels.
To put their money where their mouth is, Cosmos DB offers comprehensive 99.99% SLAs which guarantee throughput, consistency, availability, and latency for Cosmos DB database accounts scoped to a single Azure region configured with any of the five consistency levels, or database accounts spanning multiple regions, configured with any of the four relaxed consistency levels. Furthermore, independent of the choice of a consistency level, Cosmos DB offers a 99.999% SLA for read and write availability for database accounts spanning two or more regions. I will dedicate a separate blog post on SLAs in the coming weeks, as I start learning more about them.
Baseball analogy
This toy example assumes that the score of the game is recorded in the key-value store in two objects, one for the number of runs scored by the "visitors" and one for the "home" team's runs. When a team scores a run, a read operation is performed on its current score, the returned value is incremented by one, and the new value is written back to the key-value store.
This sequence of writes is from a hypothetical baseball game with the inning-by-inning line score, and the game is currently in the middle of the seventh inning, and the home team is winning 2-5.
Different read guarantees may result in clients reading different scores for this game that is in progress. The table below lists the complete set of scores that could be returned by reading the visitors and home scores with each of the 6 consistency guarantees. The visitors' score is listed first, and different possible return values are separated by comas.

A strong consistency read can only return one result, the current score. On the other hand, an eventual consistency read can return one of 18 possible scores, many of which are ones that were never the actual score. The consistent prefix property limits the result to scores that actually existed at some time. The results that can be returned by a bounded staleness read depend on the desired bound.
The paper considers 6 hypothetical participants querying the baseball database for scores: the scorekeeper, umpire, radio reporter, sportswriter, statistician, and the stat-watcher. The table lists the consistencies that these participant use. Of course, each participant would be okay with strong consistency, but, by relaxing the consistency requested for her reads, she will likely observe better performance and availability. Additionally, the storage system may be able to better balance the read workload across servers since it has more flexibility in selecting servers to answer weak consistency read requests.

The toy example is meant to illustrate that the desired consistency depends as much on who is reading the data as on the type of data. All of the 6 presented consistency guarantees are useful, because each guarantee appears at least once in the participant needs table. That is, different clients may want different consistencies even when accessing the same data.
Discussion
The report (here is the talk by Doug Terry on the report if you like to get a more immersive/extensive discussion of the topic) concludes as follows:Clients should be able to choose their desired consistency. The system cannot possibly predict or determine the consistency that is required by a given application or client. The preferred consistency often depends on how the data is being used. Moreover, knowledge of who writes data or when data was last written can sometimes allow clients to perform a relaxed consistency read, and obtain the associated benefits, while reading up-to-date data. This could be of practical significance since the inherent trade-offs between consistency, performance, and availability are tangible and may become more pronounced with the proliferation of georeplicated services. This suggests that cloud storage systems should at least consider offering a larger choice of read consistencies.
As I discussed above, Cosmos DB fits the bill. It provides 5 consistency level choices in an all-in-one packet. It is easy to configure the consistency level on the fly, and the effects take place quickly. Cosmos DB also allows you the flexibility to override the default consistency level you configured for your account on a specific read request. It turns out only about 2% of Cosmos DB tenants override consistency levels on a per request basis.
MAD questions
1. What are the effects of granularity of writes on consistency?The paper said: "We assume that the score of the game is recorded in a key-value store in two objects, one for the number of runs scored by the visitors and one for the home team's runs."
Why keep two separate objects "home" "visitor" though? Instead, what if we used just one object called "score" that consists of a tuple <visitor, home>. Then the reads would be more consistent by design; even the eventual consistency read will not return a score that was not an actual store at one point in the game.
Sometimes you don't get to design the data storage/access schemes, but when you get to decide this, you can act smartly and improve consistency. This reminds me of techniques used in self-stabilizing systems for compacting the state space to forbid bad states by construction.
2. What are the theoretical limits on the tradeoffs among consistency levels?
As we have seen, each proposed consistency model occupies some point in the complex space of tradeoffs. The CAP theorem shows a coarse tradeoff between consistency and availability. The PACELC model tries to capture further tradeoffs between consistency, availability, and latency.
More progress has been made in exploring the tradeoff space from the theoretical perspective since then. The causal consistency result showed that natural causal consistency, a strengthening of causal consistency that respects the real-time ordering of operations, provides a tight bound on consistency semantics that can be enforced without compromising availability and convergence. There has been plethora of papers recently on improvements on causal consistency georeplicated datastores, and I hope to summarize the prominent ones in the coming weeks.
3. Is baseball scoring also nonlinear?
Baseball is still foreign to me, even though I have been in US for 20 years now. While I try to be open-minded and eager to try new things, I can be stubborn about not learning some things. Here is another example where I was unreasonably close minded. Actually, though I had seen this paper earlier, I didn't read it then because I thought I would have to learn about baseball rules to understand it. Funny? No! I wonder what other opportunities I miss because of being peculiarly close minded on certain things.
Well, to win a battle against my obstinate and peculiar ignorance on baseball, I just watched this 5 minute explanation of baseball rules. Turns out, it is not that complicated. Things never turn out as scary/complicated/bad as I make them to be in my mind.
I had written about how bowling scoring is nonlinear and consequences of that. Does baseball scoring also have a nonlinear return? It looks like you can get a lot of runs scored in a single inning. So maybe that counts as nonlinearity as it can change the game score quickly, at any inning.






Comments