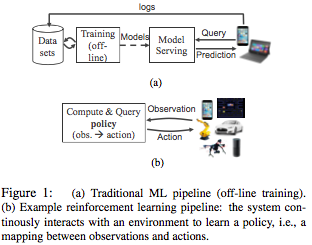
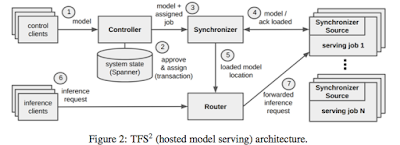
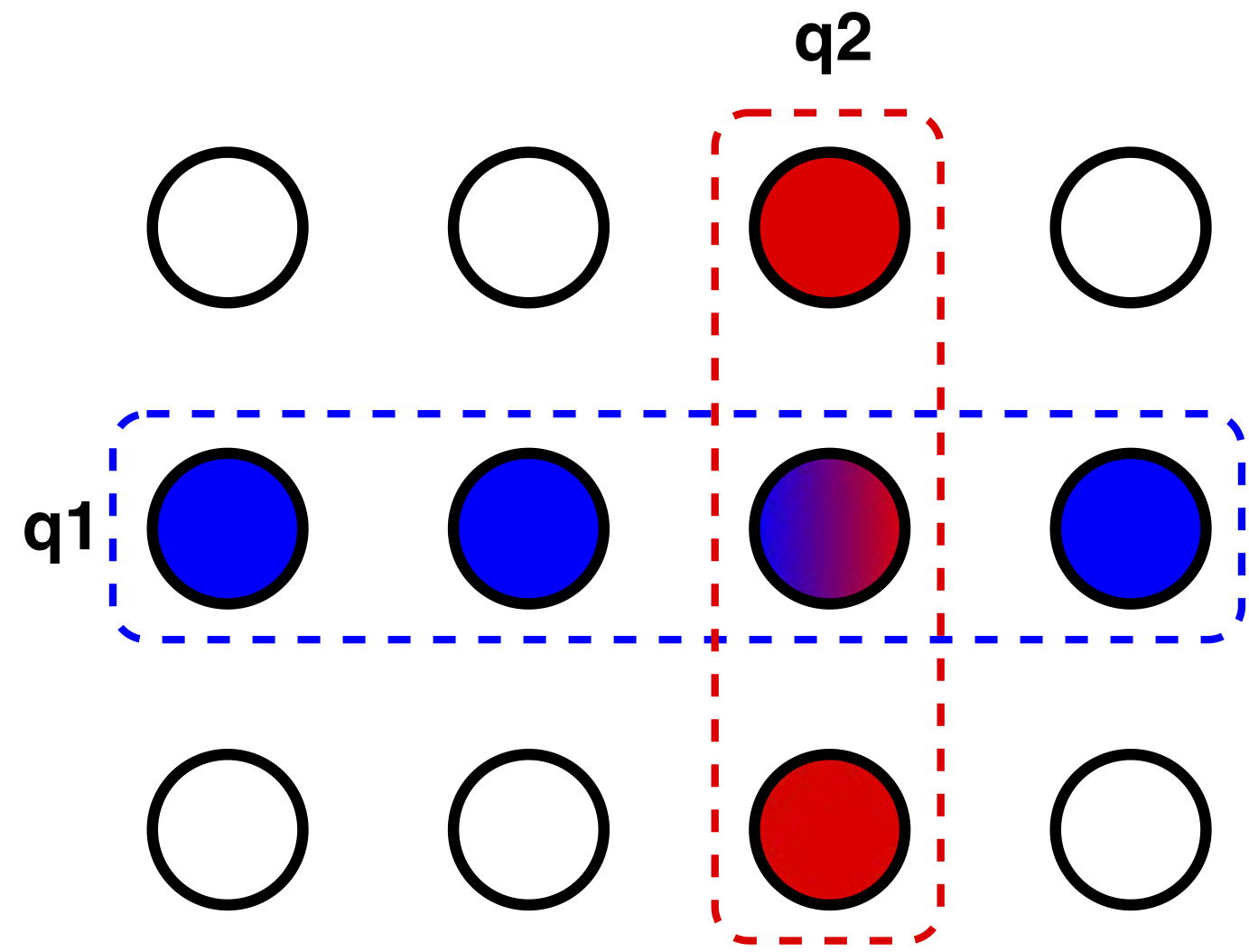
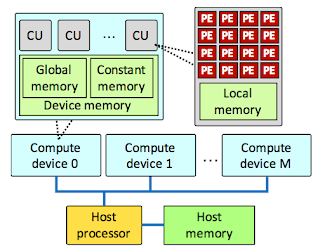
Best of 2017 in MuratBuffalo
This is my 77th post for the year. As is the custom in a year-end post , I mention some highlights among these posts in 2017. Machine Learning My first impressions after a week of using TensorFlow Google DistBelief paper: Large Scale Distributed Deep Networks Learning Machine Learning: Deep Neural Networks Google Federated Learning DeepXplore, Automated Whitebox Testing of Deep Learning Systems Dynet: The Dynamic Neural Network Toolkit A Comparison of Distributed Machine Learning Platforms The Case for Learned Index Structures Cloud Computing and Big Data Analytics Occupy the Cloud: Distributed Computing for the 99% Cloud fault-tolerance Mesos: A platform for fine-grained resource sharing in the data center Retroscope: Retrospective cut-monitoring of distributed systems (part 3) Making sense of Performance in Data Analytics Frameworks Performance clarity as a first-class design principle On dataflow systems, Naiad and Tensorflow Distributed Coordination ...