WPaxos: a wide area network Paxos protocol (Part 1)
Paxos is great for solving the fault-tolerant coordination problem in a datacenter. But for cross datacenter coordination (which is needed for distributed databases, filesystems, configuration management, etc.), it hits the WAN latency barrier. The multi-decree Paxos (Multi-Paxos) algorithm, implemented in variants like Raft and Zab, relies on electing a distinguished leader to serialize updates and hence cannot deal with write-intensive scenarios across the wide area networks (WAN).
An alternative is the leaderless Paxos algorithms. Generalized Paxos and EPaxos employ opportunistic leaders for non-interfering commands and are able to reduce 3 message delays to 2, and allow concurrent leaders to commit. But the fast agreement incurs the cost of a much larger quorum named fast-quorum (3/4ths of the nodes) and hits the WAN latency barrier as well.
Another alternative (as employed in Google Spanner) is to use multiple Paxos groups with partitioned data/object space. In order to provide flexibility/versatility, this partitioned approach employs an external service to manage configuration and move data/objects across groups.
Recently we introduced another alternative with our WPaxos work. WPaxos is a simple and pure Paxos protocol that provides flexible, performant, and fault-tolerant coordination over the WAN. WPaxos is lean and obviates the need for another service/protocol for data/object relocation. Since WPaxos provides the same Paxos safety guarantees to the face of concurrency, asynchrony, and faults, its performance can be tuned orthogonally and aggressively by tuning a couple parameters. In this post, jointly written with Ailidani Ailijiang and Aleksey Charapko, we give an overview of WPaxos. For details and performance evaluation, we refer you to our paper.
Our insight is to notice that if we deploy each column in one of the geo-distributed regions/zones, we can achieve a really fast Paxos phase-2 since the Q2 quorum is within the same LAN. Note that, when failures and leader changes are rare, the phase-2 (where the leader tells the acceptors to decide values) occurs much more frequent than phase-1 (where a new leader is elected). So it makes sense to improve the performance by reducing Q2 latency at the expense of making the infrequently used Q1 slower.
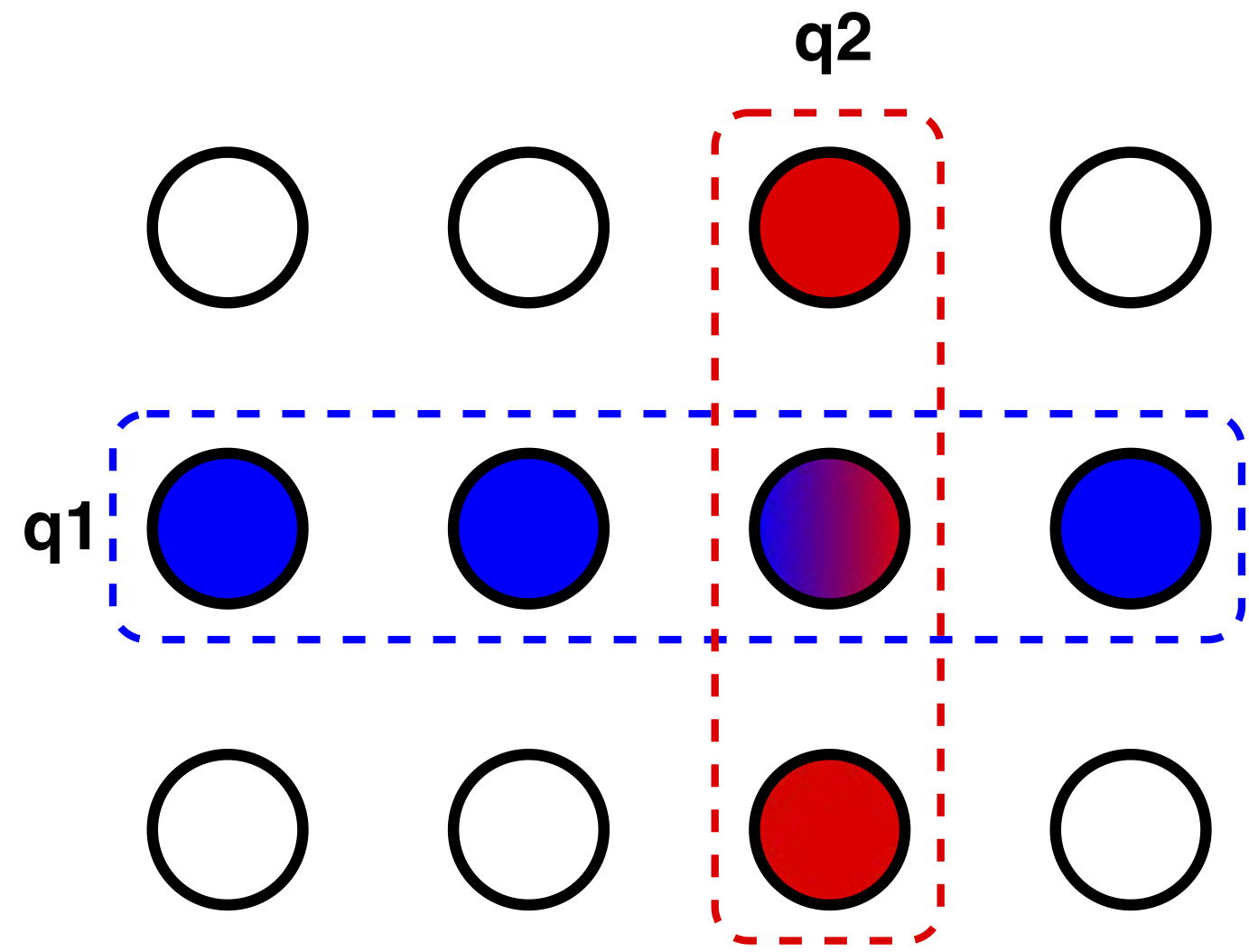
Before going further with describing the protocol, let's elaborate on why the grid-shaped deployment is safe for using in Paxos. In majority quorums, any 2 phase-1 quorums intersect, which means 2 nodes cannot be elected as a leader for the same ballot. However, this is not necessary! In the grid quorum, node i can be elected as leader by the first row for some ballot b, while node j is elected by the second row for a b'>b. In order to make a decision, Node i has to start phase-2 and satisfy a phase-2 (column) quorum. Since the Q2 always include one node from the second row, that node rejects node i's phase-2 message, preventing any conflicting decisions to be made by i and j.
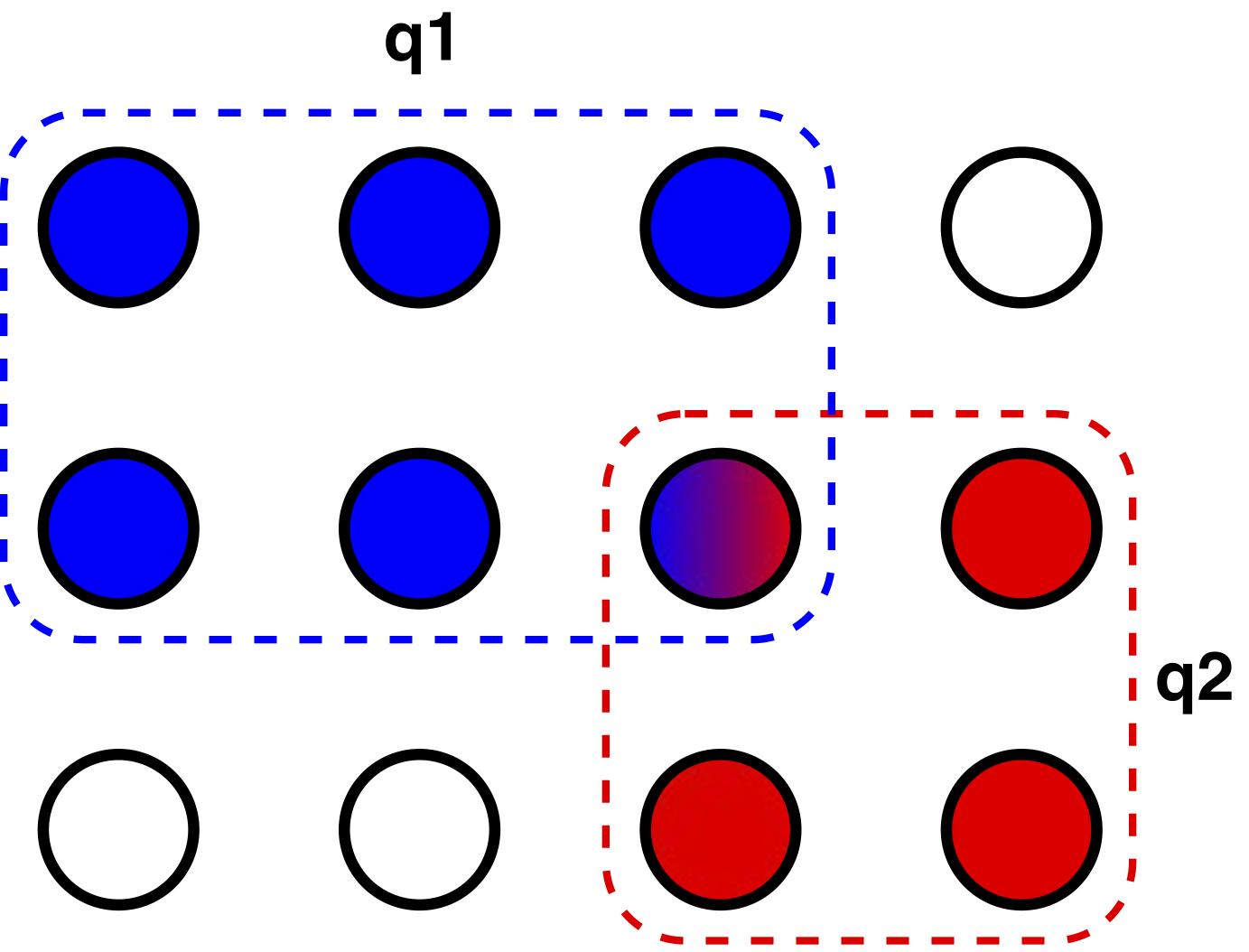
Unfortunately, this grid quorum deployment cannot tolerate a single zone failure. The WPaxos default quorum derives from the grid quorum layout, and picks f+1 (majority) nodes in a zone of 2f+1 nodes to tolerate f node failures. In addition, to tolerate F zone failures within Z zones, Q1 is selected from Z-F zones and Q2 from F+1 zones. For example, in the following figure of 12 nodes, while a majority quorum may tolerate 5 failures, the WPaxos default quorum can tolerate one row plus one column, in total of 6 failures.
Here is a TLA+ specification for the Q1 and Q2 quorum systems used in WPaxos. Q1 and Q2 columns do not need to be rigid rows and columns; the first responding node set that satisfy a Q1 or Q2 definition suffice.

To mitigate the dueling leaders problem, where two nodes constantly propose a higher ballot number than the opponent, each object gets its own commit log with separate ballot and slot numbers. This also means that WPaxos provides per-object linearizability.
The locality adaptive object stealing optimization moderates the trigger-happy object stealing in WPaxos based on a migration policy. The intuition behind the policy is to move objects to a zone where the clients will benefit the most, since moving objects frequently is expensive. By using an invited-stealing approach, the permission to steal is handed to the zone that has the most requests for the objects in some period of time.
The replication set optimization allows a configurable replication factor where a subset of Q2 quorum is selected to send phase-2 messages, instead of broadcasting to entire system. The size of replication set ranges from F+1 zones up to the total number of Z zones. This provides a trade-off between communication overhead and a more predictable latency, since the replication zone may not always be the fastest to reply.
Transactions can be implemented on top of WPaxos entirely within the protocol, and avoids the need for integrating an extra 2-phase-commit service. The node that initiates a transaction operation, first steals all objects needed for that transaction via multiple Q1 accesses. This is done in increasing order of the objects IDs to avoid deadlock and livelock. Then the node commits the transaction in phase-2 in seperate object logs, and collating/serializing the logs together by comparing the slot number of common objects in the transactions. (We have not implemented transactions in WPaxos yet!)
Dynamic reconfiguration is achieved similar to Raft in two steps, where current configuration C = <Q1, Q2>, the new configuration C’ = <Q1’, Q2’>. First, a union of both old and new configuration C+C’ is proposed and committed by the quorums combined. Then the leader may propose the new config C’ and activate after commit in Q2’. WPaxos further reduces the two steps into one in special cases where the reconfiguration operation is limited to add/remove one row or column at a time.
We also implemented WPaxos in Go to evaluate its performance. Please give it a whirl, and let us know what you think.
An alternative is the leaderless Paxos algorithms. Generalized Paxos and EPaxos employ opportunistic leaders for non-interfering commands and are able to reduce 3 message delays to 2, and allow concurrent leaders to commit. But the fast agreement incurs the cost of a much larger quorum named fast-quorum (3/4ths of the nodes) and hits the WAN latency barrier as well.
Another alternative (as employed in Google Spanner) is to use multiple Paxos groups with partitioned data/object space. In order to provide flexibility/versatility, this partitioned approach employs an external service to manage configuration and move data/objects across groups.
Recently we introduced another alternative with our WPaxos work. WPaxos is a simple and pure Paxos protocol that provides flexible, performant, and fault-tolerant coordination over the WAN. WPaxos is lean and obviates the need for another service/protocol for data/object relocation. Since WPaxos provides the same Paxos safety guarantees to the face of concurrency, asynchrony, and faults, its performance can be tuned orthogonally and aggressively by tuning a couple parameters. In this post, jointly written with Ailidani Ailijiang and Aleksey Charapko, we give an overview of WPaxos. For details and performance evaluation, we refer you to our paper.
Flexible flexible quorums
WPaxos leverages on the flexible quorum idea that weaken the "all quorums should intersect" assertion in Paxos to instead "quorums from different phases should intersect". That means, it is possible to use any phase-1 quorum (Q1) that intersect with any phase-2 quorum (Q2), instead of using majority quorums. A clever instantiation of this is the grid quorum system. Let Q1 be a row in the grid, and Q2 be a column. Since any row and column always intersects at one node, any $q1 \in Q1$ is guaranteed to intersect with any $q2 \in Q2$.Our insight is to notice that if we deploy each column in one of the geo-distributed regions/zones, we can achieve a really fast Paxos phase-2 since the Q2 quorum is within the same LAN. Note that, when failures and leader changes are rare, the phase-2 (where the leader tells the acceptors to decide values) occurs much more frequent than phase-1 (where a new leader is elected). So it makes sense to improve the performance by reducing Q2 latency at the expense of making the infrequently used Q1 slower.
Before going further with describing the protocol, let's elaborate on why the grid-shaped deployment is safe for using in Paxos. In majority quorums, any 2 phase-1 quorums intersect, which means 2 nodes cannot be elected as a leader for the same ballot. However, this is not necessary! In the grid quorum, node i can be elected as leader by the first row for some ballot b, while node j is elected by the second row for a b'>b. In order to make a decision, Node i has to start phase-2 and satisfy a phase-2 (column) quorum. Since the Q2 always include one node from the second row, that node rejects node i's phase-2 message, preventing any conflicting decisions to be made by i and j.
Unfortunately, this grid quorum deployment cannot tolerate a single zone failure. The WPaxos default quorum derives from the grid quorum layout, and picks f+1 (majority) nodes in a zone of 2f+1 nodes to tolerate f node failures. In addition, to tolerate F zone failures within Z zones, Q1 is selected from Z-F zones and Q2 from F+1 zones. For example, in the following figure of 12 nodes, while a majority quorum may tolerate 5 failures, the WPaxos default quorum can tolerate one row plus one column, in total of 6 failures.
Here is a TLA+ specification for the Q1 and Q2 quorum systems used in WPaxos. Q1 and Q2 columns do not need to be rigid rows and columns; the first responding node set that satisfy a Q1 or Q2 definition suffice.

The multi-leader federation
WPaxos uses multiple leader nodes to concurrently serve a set of objects in the system. The nodes may steal leadership of objects from each other using phase-1 of Paxos executed over a Q1 quorum. Then the node commits the updates to those objects over its corresponding Q2 quorums, and can execute phase-2 multiple times until another node steals those objects.To mitigate the dueling leaders problem, where two nodes constantly propose a higher ballot number than the opponent, each object gets its own commit log with separate ballot and slot numbers. This also means that WPaxos provides per-object linearizability.
Extensions
Since the basic WPaxos is a simple and pure flavor of Paxos, it enjoys its safety guarantees. Since the basic WPaxos is also very flexible and offers knobs for tunability, we can extend the protocol to improve its performance easily.The locality adaptive object stealing optimization moderates the trigger-happy object stealing in WPaxos based on a migration policy. The intuition behind the policy is to move objects to a zone where the clients will benefit the most, since moving objects frequently is expensive. By using an invited-stealing approach, the permission to steal is handed to the zone that has the most requests for the objects in some period of time.
The replication set optimization allows a configurable replication factor where a subset of Q2 quorum is selected to send phase-2 messages, instead of broadcasting to entire system. The size of replication set ranges from F+1 zones up to the total number of Z zones. This provides a trade-off between communication overhead and a more predictable latency, since the replication zone may not always be the fastest to reply.
Transactions can be implemented on top of WPaxos entirely within the protocol, and avoids the need for integrating an extra 2-phase-commit service. The node that initiates a transaction operation, first steals all objects needed for that transaction via multiple Q1 accesses. This is done in increasing order of the objects IDs to avoid deadlock and livelock. Then the node commits the transaction in phase-2 in seperate object logs, and collating/serializing the logs together by comparing the slot number of common objects in the transactions. (We have not implemented transactions in WPaxos yet!)
Dynamic reconfiguration is achieved similar to Raft in two steps, where current configuration C = <Q1, Q2>, the new configuration C’ = <Q1’, Q2’>. First, a union of both old and new configuration C+C’ is proposed and committed by the quorums combined. Then the leader may propose the new config C’ and activate after commit in Q2’. WPaxos further reduces the two steps into one in special cases where the reconfiguration operation is limited to add/remove one row or column at a time.
Give this a Go
We model checked our WPaxos specification in TLA+/PlusCal to verify its consistency properties.We also implemented WPaxos in Go to evaluate its performance. Please give it a whirl, and let us know what you think.





Comments
where is the second part? I can't waiting to know the second part.