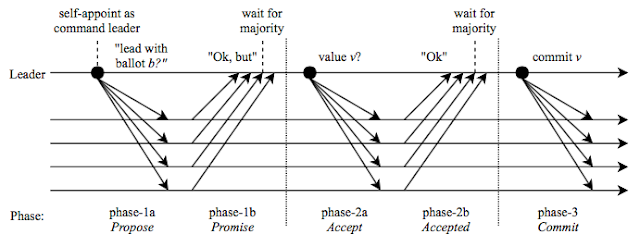
Two-phase commit and beyond

In this post, we model and explore the two-phase commit protocol using TLA+. The two-phase commit protocol is practical and is used in many distributed systems today. Yet it is still brief enough that we can model it quickly, and learn a lot from modeling it. In fact, we see that through this example we get to illustrate a fundamental impossibility result in distributed systems directly. The two-phase commit problem A transaction is performed over resource managers (RMs). All RMs must agree on whether the transaction is committed or aborted . The transaction manager (TM) finalizes the transaction with a commit or abort decision. For the transaction to be committed, each participating RM must be prepared to commit it. Otherwise, the transaction must be aborted. Some notes about modeling We perform this modeling in the shared memory model, rather than in message passing, to keep things simple. This also ensures that the model checking is fast. But we add no...